Hi @shanya,
Do you have any practical example of how to use PDE to time series? I’d love to see it.
@oguiza, might be intresting…
Here is my current approach to this problem
- Get data from 100 meters with 15 min intervals
- Calculate mean usage for every 15 mins
- Clean and normalize so that the range is between 0 and 1
- Fit a time series model that captures the trend, seasonality, daily load profile and validate
From here I can take two approaches:
- Calculate the 15 min avg usage from the yearly totals of meters with only bimonthly readings and apply multiply that with the Yhat from time series predictions
- Get the corresponding yhat for the bimonthly readings and multiply with the certain scaling factor such that the dot product of the vector Yhat and the scaling factor x is equal of close to the bimonthly total.
What do you think of this approach?
Hello.
Firstly, thanks everyone here for your wonderful work on the tsai library! I hope to be able to contribute to it at some point as well…
I am new to this so I hope I am posting to the correct place…
I have been running a local version and I run across a few errors when I try to change the dataset to “ECG200”
More specifically, with the tutorial_nbs 03_Time_Series_Transforms.ipynb, when I set the dataset ID from ‘NATOPS’ to ‘ECG200’ like this:
dsid = 'ECG200'
X, y, splits = get_UCR_data(dsid, parent_dir='./data/UCR/', on_disk=True, return_split=False)
tfms = [None, Categorize()]
dsets = TSDatasets(X, y, tfms=tfms, splits=splits, inplace=True)
dls = TSDataLoaders.from_dsets(dsets.train, dsets.valid)
xb, yb = next(iter(dls.train))
xb[0].show();
everything works fine, until I hit this code cell:
BB_tfms = [ (TSIdentity, 0., 1.), (TSMagScale, .02, .2), (partial(TSRandomTimeStep), .02, .2), (partial(TSTimeWarp, ex=[0,1,2]), .02, .2), (TSRandomRotate, .1, .5), (partial(TSMagWarp, ex=0), .02, .2), (partial(TSTimeNoise, ex=0), .05, .5), ] for i in range(10): xb2 = RandAugment(BB_tfms, N=3, M=1)(xb, split_idx=0) test_eq(xb2.shape, xb.shape) assert not np.array_equal(xb2.data, xb.data)
and then I get the following RuntimeError: CUDA error: device-side assert triggered:
RuntimeError Traceback (most recent call last) <ipython-input-12-805b7e4a25c3> in <module> 9 ] 10 for i in range(10): ---> 11 xb2 = RandAugment(BB_tfms, N=3, M=1)(xb, split_idx=0) 12 test_eq(xb2.shape, xb.shape) 13 assert not np.array_equal(xb2.data, xb.data) ~/anaconda3/envs/tsai-project/lib/python3.8/site-packages/fastai/vision/augment.py in __call__(self, b, split_idx, **kwargs) 33 def __call__(self, b, split_idx=None, **kwargs): 34 self.before_call(b, split_idx=split_idx) ---> 35 return super().__call__(b, split_idx=split_idx, **kwargs) if self.do else b 36 37 # Cell ~/anaconda3/envs/tsai-project/lib/python3.8/site-packages/fastcore/transform.py in __call__(self, x, **kwargs) 71 @property 72 def name(self): return getattr(self, '_name', _get_name(self)) ---> 73 def __call__(self, x, **kwargs): return self._call('encodes', x, **kwargs) 74 def decode (self, x, **kwargs): return self._call('decodes', x, **kwargs) 75 def __repr__(self): return f'{self.name}:\nencodes: {self.encodes}decodes: {self.decodes}' ~/anaconda3/envs/tsai-project/lib/python3.8/site-packages/fastcore/transform.py in _call(self, fn, x, split_idx, **kwargs) 81 def _call(self, fn, x, split_idx=None, **kwargs): 82 if split_idx!=self.split_idx and self.split_idx is not None: return x ---> 83 return self._do_call(getattr(self, fn), x, **kwargs) 84 85 def _do_call(self, f, x, **kwargs): ~/anaconda3/envs/tsai-project/lib/python3.8/site-packages/fastcore/transform.py in _do_call(self, f, x, **kwargs) 87 if f is None: return x 88 ret = f.returns(x) if hasattr(f,'returns') else None ---> 89 return retain_type(f(x, **kwargs), x, ret) 90 res = tuple(self._do_call(f, x_, **kwargs) for x_ in x) 91 return retain_type(res, x) ~/anaconda3/envs/tsai-project/lib/python3.8/site-packages/fastcore/dispatch.py in __call__(self, *args, **kwargs) 116 elif self.inst is not None: f = MethodType(f, self.inst) 117 elif self.owner is not None: f = MethodType(f, self.owner) --> 118 return f(*args, **kwargs) 119 120 def __get__(self, inst, owner): ~/PycharmProjects/tsai-project/tsai/tutorial_nbs/tsai/data/transforms.py in encodes(self, o) 786 tfms_ += [t(magnitude=self.magnitude * float(max_val - min_val) + min_val)] 787 else: tfms_ += [tfm()] --> 788 output = compose_tfms(o, tfms_, split_idx=self.split_idx) 789 return output 790 ~/anaconda3/envs/tsai-project/lib/python3.8/site-packages/fastcore/transform.py in compose_tfms(x, tfms, is_enc, reverse, **kwargs) 148 for f in tfms: 149 if not is_enc: f = f.decode --> 150 x = f(x, **kwargs) 151 return x 152 ~/anaconda3/envs/tsai-project/lib/python3.8/site-packages/fastai/vision/augment.py in __call__(self, b, split_idx, **kwargs) 33 def __call__(self, b, split_idx=None, **kwargs): 34 self.before_call(b, split_idx=split_idx) ---> 35 return super().__call__(b, split_idx=split_idx, **kwargs) if self.do else b 36 37 # Cell ~/anaconda3/envs/tsai-project/lib/python3.8/site-packages/fastcore/transform.py in __call__(self, x, **kwargs) 71 @property 72 def name(self): return getattr(self, '_name', _get_name(self)) ---> 73 def __call__(self, x, **kwargs): return self._call('encodes', x, **kwargs) 74 def decode (self, x, **kwargs): return self._call('decodes', x, **kwargs) 75 def __repr__(self): return f'{self.name}:\nencodes: {self.encodes}decodes: {self.decodes}' ~/anaconda3/envs/tsai-project/lib/python3.8/site-packages/fastcore/transform.py in _call(self, fn, x, split_idx, **kwargs) 81 def _call(self, fn, x, split_idx=None, **kwargs): 82 if split_idx!=self.split_idx and self.split_idx is not None: return x ---> 83 return self._do_call(getattr(self, fn), x, **kwargs) 84 85 def _do_call(self, f, x, **kwargs): ~/anaconda3/envs/tsai-project/lib/python3.8/site-packages/fastcore/transform.py in _do_call(self, f, x, **kwargs) 87 if f is None: return x 88 ret = f.returns(x) if hasattr(f,'returns') else None ---> 89 return retain_type(f(x, **kwargs), x, ret) 90 res = tuple(self._do_call(f, x_, **kwargs) for x_ in x) 91 return retain_type(res, x) ~/anaconda3/envs/tsai-project/lib/python3.8/site-packages/fastcore/dispatch.py in __call__(self, *args, **kwargs) 116 elif self.inst is not None: f = MethodType(f, self.inst) 117 elif self.owner is not None: f = MethodType(f, self.owner) --> 118 return f(*args, **kwargs) 119 120 def __get__(self, inst, owner): ~/PycharmProjects/tsai-project/tsai/tutorial_nbs/tsai/data/transforms.py in encodes(self, o) 209 rand = random_half_normal() 210 scale = (1 - (rand * self.magnitude)/2) if random.random() > 1/3 else (1 + (rand * self.magnitude)) --> 211 output = o * scale 212 if self.ex is not None: output[...,self.ex,:] = o[...,self.ex,:] 213 return output ~/anaconda3/envs/tsai-project/lib/python3.8/site-packages/fastai/torch_core.py in __torch_function__(self, func, types, args, kwargs) 323 convert=False 324 if _torch_handled(args, self._opt, func): convert,types = type(self),(torch.Tensor,) --> 325 res = super().__torch_function__(func, types, args=args, kwargs=kwargs) 326 if convert: res = convert(res) 327 if isinstance(res, TensorBase): res.set_meta(self, as_copy=True) ~/anaconda3/envs/tsai-project/lib/python3.8/site-packages/torch/tensor.py in __torch_function__(cls, func, types, args, kwargs) 993 994 with _C.DisableTorchFunction(): --> 995 ret = func(*args, **kwargs) 996 return _convert(ret, cls) 997 RuntimeError: CUDA error: device-side assert triggered
Can somebody please give me an idea of how I can resolve this issue - my google searches have not been very fruitful…
Thanks in advance!
Helic
Hi @Helicopter9005,
The issue is that you are applying a pretty complex data augmentation designed for a multivariate dataset to a univariate dataset. As the augmentation can’t find the required channels, it throws an error.
In this particular case ex=[0,1,2] requires at least 3 variables (aka features or channels). If you set ex to 0 it works well.
I’d recommend you start by applying simple augmentations first, to try and understand how they work. I learned a lot by plotting augmented samples on top of the original one to see how it performs. You can use this code to do it:
idx = np.random.randint(len(xb))
for i in range(100):
xb2 = TSMagScale(.5)(xb, split_idx=0)
plt.plot(xb2[idx].T.cpu(), color='gainsboro')
plt.plot(xb2[idx].T.cpu())
plt.show()
This is the type of input you’ll get:
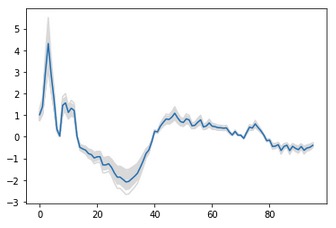
2 Likes
Thanks a lot @oguiza!
I will give it a go and also follow your recommendation of applying simple augmentations first.
Hi all,
I would love some feedback on a general approach for a project I’m taking on.
I have a large number (millions ) of time series. Each time series begins when we start recording for an entry (this can be a different date for each entry). 4 variables are then recorded over time, with a varying sampling rate based on the absolute value of one of the variables. Essentially if the entry is high enough in one of the variables and ‘successful’ then it is recorded and sampled more regularly. Therefore, due to how the data is collected each time series is a different length, both in total number of data points, and the sampling rate. For example some might have four months of weekly data (entry isn’t performing that well so we check weekly), and others might have two years of daily data, (entry has performed consistently well for 2 years so we check daily) and many variations in between. So far I have just linearly interpolated to a daily frequency to fix this sampling rate.
I want to create an artificial ‘event’ in the data where one of the variables passes from below a lower threshold to above a higher threshold in a given period of time. The vast majority of the time series won’t have an event like this occurring.
I’ve also made a criterion to filter out badly performing entries as well so that the comparison is made between aspiring successful entries and successful entries. This will balance out the data to a ratio closer to 10/1. Bear in mind this filtering will also filter out time series which have larger gaps in sampling, due to the sampling method mentioned above (successful entries will probably be sampled close to daily). Depending on the strictness of the event definition and the filtering of badly performing entries, there are roughly 3,000 time series where the event happens and 30,000 that pass the filtering but don’t have an event.
I then want to create some sort of model that will read the multivariate input data from new entries and provide an estimate of how likely it is that this artificial event that has been defined will happen in the coming days. I’m only concerned about the first time this event happens. New entries will have the same filtering as in the paragraph above so that we ignore them and don’t feed them into the model if they are performing below a certain threshold.
This could be a time to event prediction. There is the issue of the event not occurring for most of the cases, I’ve looked at cure models in survival analysis (https://www.annualreviews.org/doi/pdf/10.1146/annurev-statistics-031017-100101) which try to fix this, but it doesn’t seem to match the problem dynamics as the event appears most likely to happen early on. Some sort of regression problem of time to the event would be cool if possible.
I’ve also considered this as a classification of behaviour pre-event (i.e how much new entry matches the patterns leading up to an event). I haven’t really found anything that exactly matches the problem I’m looking at, this looks similar (https://medium.com/@cran2367/dataset-rare-event-classification-in-multivariate-time-series-5d8683b935a0) . I’m unsure how I could effectively sample the multivariate data for “successful” cases when the event happens and “unsuccessful” cases when the event hasn’t occurred. In successful cases where the event has occurred, I could simply shift the data and look a the data leading up to for example three days before the ‘event’, (these series would have different length leading up to that point, is padding the only option here?) but there doesn’t seem to be a logical point to sample unsuccessful cases where event doesn’t happen. Of note, most of the interesting behaviour happens early on and this is where the event is most likely to happen, i.e within 30 days being published. The issue that each time series will have a different length leading up to the event seems like a big one to solve as well.
So to reiterate, the end goal would be a new entry is published, we record 4 streams of data, the entry rises above a lower filtering value at some point and we feed it into the model. The model then tells us if it thinks an event will occur in the near future. I realise this is a messy problem, but the sheer quantity of data is encouraging me to give it a go! Any ideas and feedback on what I’ve said would be amazing!
Henry
I was able to use the Regression tutorial at https://colab.research.google.com/github/timeseriesAI/tsai/blob/master/tutorial_nbs/04_Intro_to_Time_Series_Regression.ipynb
One of my input variables is categorical and would like to have an Embedding to represent the variable. How would I incorporate the categorical variable?
Hello 
A few days ago i stumbled upon the new and amazing tsai (incredible work! @oguiza). I have played around with a few tabular timeseries datasets and have obtained some really great results with univariate forecasting.
However, when i move on to multivariate features dataset with a single y output (either 1 step/forecast or several steps/forecast into the future) I encounter concepts I find hard to grasp.
Mainly it evolves the transformation part of tsai. Especially how to handle categorical features.
My current work process are:
- Tidying the data in a DF
- Using
SlidingWindowPanelto create X and y - Using
Timesplitterto create splits - Using
get_ts_dlswith the X and y to create dataloaders - Finally creating some learners for forecasting
During the get_ts_dls step I would sometimes like to use tfms or batch_tfms. In previous projects with fastai I have used Categorize on DF columns with category dtype. But this method does not seem to work in tsai.
Example with 2 features (1 numeric and 1 categorical) and 1 target (numerical)
Here I am creating the X and y
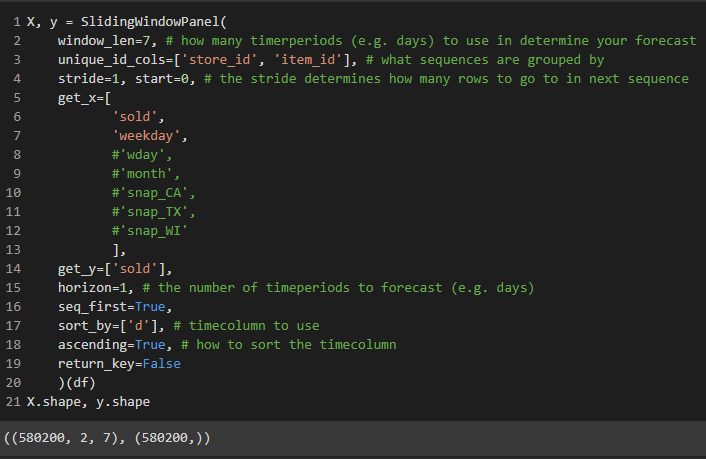
What the first sequence looks like for X

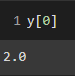
What the first target value looks like for y
If I use Categorize on X I am thrown this error
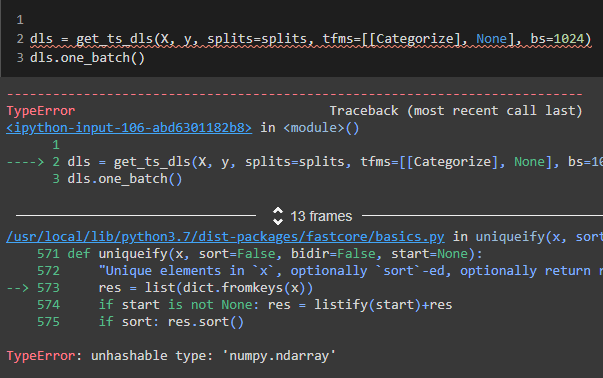
The examples I have found with similar scenarios involves mapping the categorical values before using get_ts_dls. Often with memmap or TensorCategory (and only involving y). But I have a hard time wrapping my head around how to handling these categorical features. Does anyone have a great approach to this challenge or point me in the right direction?
2 Likes
I am trying to build a Dataloader for timeseries forecasting based on underlying pandas dataframes,
I have multiple pandas dataframes from where I want to extract with the rolling window approach slices that will become my timeseries.
With only one dataframe is pretty straightforward and tsai already supports this. The problem is how to deal with multiple non contiguous.
- My current approach is to pre-compute the
(x,y)pairs on each and store them in a list, this is extremely inefficient and can be very heavy if the dataframes are large.Also if I change my window size to try something, I have to recompute all them. - Other option would be to build a custom class that deals with this underlying problem. I don’t know how to build this exactly…
Why I need this?
The simplest example I imagine is that you have 2 days of sun data sampled every hour. And you want to use 2 hours to predict the next hour. So your x is two contiguous values and the y is the next one. But you only want to predict when the sun is up, so you filter out the night. You made a hole in the timeseries and you want to sample your xs and yx from contiguous chunks of data. you end up with two dataframes, one for each day, that don’t glue up. I have thousands of this.
Now you want to build a batch of this x and y to train your Transformer-CNN-UNET-WTF and you need a dataloader to feed the network. Ideas?
This is a classic issue when you filter out data in contiguous timeseries.
Note: I realised that my question is more of How to stack multiple dataset on one dataloader.
class MetaDataset:
def __init__(self, datasets):
store_attr()
def __len__(self):
return sum([len(ds) for ds in self.datasets])
def __getitem__(self, idx):
pass
How to get the __getitem__ to work elegantly?
My best solution constructs a mapping of indexes to find relative positions at init.
Hi @Jcbsorensen,
Thanks a lot for your comments.
I’m afraid there’s no way to do what you want to do out of the box in tsai. You will need to prepare your X data before preparing the dataloader.
Having said that, you may benefit from fastai’s TabularPandas. There’s a relatively simple way to convert a dataframe to the required format using this approach:
from fastai.tabular.core import *
adult_source = untar_data(URLs.ADULT_SAMPLE)
df = pd.read_csv(adult_source/'adult.csv')
cat_names = ['workclass', 'education', 'marital-status', 'occupation', 'relationship', 'race']
cont_names = ['age', 'fnlwgt', 'education-num']
y_names = "salary"
procs = [Categorify, FillMissing, Normalize]
to = TabularPandas(df, procs, cat_names, cont_names, y_names=y_names, y_block=CategoryBlock)
to.xs.values, to.ys.values.ravel()
The output of this are numpy arrays of type float. You can then use SlidingWindow, split the output and create ts_dls.
I haven’t tried this approach, but I think it would work.
Thank you so much!
This was exactly what I was looking for!
hi @oguiza
The TSAI library does not work anymore on colab
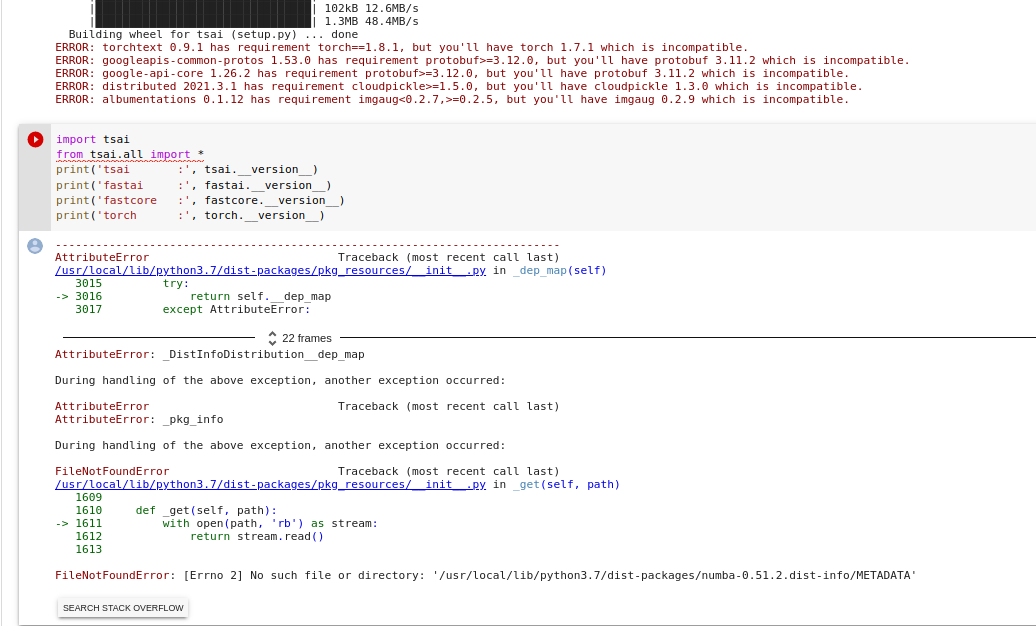
We run into the errors from conflicting libraries when we import it.
Do you know how to fix this?
Thank you
Hi all,
I was hoping someone could point me in the right direction. Please excuse me if I am asking these questions a bit round about, since I don’t really know the right questions to ask.
I am trying to predict a single continuous dependent variable from time series data that is about 10,000 rows x 10,000 columns per object/prediction. That is, I have around 10,000 independent variables per iteration of time and about 10,000 iterations per sample. Then let’s say I can collect 1000 of these samples, so 1000 predictions from 1000 dataframes. All data is numerical/continuous and timestamped in the same increments.
I am trying to predict what the value of one of these columns will be in the future. There may be enough data that I could just use, say 30 to 50 of these 10,000 independent variables, including the one I am trying to predict, but I don’t know which ones are important yet.
Where do I go from here? I learned enough Python to get each object in its own dataframe and can flatten, combine, compress etc samples as needed. I can also think of ways to reduce the number of columns by combining different variables and/or creating derivatives, but would prefer to keep all the data if memory allows it and not introduce biases.
I thought of using the tabular learner, but that seems to make one prediction per row and not relevant to time series. Unless I put an entire object on one row, but that would be 100 million columns. So now I’m looking at random forests, xgboost etc but I don’t know if they are relevant or not.
I would really appreciate some insight on this. Which algorithm and what format should my data be?
Thank you!
I’ve done some further research so maybe I can pose a more specific question.
Required input shape is what I’m struggling to understand.
The way I am reading the below requirements is as a 3d dataframe. Or is this more of an implicit relationship rather than a structural one? We don’t actually combine them all into a single object like a dataframe do we?
Number of samples - how is this represented? as a list of paths? Or is it just referring to the collection of samples used to build a dataset?
Number of features - can TimeseriesAI handle 10,000 features? If not can I combine features into lists and represent as a tuple?
Number of steps - this one I understand
Last question (most importantly) - where do we place the dependent (predicted) variable in all this? Does it go alongside the features in its own column? Or is it represented outside of the data e.g. using the filename?
Sorry for all the noob questions, just want to get unstuck. Thanks
Have a look at df2xy, that’s the way to go if you have your data in a dataframe.
Hi @vrodriguezf ,
Do you know how we can fix the issue of collab no more loading fastai libraries?
Not really, maybe pip installing a previous version of fastai?
You can pip install everything you need.
Then click “Restart runtime”.
And continue running the rest of the cells.
Hi all,
I just wanted to let you all know that @williamsdoug and myself have created a new tutorial notebook in tsai (01a_MultiClass_MultiLabel_TSClassification.ipynb) to show how you can easily perform multi-class and multi-label time series classification tasks.
I want to thank Doug for taking the initiative to create this notebook. I have learned a few things during the process. And we have also streamlined tsai to make it easy to use in these type of tasks. We hope you’ll find it useful!
5 Likes