I’m running out of memory when running the second part of the feature training on an 8GB 1070:

Does anyone know any way to alter the parameters to lower the memory needed, like chunk, etc?
I’m running out of memory when running the second part of the feature training on an 8GB 1070:
Does anyone know any way to alter the parameters to lower the memory needed, like chunk, etc?
The ‘chuck’ you are referring to is batch size,
md = ColumnarModelData.from_data_frame(PATH, val_idx, df, yl.astype(np.float32), cat_flds=cat_vars, bs=64, test_df=df_test)
Try lowering the batch size, bs to 64
how could i use an existing pretrained model (e.g pretrianed on wikipedia) and load its encoder layer to fastai for classification as shown in lesson 4 without training the languege model from scratch?
This is a fascinating vid on using embeddings in images. Waymo does this every thing, and spoke about it at the online Self-Driving course at MIT: https://youtu.be/LSX3qdy0dFg?t=40m49s
I was pretty excited to be able to understand what he was saying based on what I know from this course!
Does anyone have the links to the Pinterest video and Instacart article Jeremy mentions in this lesson?
I’m running the code in the lesson3-rossman notebook as is, and am getting NaN values for two of the derived features: ‘AfterStateHoliday’ and ‘BeforeStateHoliday’. I first got this error on GCE, where I run the code for the course, then reproduced the error with a fresh install of the fastai library. This is causing the notebook to crash, and if I toss the features the performance of the model is worse than the benchmark for kaggle (taking the median for the day of the week). Has anyone else run infto something similar? Is there a copy of the transformed data I can use so I can focus on modeling?
Hi,
I’m getting Parameter format not correct - "clImdb". error in lesson4-imdb when I run %ls {PATH} on Win10. Should I look for replacement of all Unix commands like ls and xargs cat for win analogs?
Thanks
upd. I have Ubuntu from Microsoft Store. I remember Jeremy running it on local machine to launch remote links from Paperspace or AWS. Is it possible to do similar trick with Windows being host for Jupyter notebook?
Error: Can't find model 'en'
SOLUTION =>
python -m spacy download en
AttributeError: module 'msgpack._unpacker' has no attribute 'unpack'
SOLUTION =>
conda install msgpack-python=0.5.1
Hi, I have a question in Rossman part of this lesson. In the last step in the jupyter notebook, I see that there’re 2 attempts to fit the model. The first attempt is in the “Sample” section got the rmspe around 0.19 after the first epoch.
m = md.get_learner(emb_szs, len(df.columns)-len(cat_vars),
0.04, 1, [1000,500], [0.001,0.01], y_range=y_range)
lr = 1e-3
m.fit(lr, 3, metrics=[exp_rmspe])
[ 0. 0.02479 0.02205 0.19309]
[ 1. 0.02044 0.01751 0.18301]
[ 2. 0.01598 0.01571 0.17248]
then after that, in “All” section, the similar code is run again but the rmspe is much lower as you see it around 0.11.
m = md.get_learner(emb_szs, len(df.columns)-len(cat_vars),
0.04, 1, [1000,500], [0.001,0.01], y_range=y_range)
lr = 1e-3
m.fit(lr, 1, metrics=[exp_rmspe])
[ 0. 0.01456 0.01544 0.1148 ]
So I just wondering if this is because the model continues to train after the Sample section but m variable is reassigned in the All section then it couldn’t happen or it just because that model just has better random number so it fits the data better after the first epoch of training.
Thank you.
Hi Jeremy, Rachel,
Many thanks for this lesson that is very relevant to anyone working in data science in the industry. Working routinely with multi-GB dataframes, I have been comparing many options to save Pandas dataframes. I see in your example that you are using feather which saves the dataframe in an in-memory state. This is quick but consumes a lot of disk space.
I am now using mainly PyArrow to save pandas dataframes directly to a highly compressed parquet format. Bonus: it is even faster to write/read than the in-memory format. Example below:
import pyarrow as pa
import pyarrow.parquet as pq
table = pa.Table.from_pandas(joined)
pq.write_table(table, f'{PATH}joined.parquet')
table_test = pa.Table.from_pandas(joined_test)
pq.write_table(table_test, f'{PATH}joined_test.parquet')
Results:
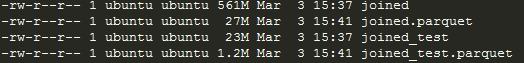
The same files occupies more than 20x less space.
Write time for both dataframes on P2 instance: 3s vs 9s for feather
Read test:
Hope this helps!
Guillaume
I too faced the same issue. Please see my response here: ['AfterStateHoliday']: Input contains NaN, infinity or a value too large for dtype('float32') and let me know if this helps.
Guillaume
I think basically everything between
df = train[columns]
df = test[columns]
and
joined = join_df(joined, df, ['Store', 'Date'])
joined_test = join_df(joined_test, df, ['Store', 'Date'])
are supposed to run twice, one for training and one for testing dataset. Hence what I did was:
Remember to make sure df has 844338 rows for train and 41088 rows for test before you join it with joined and joined_test respectively.
Hey everyone! Apologies in advance if this question was asked earlier or generally discussed, feel free to link me to the discussion if it was!
These might be a little more in the domain of the machine learning course…but I was hoping someone could shed a little light on the following re: setting up the features for rossman:
Why are variables like ‘AfterStateHoliday’, ‘BeforeStateHoliday’, ‘Promo’, ‘SchoolHoliday’ in the continuous variable list? Wouldn’t they be more suited for the categorical list? I guess the after and before state holidays are a little more continuous in nature…but maybe they could be similarly maxed out like the months since competition open (max = 24), which is a categorical variable.
We devised some transformations on existing features, such as before and after holidays, and before and after promos. Does retaining the original features (holiday, promo) enhance the resulting model and if so, why? I would have thought these newer engineered features contain even more information than the originals, and consequently we could drop the original holiday and promo columns?
Thanks!
Hi everyone,
I were training my Sentiment model based on a pre-trained model with not that high accuracy (4.2508664). After the block
m3.freeze_to(-1)
m3.fit(lrs/2, 1, metrics=[accuracy]) # train the final layer
m3.unfreeze()
m3.fit(lrs, 1, metrics=[accuracy], cycle_len=1)
I see
epoch trn_loss val_loss accuracy
0 1.092117 1.025311 0.485915
epoch trn_loss val_loss accuracy
0 0.494757 0.393013 0.913172
It seemed going well. But after two cycles of restart, the accuracy went low again. I guess it jumped out of a narrow sweet spot.
epoch trn_loss val_loss accuracy
0 0.465001 0.3577 0.918454 ok
1 0.427471 0.326164 0.921135 ok
2 0.435863 0.341614 0.918734 ok
3 0.421462 0.329268 0.921855 ok
4 0.648535 0.504928 0.881362
5 0.65179 0.53642 0.887404
6 0.846718 0.830428 0.666973
7 0.901057 0.944498 0.557698
8 1.019339 0.985083 0.568662
9 1.033611 1.002059 0.517165
10 1.006995 1.367595 0.108635
11 1.008204 1.259699 0.178577
12 1.003845 1.113971 0.497519
13 0.999826 0.856634 0.660131
How should I obtain a good model in this case then? Should I stop restarting after two cycles? Thanks in advance.
Hello everyone,
I have a question concerning some of the created features of the dataset. More specifically AfterSchoolHoliday, BeforeSchoolHoliday, AfterStateHoliday, and BeforeStateHoliday. I know that this is more on the ML side than the DL side, but I still feel that this thread is the right place to ask it.
I have the impression that some of the values computed in this columns do not make sense, and are just a kind of numerical upper bound. Since we are dealing with durations in days, the values should not exceed a couple of thousands. But we have this value
-9223372036854775808
appearing everywhere (see the output of the cell 68 on the github page of the course:
)
I may have missed a part where we truncate these variables (maybe it is done automatically somewhere) but if we only standardize these variables, then all the meaningful values will be sent to 0, and the variables will loose their meaning.
I apologize if I missed something, and if it is the case I would be glad to know where this issue is dealt with.
Best
This is an error. Nan as a float, is not representable as an integer. Here is the issue on github, which should be fixed. If you update the notebook, and follow along, it should work. If not, post about it here: https://github.com/fastai/fastai/issues/201
I haven’t watched the Pinterest videos yet, but I found these, on O’Reilly’s (paid) website:
How Pinterest uses machine learning to achieve ~200M monthly active users - Yunsong Guo (Pinterest) (28:40 mins)
Pinterest has always prioritized user experiences. Yunsong Guo explores how Pinterest uses machine learning—particularly linear, GBDT, and deep NN models—in its most important product, the home feed, to improve user engagement. Along the way, Yunsong shares how Pinterest drastically increased its international user engagement along with lessons on finding the most impactful features.
Escaping the forest, falling into the net: The winding path of Pinterest’s migration from GBDT to neural nets - Xiaofang Chen (Pinterest), Derek Cheng (Pinterest) (40:16 mins)
Pinterest’s power is grounded in its personalization systems. Over the years, these recommender systems have evolved through different types of models. Xiaofang Chen and Derek Cheng explore Pinterest’s recent transition from a GBDT system to one based in neural networks powered by TensorFlow, covering the challenges and solutions to providing recommendations to over 160M monthly active users.
They are many more videos on the Safari’s website. But I was allowed to post only two links.
Overfitting vs. Underfitting, an example
training, validation, accuracy
0.3, 0.2, 0.92 = under fitting
0.2, 0.3, 0.92 = over fitting
I think under fitting is more like this
training, validation, accuracy
0.6 0.3 0.84
0.5 0.3 0.84
0.4 0.2 0.84
0.3 0.1 0.84
0.2 0.01 0.84
and overfitting is more like this
training, validation, accuracy
0.6 0.5 0.92
0.5 0.44 0.92
0.4 0.4 0.92
0.3 0.45 0.89
0.2 0.5 0.85
What you think
The NLP notebooks links are broken.
Hi. I’m still a little confused as to why embeddings give neural networks a chance to learn richer representations compared to the regular one hot encoding method. How does this array of numbers to represent some categorical variable actually help here?
Also, in the lecture, I think @jeremy mentions that the number of columns to have in our lookup table is roughly max(50, c//2). What’s the intuition behind this?
