Important: should we close the Earthquakes learning competition?
Hi group,
I need to ask you a question about the Earthquakes competition.
I’ve performed some analysis on the dataset (autocorrelation and stationarity - if you want more details its the Exploratory Data Analysis in this notebook), and think that the data is almost random. There is no structure to learn, and this makes the dataset basically unpredictable. That’s I think the main reason why no model seems to work better than all 0s, including some published papers as we have seen.
Based on this I think it’d be good to close this learning competition, and decide if we want to have another one.
The positive side is that we have already developed some models we’ll be able to test in other datasets.
The negative is that it’s frustrating to see that we cannot beat the current sota.
I’d like to know your view on:
Do we close the Earthquakes competition?
Do we launch an alternative competition? And if so, do you have any problem type/ dataset in mind?
I think we should do what Kaggle does when finding problems in the data: relaunch So, close it and immediately start a follow up…
I guess we did not choose the easiest/best dataset to start with But, what has also become clear from all of the great research you shared (and especially the summaries of the results! Thanks again!), most papers always use mutlitple datasets to test on and that is quite easy with the UCR datasets. Still I think the complexity of using all of the UCR datasets is too much.
So why don’t we choose say 5 (or 8 or 10) datasets out of those, that give a good representation of different types of problems (binary classification, few classes, many classes…) and that different algorithms have scored well on. This here gives a very good overview (from one of the links you and @henripal shared), don’t know if it is the most current, but we could easily choose from this list based on those results). https://github.com/hfawaz/dl-4-tsc#results
That way we could test on a few standardized sets and compare. And we should leave the earthquakes in our shortlist, because it is an example of something almost random, difficult to predict…
totally agree, but that means we also have to leave out the earthquakes that “started it all” here. (I will still be comparing with that dataset for myself…)
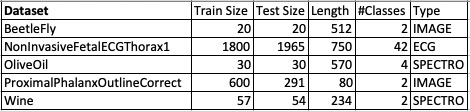
Here’s a list of 5 datasets that meet all this criteria:
Available in 2015 (with correct splits)
Best result & average accuracy (all algos) between 80-95% (that is high, but there’s some room for improvement)
Difference between best and worst result >20% (this is to hopefully ensure that baseline with all 1s is not best result). More separation among algos will allow us to better discriminate which new algorithms work better.
Train size >= Test size
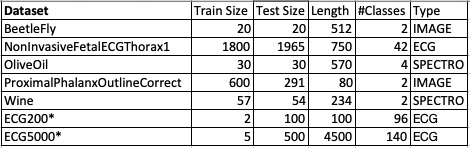
@sam2 ECG200 and ECG5000 meet all criteria except #3, which means that all algos have similar performance.
Shall we vote and decide which one replaces Earthquakes?
We could use the rest (and others) in this group for comparisons.
What do you think?
I’m not opposed to the UCR datasets, but wanted to throw out the the idea of using the Rossman Dataset for a couple reasons:
The data has largely been prepared in the fast.ai notebook which should free the participants to focus on trying different deep learning methods and transformations rather than data munging
The competition was 3 years ago at this point so hopefully, with recent developments, there is room for improvement
The competition and the fast.ai notebook should provide a great baseline
Given the dataset has already been modeled in fastai, it could be a good opportunity to get started “simply” but then strip away layers of abstraction and go deeper into the library to create custom architectures
Obviously it falls more in the ballpark of time series forecasting rather than classification so perhaps this could follow-up the UCR datasets.
maybe we could add the ecg5000 as @sam2 suggested? And I would like to propose the electricDevices Dataset, which is the one with the most examples overall (but pretty low scores across all algorithms (BOSS best with 79.9% acc.
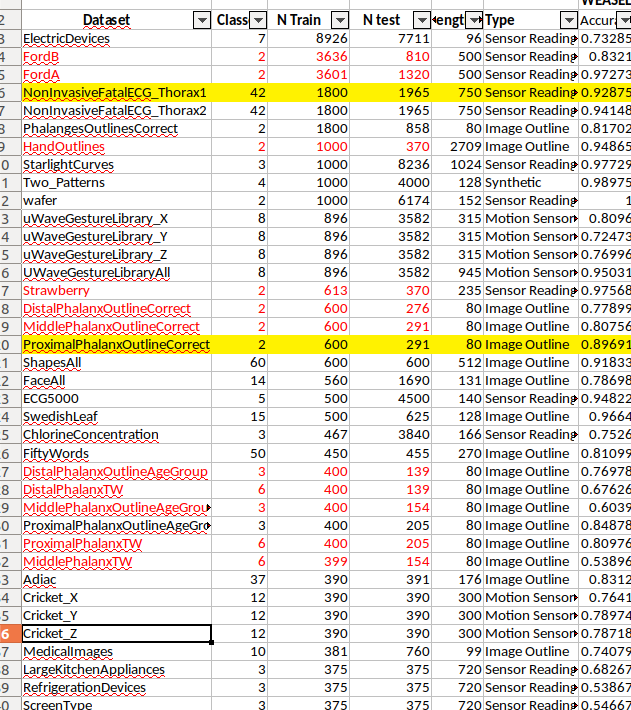
And one mabye stupid question, but are we sure the ones marked in red in this excel file are the wrong ones? They are the only ones that make sense to me, all the others seem to have train / test switched. I mean, what is the sens in having 67 training examples but 1029 in test (italyPowerDemand) or 300 train, 3000 test (yoga). Either the table header is wrong or if the red ones were considered wrong in 2015 and have been corrected, then ALL datasets would now be with train/test reversed? @henripal, can you comment?
I think the Rossman dataset is covered in class and in the forums anyways but of course there could be more experimenting on it. And while of course it is time related, it is not the kind of univariate time series we have discussed in this thread. It is more a regression problem of taking a lot of columnar information in and then predicting “the missing column”. So this can also be seen as time independent. In the datasets in the UCR it is always only the time and therefore sequence of values that is the key to the problem, not how well other features can be related to some output at some point in time. And the problems are classification problems where as Rossman wants a regression value for the total sales of a store as a result.
What would be kind of interesting though is transforming the Data into the time series type of problem (meaning you would for example get one time series per store location and item group). Then it would fit the kind of time series discussed here so far (although it still would not be a classification problem).
Has anyone seen these approaches combined anywhere by chance? (tabular 1step-“forecast” by using many features like rossman and time series over time (here sales per productgroup/store over time) Because that would be an interesting achievement and maybe an answer to some multivariate problems?!
Totally fair points regarding the comparison to univariate time series and the classification vs regression distinction, but that’s why I think it would be interesting. It’s very different from the other examples and already has a strong baseline.
Here is an interesting multi-variate(13) time series paper that handles the problem of missing and irregular time series data in a multi-label(128) classification setting:
Ok, no problem. I’ll add both to the list. We can use them for ‘internal’ use within the study group thread.
Actually I’d like to add some UCR multivariate datasets to the list, so that we can test some of the models we are building. I’m working on a UCR multivariate list now.
We still need to decide though which dataset is used in the 2nd learning competition. Any preference?
UEA & UCR Time Series Classification multivariate datasets
Hi group,
The multivariate TSC archive has just been lauched with 30 datasets.
These datasets have just been introduced in a publication presented on Oct 31st, 2018. The paper is interesting because you can easily visualize ts.
The only algorithms that have been used with these dataset (in the same paper) are nearest neighbors with euclidean distance or dwt, which are no longer considered state of the art.
I’ve looked through the datasets and there are many where accuracy is 70-95%, so there’s still room to improve.
In my opinion, these are the most interesting multivariate datasets:
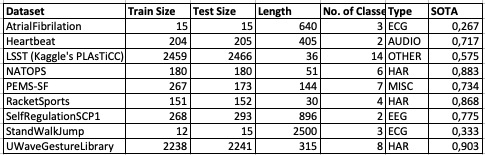
@marcmuc LSST is used in Kaggle’s PLAsTiCC @sam2 there are 2 ECG datasets, although they are supposed to be difficult (sota .3 aprox with 3 classes, and small train & test datasets)
We have talked about some univariate datasets identified:
Note: *ECG200 and ECG5000 all algos perform almost equally and small train datasets
So we need to see how we want to organize ourselves.
Question:
Do we launch a new univariate or multivariate TS learning competition? If so do you have any preference for any dataset? The advantage of univariate is that we have benchmarks to compare our algos.
My view is we could launch a multivariate TS competition, and use the identified univariate datasets to benchmark algos if NN architecture allows it.
I guess it all depends on your prior experience with TS, as well as your preferred approach (traditional, deep learning or both).
There are 2 ebooks on time series I bought written by Jason Brownlee that I found very useful (I have nothing to do with the writer!):
His website also contains lots of information on ML/ DL and TS in particular.
As to where we are going with this, there are some proposed goals here, but it really depends on what the group decides to do. It’s totally open.
So if you have any ideas, comments, feedback, etc please post them!
 So, close it and immediately start a follow up…
So, close it and immediately start a follow up… But, what has also become clear from all of the great research you shared (and especially the summaries of the results! Thanks again!), most papers always use mutlitple datasets to test on and that is quite easy with the UCR datasets. Still I think the complexity of using all of the UCR datasets is too much.
But, what has also become clear from all of the great research you shared (and especially the summaries of the results! Thanks again!), most papers always use mutlitple datasets to test on and that is quite easy with the UCR datasets. Still I think the complexity of using all of the UCR datasets is too much. ok
ok