Correct, here’s an example spectrogram: 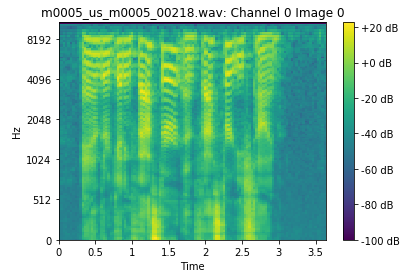
Yes we mainly use resnets/densenets and get very good results. As a result we havent played around with audio specific architecture much, but we are getting to that point now.
None, I have no familiarity with time-series but @scart97 messaged me your work and said “hey maybe we can apply this to audio”. This is my first attempt at applying convs to raw audio for classification. After reading your paper, I think every other time series method is going to take too long.
I’ll detail this more in the code/summary I post, but audio preprocessing helped quite a bit. My initial result was 85.4% accuracy in 4 min 1s, using 10k kernels, and stride 7 (it took a stride of 7 just to make the time reasonable. Removing silence and taking a larger time chunk were what improved accuracy from there.
We are! That’s why the initial results were so exciting/surprising. We are currently building an audio library for fastai v2 and have been looking for a way to allow people to train on raw audio. I’ll continue to work on raw audio while @scart97 tests on spectrograms. I’m fairly new to audio and never learned what wavelet transforms are (I’ve seen the name several times), but I’ll try to dig into it and see if that could be something worth using.
Currently the ridge classifier, but also something I plan to experiment with (today).
Yes we are making sure to do this. Thank you.
Not true at all, I found this extremely helpful. You’ve given me a good list of leads to chase down. I’m going to do a bit more experimentation and then post some cleaned up, hopefully reproducible notebooks. Thanks again.
Also if anyone feels we are cluttering the time-series thread and getting too far outside the scope with the audio discussion, I’m happy to move it to the Deep Learning With Audio Thread
Edit: Back with a summary of results and a (still somewhat messy) notebook.

NB: https://nbviewer.jupyter.org/github/rbracco/fastai_dev/blob/rocket/dev/75_audio_rocket_tuning.ipynb
Repo: fastai_dev/dev at rocket · rbracco/fastai_dev · GitHub
Unfortunately this relies on our fastai v2 audio for some of the preprocessing, it would probably be easier to start from a new notebook than to pull this and try to work out of my fastai_dev fork. I have some more interesting stuff to add for harder datasets but it still needs to be organized. I’ll be back tomorrow or Wednesday