Looking good  I’d suggest a validation set with more drivers than that however - I’m using 3, IIRC
I’d suggest a validation set with more drivers than that however - I’m using 3, IIRC
1 Like
I have also been using 3 and was wondering if adding more would negatively or positively impact my results. Guess I’ll just have to give it a shot!
The downside is your training set will be smaller. The upside is your validation accuracy will be more stable. The best approach would be to create a bunch of models, each time holding out one driver, and then average the validation across all of them (you could also average the predictions across all of them, like the ensembling we did in MNIST last week!) But I wouldn’t bother with that until you had done all the experimenting you wanted to do, since it adds a lot of time to each experiment.
1 Like
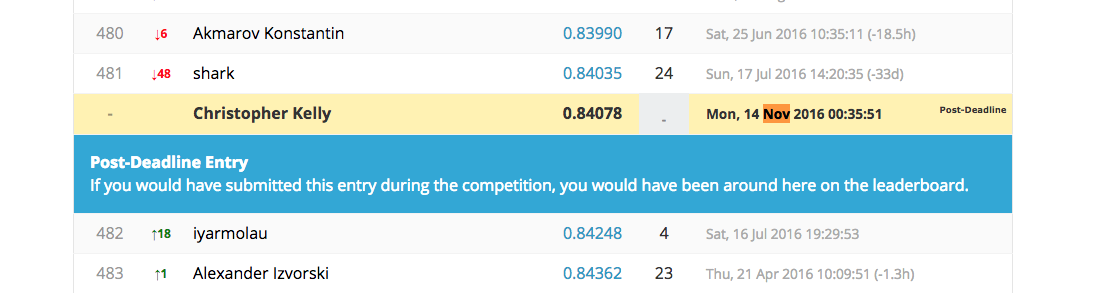
That’s a great result! What was your technique?
I downloaded all the notebooks together with a transcript of the video lectures, then trained a multilayer LSTM. I took the resulting notebook and kept pressing shift-return until I hit an error. I fixed two such errors and I was done!
I am of course joking, the truth is I hacked together something that closely resembles your lesson 3 final model.
2 Likes
The LSTM approach sounds interesting… 
But seriously your result is very good, so I’m sure folks would love to hear more details!
Hello,
I just started StateFarm, and I organized the data into the valid/sample folders like normal.
Anyways, I have begun by “batch.fit”-ting the images like we did with Dogs v Cats. I got a validation accuracy of exactly 0.10000.
Is this the right way to start? You said that in order to “predict events” we use finetuning. Would my next step be to finetune?
Thanks.
Have a look at the thread above both to see how you need to create your validation set (you can’t use the normal approach), as well as how to get training started.
I’m trying a variety of things to see if I can train a model for this problem. I haven’t had any luck yet, but I’ve noticed that the training seems to freeze right at the end of the epoch.
It will sit doing this for longer than it took to get to this point:

This has happened with a few different attempts I’ve tried (setting the last layer trainable, setting the last 5 layers trainable, etc). I can already tell that this model isn’t working, but once I do find a model that works, I’ll need to be able to finish training. Any tips?
How long are you waiting before claiming it’s frozen? After the training it will test against the validation set but doesn’t verbosely tell you what it’s doing.
1 Like
Haven’t been able to get higher than ~11% on the State farm problem.
The question is – do I keep adding optimizations (e.g. change lr, add image generator parameters, etc.), or assume that I have something fundamentally wrong with the setup and should step back before I go deeper into manipulating the model?
Currently: I’m running everything on a sample of about ~10% of the whole dataset with the validation set including 3 drivers that aren’t available in the training set. Replacing the last layer of the model and retraining the last 5 layers of the network.
I’m guessing your validation set is very big. What does get_batches show as being its size?
My sample validation set and sample training set are both 194 images. After shutting down last night and re-running today, I seem to be able to get it to finish training. I’m not sure what I changed, I guess I futzed with the model too much!
Still no successful model yet though 
I am a bit late to this state farm party. This is a hard problem no joy like cats and dogs 
However I was thinking if we had a common sample train and validation set and compare each other’s results we can get a sense what is working or not and why perhaps?
I have created such a sample data set that reflects the original train test split - so in this dataset I have train and valid folders. Approximately ~200 images in each class for the train and ~20 in the valid. So in total > 2000 images (train) and 200 (valid). Five randomly chosen subjects present in the valid are not present in train. Feel free to use this dataset located in my aws’s s3 storage account -
Train s3://kaggle-state-farm-sample-data/train and
Valid s3://kaggle-state-farm-sample-data/valid
To access this data from an instance please see this: http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/AmazonS3.html
I am using s3 for the first time so I am not sure how easy it is share data - let me know if you run into any probs.
For example just using data augumentation, I get this result:
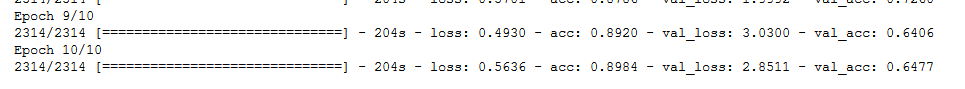
1 Like
I am attempting to do batch normalization and was following Lesson 3 notebook. I noticed this:
bn_model.load_weights('/data/jhoward/ILSVRC2012_img/bn_do3_1.h5')
Any ideas where the ‘h5’ file is located or if it needs to be used at all? For example I can initialize with random weights but unclear at this point.
Ah well spotted… Sorry I shouldn’t have included that in the uploaded notebook, since we’re not doing it until this Monday’s class! This week I’ve figured out how to incorporate batchnorm into VGG properly, and will be sharing the code and weights. In the meantime, you should just use random weights.
Great! I wrote a hackey code to copy the weights from the dense layers of the vgg model to the batch norm model. Look forward to seeing your version of doing it the better way. It looks like the vgg model did not have any batch normalization done - probably because this technique was not invented then or appropriate?
Yup - not invented. Just copying the weights across isn’t going to help you, BTW, since the batchnorm mean and standard deviation will make the weights inappropriate.
ahh… ok. But I am keeping those layers in batch norm trainable to True … so I am thinking the fit function will readjust those weights during training ?