Mixup didn’t help much in my case. Validation error stayed pretty the same (even worse for a bit, but maybe it can be slightly better after some finetuning).
Here’s what I did:
First of all I’ve preprocessed the data (normalized, categorized and fill missing if needed). Then I took a model and fed it all my dataframes (train and validation sets) to embedding layers only (so I’ve got embeddings output for all the data). Then I’ve concat these values with cont values. So to this moment I had a bunch of floats for each row of data (cat values numericalized and cont as is). This is what our NN (apart from embeddings) really gets as input. Then I’ve blended (interpolated) all the values (all independent variables are floats now and my dependent variable is a number, not a class).
Now I can pretend that these floats are just a bunch of cont values and try to teach NN in a normal way (without preprocessing (!)).
The last step is to validate models with validation set (fed through embedding as well)
I’ve already had a function that makes all the preprocess and outputs the ‘real model input’. I’ve made it for Random Forrest with embedding case (RF vs NN) in https://github.com/Pak911/fastai-shared-notebooks/blob/master/interpret_tabular.ipynb
And… As I said I’ve got an error slightly worse than initial model (trained in a normal way).
As for clarity my dataset consists of only about 10 000 rows.
It has 53 category and 26 continuous variables.
And my task is regression, not classification.
Thanks @Pak! I’m very interested in trying this for classification too to see if it helps. I have a few different ones to try with various class nums (17/78) and is full of only categorical. Plus a few that have both. (Although it seems it wasn’t pushed to github quite yet?)
No I didn’t put it on github as a) the code is quite messy, I just wanted to test the theory quick and dirty way b)it was done with my dataset which I cannot open for now.
But if you are interested in I can reimplement it with something more common, Rossmann for ex. ant post it on github.
I would very much so appreciate that or even just the “messy” code too.
I recently discovered a thesis about tabular data and deep learning that used the fastai library. I’m working on recreating everything they did as it’s full of fascinating things. If you’re interested I’ll link it. Mixup was included along with a number of other ideas
(Sadly while they included ‘source code’ the code for some of the experiments was not there)
I’ve made my Rossmann mixup version available on github here
I did not fix the messiness
In fact it is so messy (and uses lists, not iterators) than I had to use only 30% of data to fit augmentation in my memory.
Hope your experiments will go better than mine and we will be able to use mixup in tabular data (or other augmentation techniques)
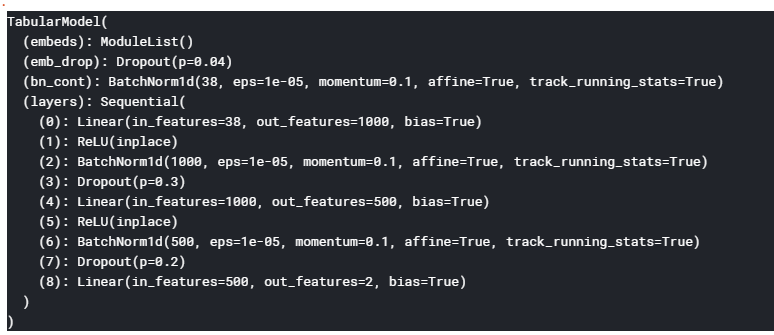
My question is if I pull out or extract the representations from the layer 4 here using Hooks i.e. second last layer before the final layer, will the learning of embeddings be also captured in this layer? Basically, I want to use Hooks to extract the learning in the second last layer and run RF / GBM on that to see if overall performance can be improved. I want to make sure that while I extract the learning from this layer, I don’t miss the categorical embeddings from this.
Hi. Yes, if you put a hook into layer 4 you will get the result activations that gone through all the layers before it, including embeddings layer (I’ve used this method for selfchecking when I used learnt NN embeddings in RF).
I just wrote an implementation of manifold mixup that should work out of the box on tabular data for both regression and classification (and, also, let you inject the mixup at particular places if you want to) :
 b)it was done with my dataset which I cannot open for now.
b)it was done with my dataset which I cannot open for now.