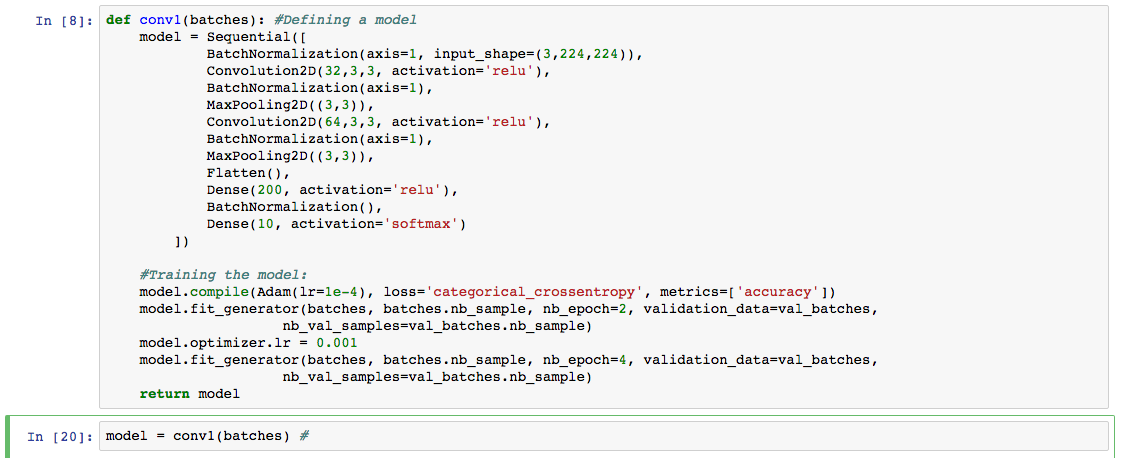
I changed my model to be my own:
def conv1(batches):
model = Sequential([
BatchNormalization(axis=1, input_shape=(3,224,224)),
Convolution2D(32,3,3, activation=‘relu’),
BatchNormalization(axis=1),
MaxPooling2D(),
Convolution2D(64,3,3, activation=‘relu’),
BatchNormalization(axis=1),
MaxPooling2D(),
Convolution2D(128,3,3, activation=‘relu’),
BatchNormalization(axis=1),
MaxPooling2D(),
Flatten(),
Dense(200, activation=‘relu’),
BatchNormalization(),
Dropout(0.3),
Dense(10, activation=‘softmax’)
])
return model
My results are getting better now but I am still only at 40% for my validation set.
Epoch 1/2
20570/20570 [==============================] - 348s - loss: 1.3970 - acc: 0.5540 - val_loss: 3.6192 - val_acc: 0.1490
Epoch 2/2
20570/20570 [==============================] - 296s - loss: 0.6758 - acc: 0.7859 - val_loss: 2.7510 - val_acc: 0.3082
Epoch 1/5
20570/20570 [==============================] - 302s - loss: 0.4530 - acc: 0.8659 - val_loss: 2.4068 - val_acc: 0.3661
Epoch 2/5
20570/20570 [==============================] - 297s - loss: 0.3547 - acc: 0.8947 - val_loss: 2.6552 - val_acc: 0.3462
Epoch 3/5
20570/20570 [==============================] - 299s - loss: 0.2779 - acc: 0.9200 - val_loss: 2.3945 - val_acc: 0.3496
Epoch 4/5
20570/20570 [==============================] - 299s - loss: 0.2358 - acc: 0.9334 - val_loss: 2.4213 - val_acc: 0.3851
Epoch 5/5
20570/20570 [==============================] - 300s - loss: 0.2149 - acc: 0.9379 - val_loss: 2.3568 - val_acc: 0.4075
Btw, I did use data augementation for the validation set as well.
gen_t = image.ImageDataGenerator(rotation_range=15, height_shift_range=0.05,
shear_range=0.1, channel_shift_range=20, width_shift_range=0.1)
batches = get_batches(path+‘train’, gen_t, batch_size=batch_size)
val_batches = get_batches(path+‘valid’, gen_t, batch_size=batch_size)
After 12 epochs my accuracy seems to be going down.
If i were to go and add another layer to the model or add BN or dropout, i would have to throw away all the weights we have learnt so far … is that right?


 see
see