Thanks, PeterR! It works for me now.
so glad this info helped you huangkun527!
good luck with it all.
I faced this issue in local installation and resolved by following these steps:-
1)Installed the cudatoolkit from nvidia’s site
2)Then followed the post installation steps like setting the path variable from
installation guide
and after completing the post installation steps it returned True.
If you have the right(compatible) Cuda toolkit installed, try killing and restarting your kernel.
I run my models in Jupyter Lab on a GTX 1050ti 4gb laptop with 16gb of RAM (I am on a windows 10, ubuntu 16.04 dual system). Sometimes, When closing the laptop without a proper shutdown, then rerunning the notebook from where I left leads me to this issue of torch.cuda.is_available() to False. If it does not help, a second option would be to restart your system.
Hope this helps.
1 Like
Hey guys. I hope someone can help me. I’m on Windows 10 on a laptop that has a GTX 1060 NVIDIA GPU. I am getting False from torch.cuda.is_available(), but then True from torch.backends.cudnn.enabled. I checked the anaconda environment and CUDA 9.0 is installed, so I am unsure of why torch.cuda.is_available() is returning false.
Any help is appreciated.
Thank you.
Edit:
Additionally when I type torch.cuda.get_device_name(0) and try to run it, I get the error:
RuntimeError Traceback (most recent call last)
in ()
1 #torch.cuda.is_available()
----> 2 torch.cuda.get_device_name(0)
D:\Anaconda3\envs\fastai\lib\site-packages\torch\cuda_init_.py in get_device_name(device)
272 “”"
273 if device >= 0:
–> 274 return torch._C._cuda_getDeviceName(device)
275
276
RuntimeError: cuda runtime error (35) : CUDA driver version is insufficient for CUDA runtime version at torch/csrc/cuda/Module.cpp:131
Edit #2:
I did some driver updates and restarted my computer and it’s returning True now. Lol
Hello!
I’m using ubuntu 18.04, on a fresh install of graphics- and cuda drivers (as seen in attached picture), but for some reason torch can’t find the cuda installation. I’ve tried restarting several times, which seems to work for some, but it hasn’t worked yet. I’ve updated the system and reinstalled pytorch to the conda environment also.
Any tips appreciated!
Thanks.
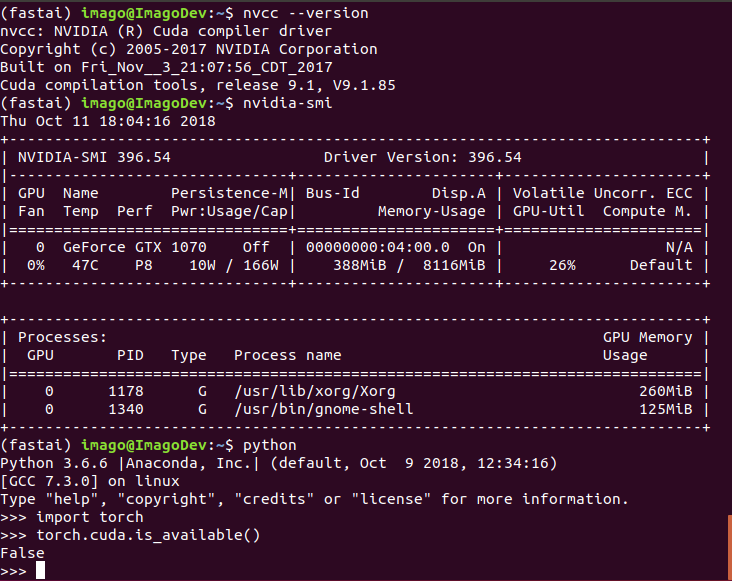
1 Like
have the same situation using CUDA 10
Tue Nov 6 02:01:39 2018
±----------------------------------------------------------------------------+
| NVIDIA-SMI 410.48 Driver Version: 410.48 |
|-------------------------------±---------------------±---------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX 980M Off | 00000000:01:00.0 Off | N/A |
| N/A 52C P0 30W / N/A | 1352MiB / 8126MiB | 0% Default |
±------------------------------±---------------------±---------------------+
±----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 1812 G /usr/lib/xorg/Xorg 598MiB |
| 0 1941 G /usr/bin/gnome-shell 310MiB |
| 0 2933 G …quest-channel-token=4135701586337807034 299MiB |
| 0 7106 G …-token=D024B97535DF059354FD6837194D3132 138MiB |
±----------------------------------------------------------------------------+
./deviceQuery Starting…
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: “GeForce GTX 980M”
CUDA Driver Version / Runtime Version 10.0 / 10.0
CUDA Capability Major/Minor version number: 5.2
Total amount of global memory: 8127 MBytes (8521711616 bytes)
(12) Multiprocessors, (128) CUDA Cores/MP: 1536 CUDA Cores
GPU Max Clock rate: 1126 MHz (1.13 GHz)
Memory Clock rate: 2505 Mhz
Memory Bus Width: 256-bit
L2 Cache Size: 2097152 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536, 65536), 3D=(4096, 4096, 4096)
Maximum Layered 1D Texture Size, (num) layers 1D=(16384), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(16384, 16384), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: No
Supports Cooperative Kernel Launch: No
Supports MultiDevice Co-op Kernel Launch: No
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 10.0, CUDA Runtime Version = 10.0, NumDevs = 1
Result = PASS
found that I was using CPU only version of PyTorch, when I installed the GPU version everything worked
1 Like
I think if you update fastai/pytorch then an incompatible version of cudatoolkit is installed. This is what happened to me. I had cudatoolkit 10.0 but my NVIDIA drivers expected 9.2. Runconda install pytorch torchvision cudatoolkit=x.x -c pytorch where x.x is the version you require. For me x.x = 9.2. Use nvcc --version in a terminal to see what your value of x.x should be.
1 Like