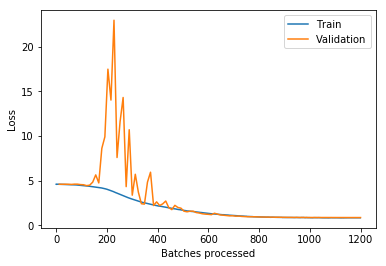
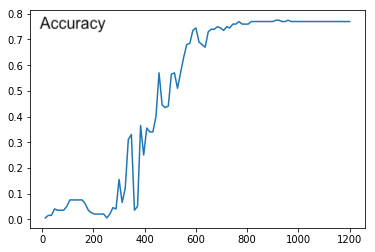
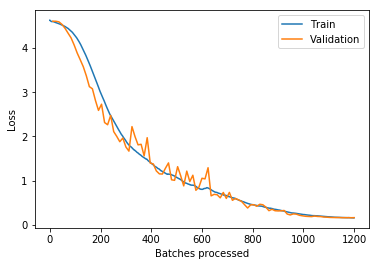
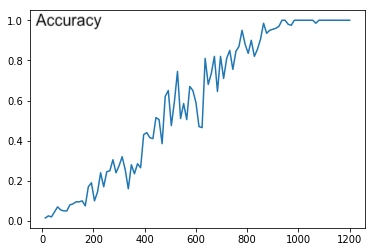
Hi @jeetkarsh,
Embeddings are used to enrich the representation of certain categorical features. With embeddings, a categorical feature with x unique values will be replaced by a matrix with min(x/2, 50) values. This means that the amount of data will be increased.
If your features are time series (I’m guessing since you’ve posted in this thread) there are alternatives to reduce the amount of data. Sampling features based on a “catalytic” event is one of them. This is an extract from Advances in Financial Machine Learning (M. López de Prado, 2018):
Suppose that you wish to predict whether the next 5% absolute return will be positive (a 5% rally) or negative (a 5% sell-off). At any random time, the accuracy of such a prediction will be low. However, if we ask a classifer to predict the sign of the next 5% absolute return after certain catalytic conditions, we are more likely to find informative features that will help us achieve a more accurate prediction.
You could, for example, create a model where you take the last 100 timesteps when the market has moved up or down a certain %. That would certainly reduce your dataset.