MY EXPLANATION
This are the explanations on what we learnt at course, part 1, lesson2 (18.40 in the video)
We put the graphs next to each other. And the idea is to minimize the loss function and to increase the LR.
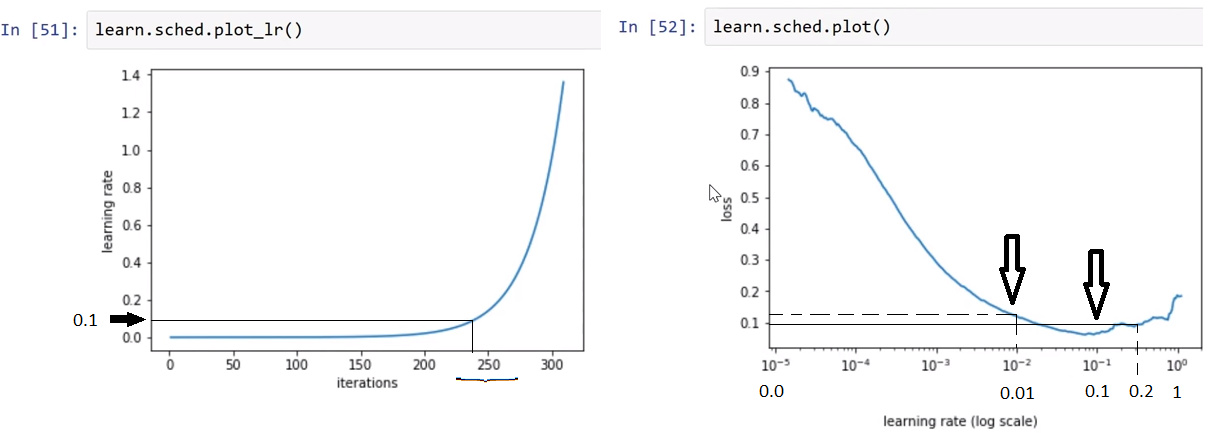
As we can see on the graph at left, there is a point on the iterations axis where the curve go dramatically up, exponentially. It is in a neighborhood of 250. This coresponds on the LR axis to the [0.0,0.2], more precisely to the [0.0,0.1] interval.
As we can see in the graph at right, the interval in discussion is 0.0=10**(-5) and 0.2 which is greater then 0.1=10**(-1). As the LR starts from 0=10**(-5) and increases with very small quantities, the loss function goes down steep enough. There is a point on LR axis in the graph at right where the loss function begins to go up. And we don’t want that. This is 10**(-1)=0.1. This the minimum. But we don’t want the point where the curve changes it’s shape and goes up, which means the increasing of loss, but instead a closer point, which is 10**(-2)=0.01. This is the point with the highest LR and the small loss.
This is the reason we chose 0.01 in the line of code learn.fit(0.01,3).