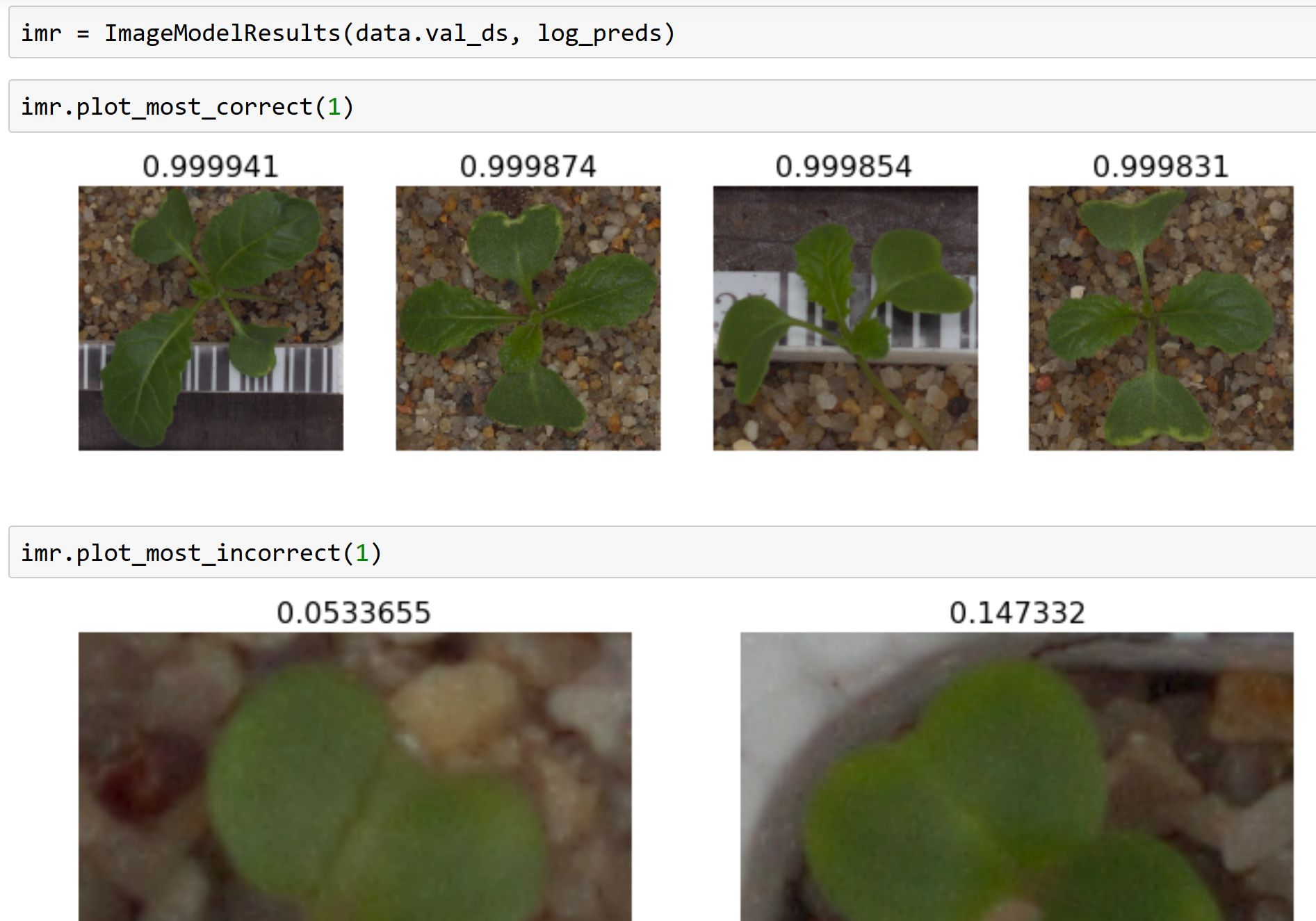
@alessa I packaged up your changes and also refactored it a bit into a class. I also found a bug with missing parentheses (which I suspect came from my original code - sorry!) which I fixed. It’s now in fastai, and here’s an example of it being used with the new kaggle seedlings competition: