[ EDIT 09/22/2019 ] I’ve finally trained a third French Bidirectional Language Model with the MultiFiT configuration. Then, if everything written in this post is still relevant, I’m publishing a new post on this third model that performs better than the 2 previous ones.
French Bidirectional Language Model (FBLM)
Happy to publish my French Bidirectional Language Model (FBLM) trained on a subset (about 100 millions of tokens) of the French Wikipedia.
- notebooks/models parameters/vocab on github
- post (in French) on medium
In fact, I published 2 FBLM:
- one with a AWD-LSTM architecture (fastai default: 3 layers, 1152 hidden parameters) and the spaCy tokenizer (vocab of 60 000 tokens, min_freq of 2)
- another one with a QRNN architecture (fastai default: 3 layers, 1152 hidden parameters) and the SentencePiece tokenizer (vocab of 15 000 tokens)
To be noticed
The FBLM trained with a QRNN architecture and the SentencePiece tokenizer got a better performance.
To be improved
I read the MultiFiT paper (sadly after training my 2 models…) and saw at the end of the paper a list of the hyperparameters values used for the training like 4 QRNN (and not 3 AWD-LSTM), 1550 hidden parameters by layer (and not 1152), no dropout, batch size of 50, etc.
In order to improve the performance of a FBLM, this configuration should be tested.
ULMFiT on the “French Amazon Customer Reviews” (FACR) dataset
In order to test my 2 FBLM, I fine-tuned them on the FACR dataset (see download guide) and fine-tuned after a Sentiment Classifier following the ULMFiT method.
Unlike the 2 FBLMs, the Bidirectional French LM (lm-french.ipynb) and Sentiment Classifier (lm-french-classifier-amazon.ipynb) with a AWD-LSTM architecture and using the spaCy tokenizer have got better results (accuracy, perplexity and f1) than the Bidirectional French LM (lm2-french.ipynb) and Sentiment Classifier (lm2-french-classifier-amazon.ipynb) with a QRNN architecture and using the SentencePiecce tokenizer.
BUT, we found (sadly after the training of our models…) that 11 098 reviews were not in French in the supposed-to-be French dataset (almost 5% out of the 230 684 reviews of our filtered dataset that kept only negative (1 or 2 stars) and positive (4 or 5 stars)).
We should delete these 11 098 review and re-fine-tune our LM and after our sentiment classifier on the only-French reviews dataset.
One more thing: the dataset is unbalanced (about 90% of positive reviews against 10% only of negative ones). A weighted loss was used in order to deal with this problem but other techniques should be tested (oversampling, undersampling, etc.), too.
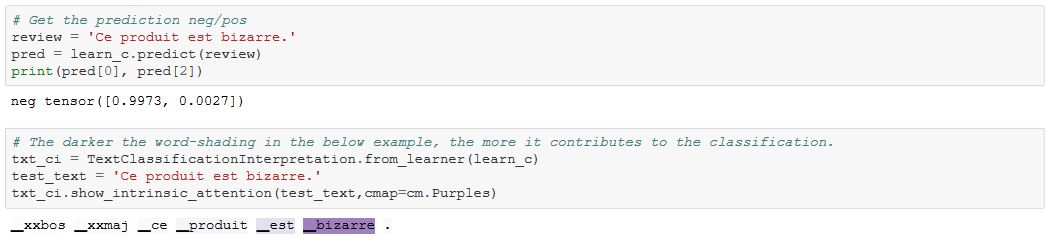
The results on the validation set (I used: 10% of the dataset and seed=42) of the Sentiment Classifier (lm-french-classifier-amazon.ipynb) with a AWD-LSTM architecture and using the spaCy tokenizer are:
- accuracy : (global) 95.97%** | (neg) 92.95% | (pos) 96.35%
Final thoughts
- The French Bidirectional Language Model should be retrained with the MultiFiT hyperparameters values.
- Then, the 2 fine-tuned LM and Sentiment Classifier models should be retrained with the MultiFiT hyperparameters values and on a filtered French dataset (with only French reviews).
- The filtered French dataset should be uploaded online in order to launch a competition on French reviews classification (if the Amazon License allows that).
(if someone wants to do that, I will be happy to help)