Note that the changes outlined here: Change to how TTA() works affect this notebook.
I found changing
probs = np.mean(np.exp(log_preds),0)
to
probs = np.exp(log_preds)
fixed this. It would be great if someone could verify this is correct.
Note that the changes outlined here: Change to how TTA() works affect this notebook.
I found changing
probs = np.mean(np.exp(log_preds),0)
to
probs = np.exp(log_preds)
fixed this. It would be great if someone could verify this is correct.
@nickl looks like someone already made the update. maybe just needed to do a git pull of fastai repo?
Hi,
I m playing with learning rate & sz. When I keep sz=300, it displays some iteration data and it doesn’t appear If I keep sz=224.
It might happen because that might be the default sz of the images??
And when you change them, re scaling is done…
Hope I am correct…
I’m not seeing much difference with the results of all the tweaks - am I doing something wrong, or is the basic configuration already pretty good?
learn = ConvLearner.pretrained(arch, data, precompute=True)
learn.fit(0.01, 3)
[ 0. 0.04593 0.02452 0.99219]
[ 1. 0.03632 0.0258 0.99072]
[ 2. 0.03735 0.02532 0.9917 ]
learn.fit(1e-2, 3, cycle_len=1)
[ 0. 0.0551 0.02586 0.9917 ]
[ 1. 0.04168 0.02625 0.99023]
[ 2. 0.04431 0.02597 0.99121]
learn.unfreeze()
lr=np.array([1e-4,1e-3,1e-2])
learn.fit(lr, 3, cycle_len=1, cycle_mult=2)
[ 0. 0.04332 0.02481 0.98975]
[ 1. 0.04008 0.02324 0.99268]
[ 2. 0.03363 0.02141 0.99316]
[ 3. 0.03325 0.02021 0.99121]
[ 4. 0.02273 0.0233 0.99072]
[ 5. 0.02452 0.02243 0.99268]
[ 6. 0.0247 0.02174 0.9917 ]
log_preds,y = learn.TTA()
probs = np.mean(np.exp(log_preds),0)
accuracy(probs, y)
0.99150000000000050When we move a tensor to the GPU with .cuda() you can set the destination (which GPU) by simply passing an integer. To use the first GPU, we should use .cuda(0). The same can be done with everything else CUDA related…
It’s from the tutorials on Pytorch
Thanks…
@reshama I’m not seeing that update.
Are you looking at https://github.com/fastai/fastai/blob/master/courses/dl1/lesson1.ipynb?
I see the last change on December 31.
I see this commit https://github.com/fastai/fastai/commit/9087b22644524dc240287367d466fc2fa4bf4ac5#diff-4ca94011d5fcdd1db01a5c93ee9e189e for November 30, which fixes lesson2-image_models.ipynb and cifar10.ipynb
In lesson 1 I still see this:
Regarding 3. - your learning rate schedule which still doesn’t work.
Both plot_lr() and plot(), are using the samples from the training dataset.
So this means that for plot_lr() you will have number_of_iterations = training_dataset_size / batch_size = 150/15 = 10. When I read your first graph I can see that you only have 5-6 iterations. You can double check the sizes by printing these print(learn.data.bs) and print(len(learn.data.trn_y))
In case of plot() method, you want to plot the learning rate against the loss. The two variables have the same length equal to the number_of_iterations. But the plot() methods cuts by default the first 10 values and the last 5 values. So if you want to use the function as it is, you will need at least 17 iterations in order to plot a 2 points line. Or you can call the function specifying to start from 0 learn.sched.plot(n_skip=0) but you will still need a minimum of 7 iterations.
Probably the best/easier would be to decrease the batch size in order to be able to display these graphs.
It’s like history being rewritten…
Thanks …
It prevented me to create another thread…
try: !rm -r {PATH}train/.ipynb_checkpoints
also do this for valid.
Hi guys,how do i resolve this issue? The directory exists, just that there is supposed to be a slash in between Fastaipics and valid, which looks something like Fastaipics/valid… Thanks!
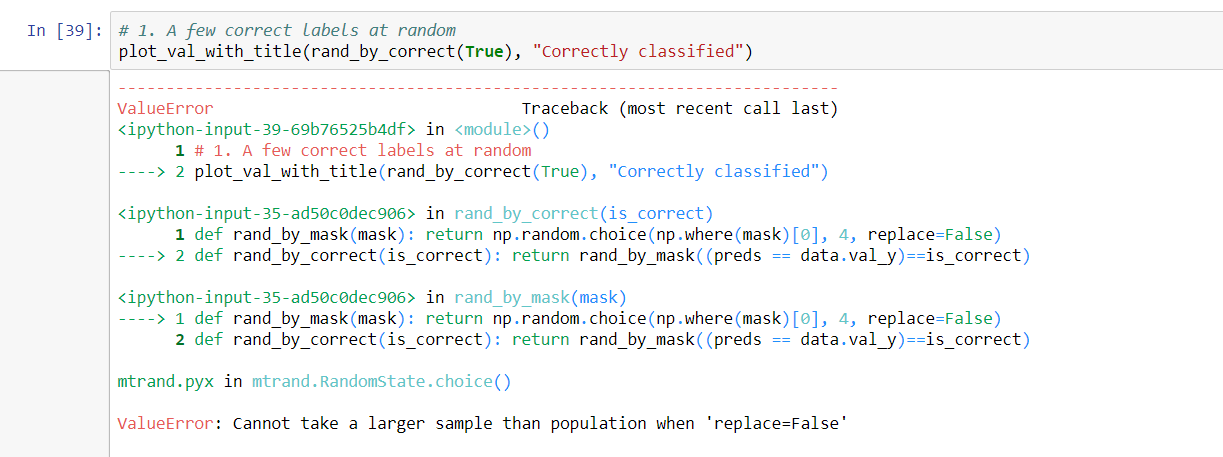
I get this when i set replace=False. What does it mean by “cannot take a larger sample than the population” and how do i work around this?
Thanks!
Hello everyone,
I’m trying to reproduce the first notebook on a sample of the original dogscats dataset (around 200 pictures) by following the instructions given at the end of the notebook (section called “Review: easy steps to train a world-class image classifier”), but I’m a bit confused.
I have difficulty understanding this two times procedure corresponding to the points
which I implemented with
learn.fit(0.05, 2)
learn.precompute = False
learn.fit(0.05, 3, cycle_len=1)
There are two things I don’t understand:
Sorry for my naivety, I’m really a beginner.
Thanks in advance!
Another quick question about how to use lr_find():
I don’t really understand the purpose of the variable lrf in the cell with
lrf=learn.lr_find()
it looks like lrf doesn’t reappear anywhere else in the code. I had the impression that the aim of this lr_find method was to be then able to do the plot with the command
learn.sched.plot()
and then to choose a good learning rate by looking at the plot.
Did I get something wrong?
Thanks in advance.
Precompute and tfms (transformations) have a well discussed thread in this forum… Here’s it
(precompute=True) Answer’s to 3 and 4
lrf=learn.lr_find() we can skip that lrf but it’s quite useful though in the later stages
We can use that lrf as shown below,
lrs = np.array([ 1, 2, 3 ]); learn.lr_find(lrs / 1000)It is based on this Cyclical Learning Rates for Training Neural Networks
@nickl
Aha!
It looks like someone submitted a pull request to fix lesson 2, but the Lesson 1 notebook still needs the fix.
I’ll fix the Lesson 1 notebook and submit a pull request.
the repo is now updated to work with 2.x and 3.x both!
Is there a script to set up a conda environment on my own ubuntu machine with all needed libraries for fast.ai? all that is mentioned here so far concerns a cloud installation. Nevertheless, I seem to possess the latest mobile GPU and wanna give it a go.
perhaps this is what you’re looking for: bash setup script
I understand the overall concept of the Notebook now. When going line by line, following line stood out
Why is that we use only the probability of dog throughout the notebook. Why don’t we use the probability of cat anywhere? I presume we could’ve used either one as the sum of probability along each row is one or almost 1.