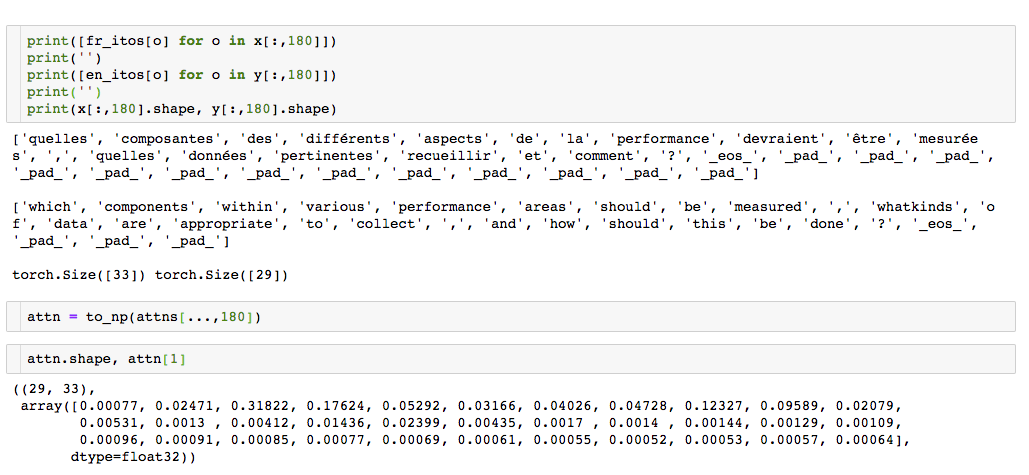
I’m looking at the attention given to the English word “components” below and while I’m expecting that most of the attention would be placed on the French word “composantes”, according to the attn variable it looks like the attention is mostly on the word “des”.
My guess is that tokens are shifted by 1 in the attn variable for some reason, but I don’t know. Any clarification on how to match the attentional weights with the right tokens would be appreciated.
Found a paper that confirms that this “shifted by one” issue is not a new one (see section 3.4). It doesn’t offer a concrete reason for why it is happening although it does recommend including “guided alignment training” to help your attention weights get on track via already established word alignments.
As I spend more time looking at the attention mechanism in this notebook, I’m noticing that things align much better as the sentences become shorter … so I’m inclined to think that the “shifting by one” thing we’re seeing may be due to some difficulty the decoder has with longer sentences.
Consider this example:
Input: quels sont les éléments principaux de cette législation constitutionnelle ? _eos_
Actual: what were the major points of this constitutional legislation ? _eos_
Prediction: what are the main elements of this constitutional legislation ? _eos_
When I example where attention is being placed, thing line up pretty well (first word is the output from the decoder and the second word is the one from the input with the highest attentional weight):
quels what
sont the
les the
éléments major
principaux of
de this
cette this
législation legislation
constitutionnelle constitutional