That all sounds OK. We’ll be learning about this on Monday, so see how you go then…
okay, thanks, will do. I’ll experiment between now and then and see what happens 
Crazy geeky! ![]()
Here are my numbers @jeremy (all are wall time)
| learn.fit() | Before | After |
|---|---|---|
| learn.fit(0.01, 1) | 2.83 s | 1.97 s |
| learn.fit(1e-2, 1) | 2.68 s | 2.02 s |
| learn.fit(1e-2, 3, cycle_len=1) | 1min 58s | 2min 12s |
| learn.fit(lr, 3, cycle_len=1, cycle_mult=2) | 11min 42s | 12min 2s |
| learn.fit(1e-2, 1) | 2.59 s | 1.95 s |
All things same, Torch Dataloader seems to do slightly better over large iterations.
@memetzgz
Yeap… the whole thing about using cyclic learning rates is a little crazy (and unintuitive) just looking at the loss. It is very well explained and shown in the original paper. The idea is that the training loss will be mostly worse at intermittent epochs, but at the end of a cycle, it (should) suddenly spike up, followed again by a drop.
Hope to hear about it though. It’s so simple, but seems really useful. I would encourage you to read the paper since the paper is also very easy to read.
1 Like
I changed the default num_workers, so I suspect the slower speed on larger datasets might be that - try num_workers=4 .
That’s true - although I doubt many of the folks here learning DL for the first time will find it useful to read papers just yet…
1 Like
The default num_workers set in dataset.py is 8, and that’s what the 3rd and 4th fit() were using (the lengthier ones). I anyway ran all with num_workers set to 4:
| learn.fit() | Before | After | After num_worker=4 |
|---|---|---|---|
| learn.fit(0.01, 1) | 2.83 s | 1.97 s | 1.94 s |
| learn.fit(1e-2, 1) | 2.68 s | 2.02 s | 2.04 s |
| learn.fit(1e-2, 3, cycle_len=1) | 1min 58s | 2min 12s | 2min 26s |
| learn.fit(lr, 3, cycle_len=1, cycle_mult=2) | 11min 42s | 12min 2s | 12min 3s |
| learn.fit(1e-2, 1) | 2.59 s | 1.95 s | 2.02 s |
–
1 Like
@jeremy thanks for the updates! I reran it and everything in the notebook now works for me as well.
However, I am also now getting memory allocation issues that I didn’t experience before the update. I have 16gb RAM which gets filled up pretty quickly (even before the augmentation section its all used up) and then even my swap memory fills up.
Is it expected/normal for lesson 1 notebook to require more than 16gb ram to run?
UPDATE: I can see the difference now in the updated notebook. In the updated version in the section where we choose the learning rate when we create the learner it actually appears to cycle through/load all the data. Whereas in the original version I believe we just define the learner but nothing happens until we run lrf=learn.lr_find(). So this is what is causing the memory allocation issues for me.
UPDATE 2: I just tested the notebook again with the first fix you made (prior to the custom dataloader) and the notebook runs fine all the way through without any memory allocation issues. I can even reproduce the 99.5% accuracy 
I am not familiar how Jeremy exactly does it, but wanted to ask anyways: is it the issue with insufficient GPU memory, or the System memory? I ask because you surely would’ve hit the memory issue with GPU before RAM. i suppose…
Also, I’ve noticed with PyTorch in trials in an other project that the GPU memory stays occupied, and if I reran the model, it’d often run out of GPU (or CUDA memory).
Also, I know that you increased your shmi memory to ~8 GBs yesterday. Does that mean the physical RAM is getting a smaller memory amount at the moment (i don’t know) ? At the least, I suppose you could try reverting that change. It might bail you out just enough…
@apil.tamang I was referring to RAM not to GPU memory. For more details I just updated my post with my findings so you can refer to that Thanks for looking out!
No. I just checked on crestle and it’s using <4GB RAM total, including libs and OS, after finishing data augmentation section.
1 Like
OK great thank you for confirming. This was also my experience when using the first fix but the memory allocation issues I outlined in my prior post was what I encountered when I tried using the second fix (custom dataloader). I am not sure what caused it but either way I’m just going to stick with the first version since that one is working great. Thanks again!
Hmmm… Might be better to try to get the new one working, since otherwise you’ll be using a different approach to everyone else, which might be confusing for debugging other issues later - and I won’t have a chance to fix the underlying problem! So if you do have time, I’d love to try to debug this with you
OK sure!
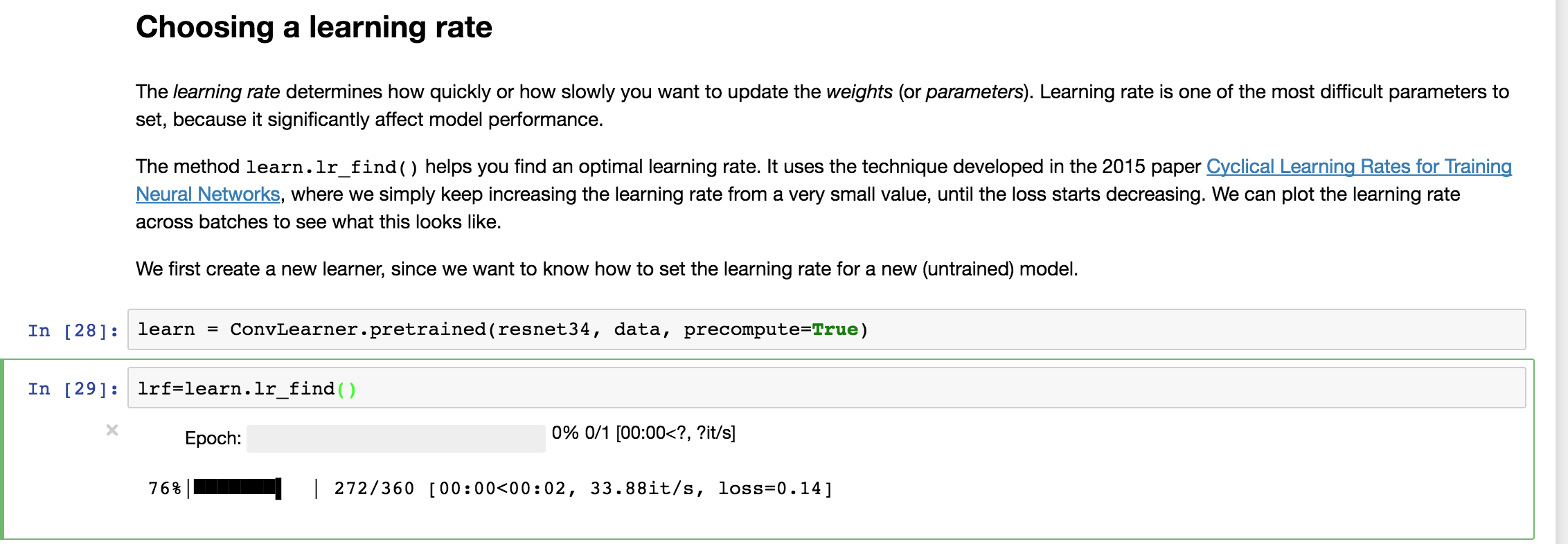
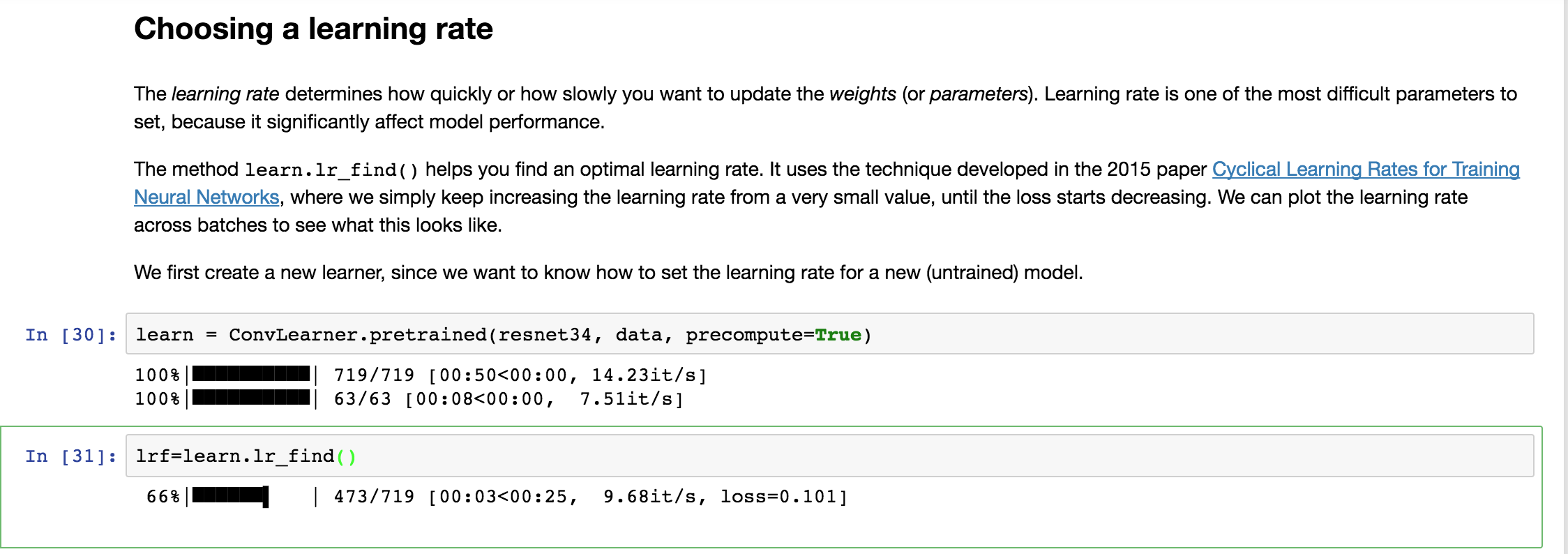
Well the main thing that caught my attention in the second fix is in the section where we choose the learning rate using lrf=learn.lr_find(). When we create the learner with this line learn = ConvLearner.pretrained(resnet34, data, precompute=True) it loads all 25k images (train+valid) into memory. You can see this in the attached screenshot of my notebook. With the prior versions I didn’t see any activity on this line, only in the next code block when we run lrf=learn.lr_find(). I attached a screenshot of that earlier version as well for comparison.
Should this line learn = ConvLearner.pretrained(resnet34, data, precompute=True) be loading all of the training/validation set into memory when we execute this code block? My understanding was that this line is just building the model but shouldn’t be loading data, perhaps I’m wrong though? I also thought the data isn’t being loaded until we run the fit method i.e. in batches? In your prior post you confirmed that running the whole notebook should not take more than 4GB RAM so I’m curious why the data takes up more than 16GB for my machine
Crestle took ten minutes to run it on GPU.
OK I just reran both versions again and have some insights that may be useful…
When I run the notebook with the second fix with the activations already in the tmp folder then I don’t have any issues with memory when I run this line learn = ConvLearner.pretrained(resnet34, data, precompute=True). However, if I remove the activations by running the line !rm -rf {PATH}tmp and rerun the next three lines I can see that the new activations are not being saved to the tmp folder. When I test this with previous versions the activations are of course being saved to the tmp folder as expected.
Also, even when I do run the notebook with the saved activations already in the tmp folder I still run into memory allocation issues when I run the fit method after setting learn.precompute=False.
Sounds like somehow it isn’t using Bcolz. Odd. Probably some bug I’ve created… What steps seem to cause that? I’ll try to replicate
Step 1: Uncomment and execute this line (it is commented by default in the notebook)
#!rm -rf {PATH}tmp
Step 2: Run the next 3 lines of code:
data = ImageClassifierData.from_paths(PATH, tfms=tfms_from_model(resnet34, sz))
learn = ConvLearner.pretrained(resnet34, data, precompute=True)
learn.fit(0.01, 1)
Step 3: Now check the tmp folder (/data/dogscats/tmp) to see if the activations have been saved there. When I run the code on my machine the bcolz files are not generated.
You make an excellent point ![]() Turns out some code was added at some point that I didn’t notice, and it was putting
Turns out some code was added at some point that I didn’t notice, and it was putting tmp in the home dir instead of the correct location. So it is indeed a bug, but shouldn’t cause the memory problem you mention.
Anyhoo, I’ve fixed that bug and pushed to git, so you should find that the bcolz array is now generated in the place you expect, which will help us debug your memory issue!
Also, be sure that you’re looking at the available column in free -h, not the free column (since that includes cache etc).
I can now see bcolz arrays are being generated in the tmp folder as expected, so thats at least a good sign!
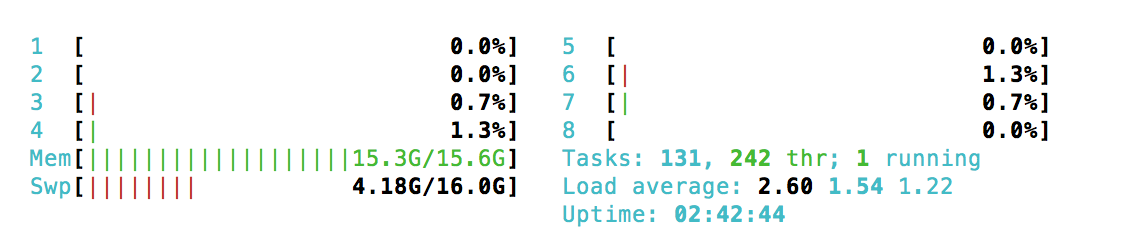
However, you are correct that this didn’t solve my memory issues See attached is a copy of my htop and free -h outputs for reference. With prior versions I would typically see that 4GB RAM was sufficient to run the whole notebook from start to finish, now I can’t seem to get past the quick start section.
Here below is the traceback for the memory allocation error for reference. Perhaps that will help us diagnose the root of the problem!

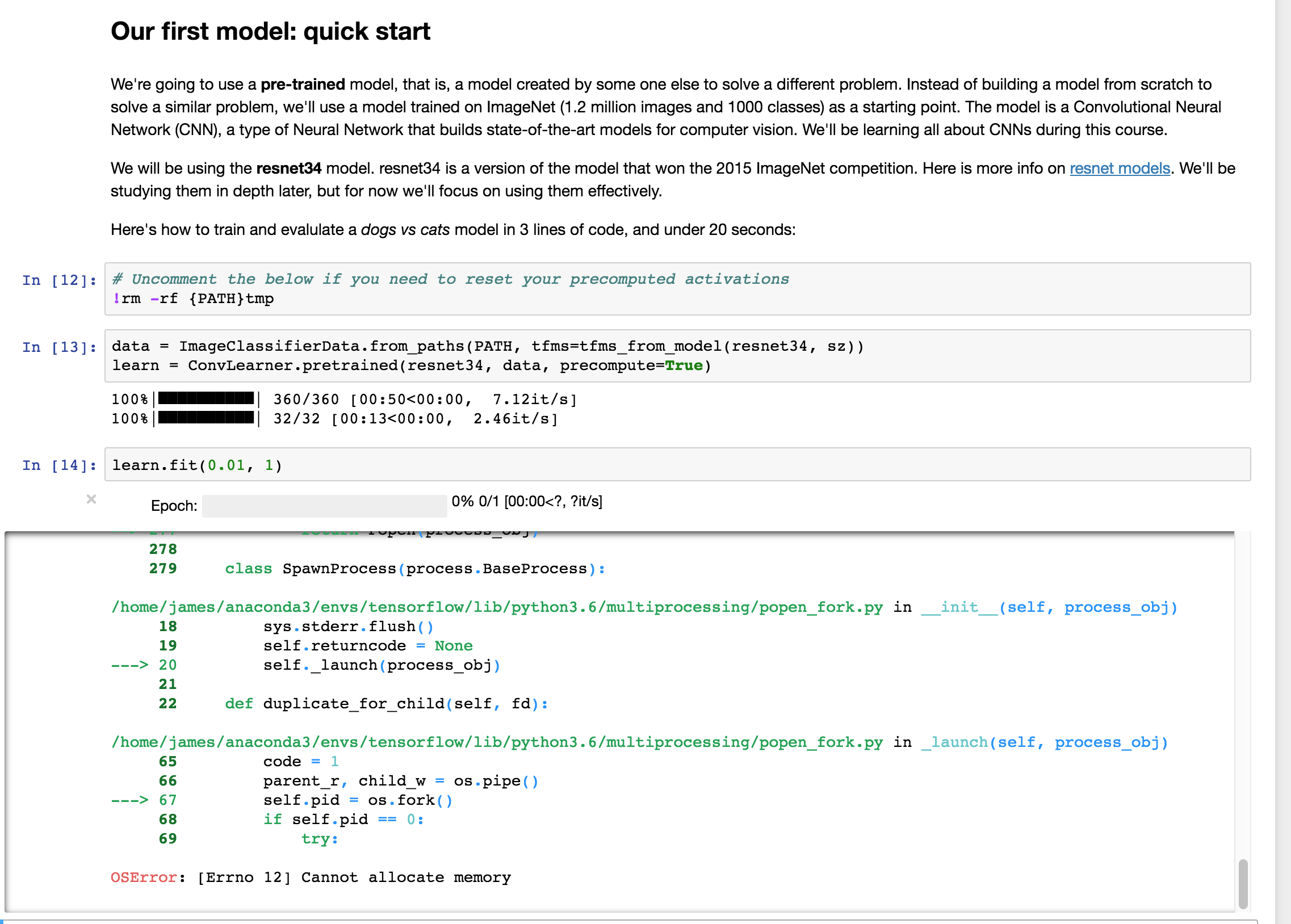
---------------------------------------------------------------------------
OSError Traceback (most recent call last)
<ipython-input-14-6d26286c0877> in <module>()
----> 1 learn.fit(0.01, 1)
/home/james/fastai/courses/dl1/fastai/learner.py in fit(self, lrs, n_cycle, wds, **kwargs)
89 self.sched = None
90 layer_opt = self.get_layer_opt(lrs, wds)
---> 91 self.fit_gen(self.model, self.data, layer_opt, n_cycle, **kwargs)
92
93 def lr_find(self, start_lr=1e-5, end_lr=10, wds=None):
/home/james/fastai/courses/dl1/fastai/learner.py in fit_gen(self, model, data, layer_opt, n_cycle, cycle_len, cycle_mult, cycle_save_name, metrics, callbacks, **kwargs)
79 n_epoch = sum_geom(cycle_len if cycle_len else 1, cycle_mult, n_cycle)
80 fit(model, data, n_epoch, layer_opt.opt, self.crit,
---> 81 metrics=metrics, callbacks=callbacks, reg_fn=self.reg_fn, clip=self.clip, **kwargs)
82
83 def get_layer_groups(self): return self.models.get_layer_groups()
/home/james/fastai/courses/dl1/fastai/model.py in fit(model, data, epochs, opt, crit, metrics, callbacks, **kwargs)
93 if stop: return
94
---> 95 vals = validate(stepper, data.val_dl, metrics)
96 print(np.round([epoch, avg_loss] + vals, 6))
97 stop=False
/home/james/fastai/courses/dl1/fastai/model.py in validate(stepper, dl, metrics)
102 loss,res = [],[]
103 stepper.reset(False)
--> 104 for (*x,y) in iter(dl):
105 preds,l = stepper.evaluate(VV(x), VV(y))
106 loss.append(to_np(l))
/home/james/fastai/courses/dl1/fastai/dataset.py in __next__(self)
222 if self.i>=len(self.dl): raise StopIteration
223 self.i+=1
--> 224 return next(self.it)
225
226 @property
/home/james/fastai/courses/dl1/fastai/dataloader.py in __iter__(self)
75 def __iter__(self):
76 with ProcessPoolExecutor(max_workers=self.num_workers) as e:
---> 77 for batch in e.map(self.get_batch, iter(self.batch_sampler)):
78 yield get_tensor(batch, self.pin_memory)
79
/home/james/anaconda3/envs/tensorflow/lib/python3.6/concurrent/futures/process.py in map(self, fn, timeout, chunksize, *iterables)
482 results = super().map(partial(_process_chunk, fn),
483 _get_chunks(*iterables, chunksize=chunksize),
--> 484 timeout=timeout)
485 return itertools.chain.from_iterable(results)
486
/home/james/anaconda3/envs/tensorflow/lib/python3.6/concurrent/futures/_base.py in map(self, fn, timeout, chunksize, *iterables)
546 end_time = timeout + time.time()
547
--> 548 fs = [self.submit(fn, *args) for args in zip(*iterables)]
549
550 # Yield must be hidden in closure so that the futures are submitted
/home/james/anaconda3/envs/tensorflow/lib/python3.6/concurrent/futures/_base.py in <listcomp>(.0)
546 end_time = timeout + time.time()
547
--> 548 fs = [self.submit(fn, *args) for args in zip(*iterables)]
549
550 # Yield must be hidden in closure so that the futures are submitted
/home/james/anaconda3/envs/tensorflow/lib/python3.6/concurrent/futures/process.py in submit(self, fn, *args, **kwargs)
452 self._result_queue.put(None)
453
--> 454 self._start_queue_management_thread()
455 return f
456 submit.__doc__ = _base.Executor.submit.__doc__
/home/james/anaconda3/envs/tensorflow/lib/python3.6/concurrent/futures/process.py in _start_queue_management_thread(self)
413 if self._queue_management_thread is None:
414 # Start the processes so that their sentinels are known.
--> 415 self._adjust_process_count()
416 self._queue_management_thread = threading.Thread(
417 target=_queue_management_worker,
/home/james/anaconda3/envs/tensorflow/lib/python3.6/concurrent/futures/process.py in _adjust_process_count(self)
432 args=(self._call_queue,
433 self._result_queue))
--> 434 p.start()
435 self._processes[p.pid] = p
436
/home/james/anaconda3/envs/tensorflow/lib/python3.6/multiprocessing/process.py in start(self)
103 'daemonic processes are not allowed to have children'
104 _cleanup()
--> 105 self._popen = self._Popen(self)
106 self._sentinel = self._popen.sentinel
107 _children.add(self)
/home/james/anaconda3/envs/tensorflow/lib/python3.6/multiprocessing/context.py in _Popen(process_obj)
221 @staticmethod
222 def _Popen(process_obj):
--> 223 return _default_context.get_context().Process._Popen(process_obj)
224
225 class DefaultContext(BaseContext):
/home/james/anaconda3/envs/tensorflow/lib/python3.6/multiprocessing/context.py in _Popen(process_obj)
275 def _Popen(process_obj):
276 from .popen_fork import Popen
--> 277 return Popen(process_obj)
278
279 class SpawnProcess(process.BaseProcess):
/home/james/anaconda3/envs/tensorflow/lib/python3.6/multiprocessing/popen_fork.py in __init__(self, process_obj)
18 sys.stderr.flush()
19 self.returncode = None
---> 20 self._launch(process_obj)
21
22 def duplicate_for_child(self, fd):
/home/james/anaconda3/envs/tensorflow/lib/python3.6/multiprocessing/popen_fork.py in _launch(self, process_obj)
65 code = 1
66 parent_r, child_w = os.pipe()
---> 67 self.pid = os.fork()
68 if self.pid == 0:
69 try:
OSError: [Errno 12] Cannot allocate memory