Jay Alammar recently released the Illustrated Stable Diffusion. He previously wrote The Illustrated Transformer, which a lot of folks have found an excellent resource.
21 Likes
A pytorch implementation of the text-to-3D model Dreamfusion, powered by the Stable Diffusion text-to-2D model. https://github.com/ashawkey/stable-dreamfusion.
6 Likes
I stumbled across this project on GitHub.
MotionDiffuse: Text-Driven Human Motion Generation with Diffusion Model
Prompt: “check time”
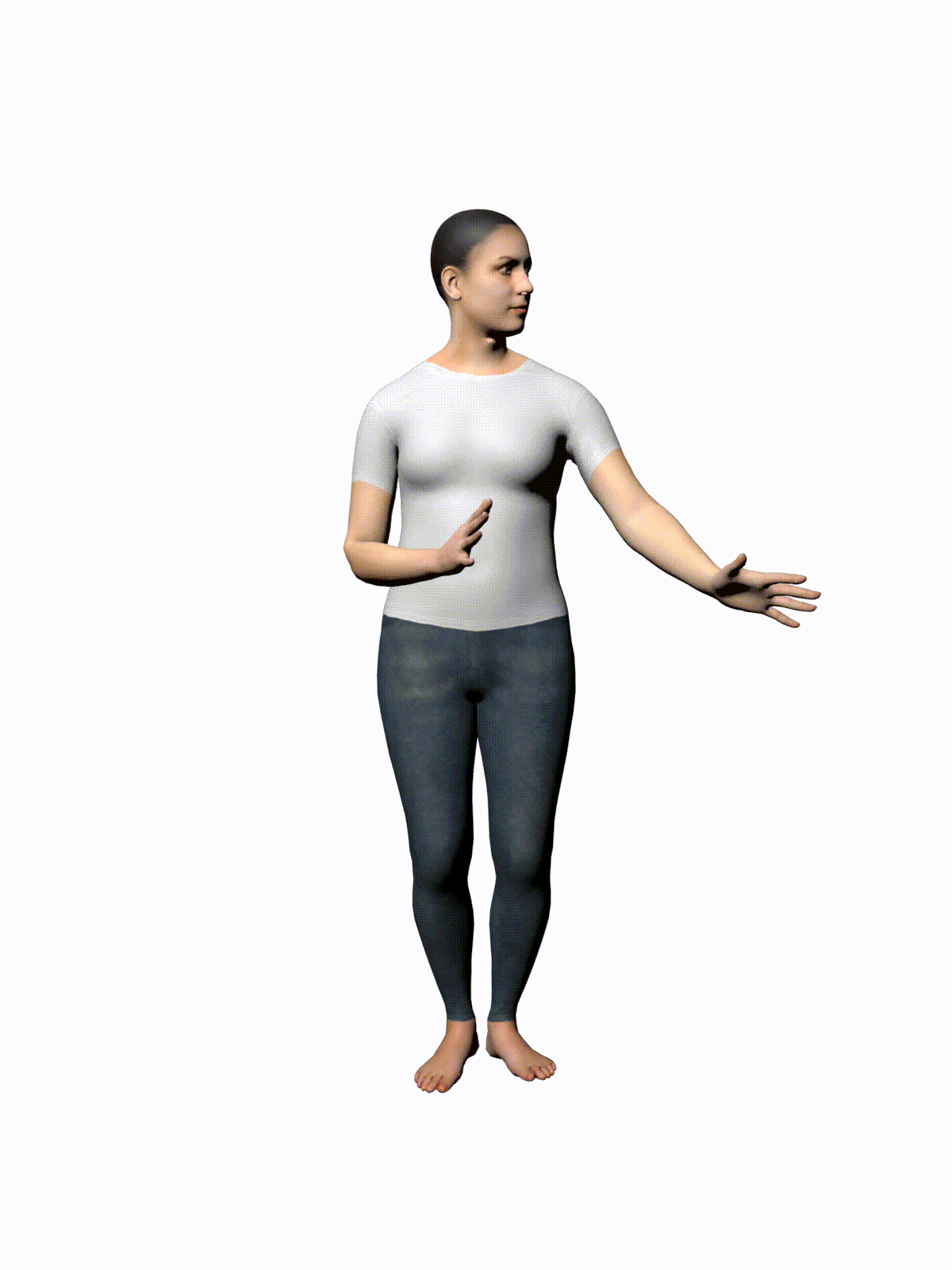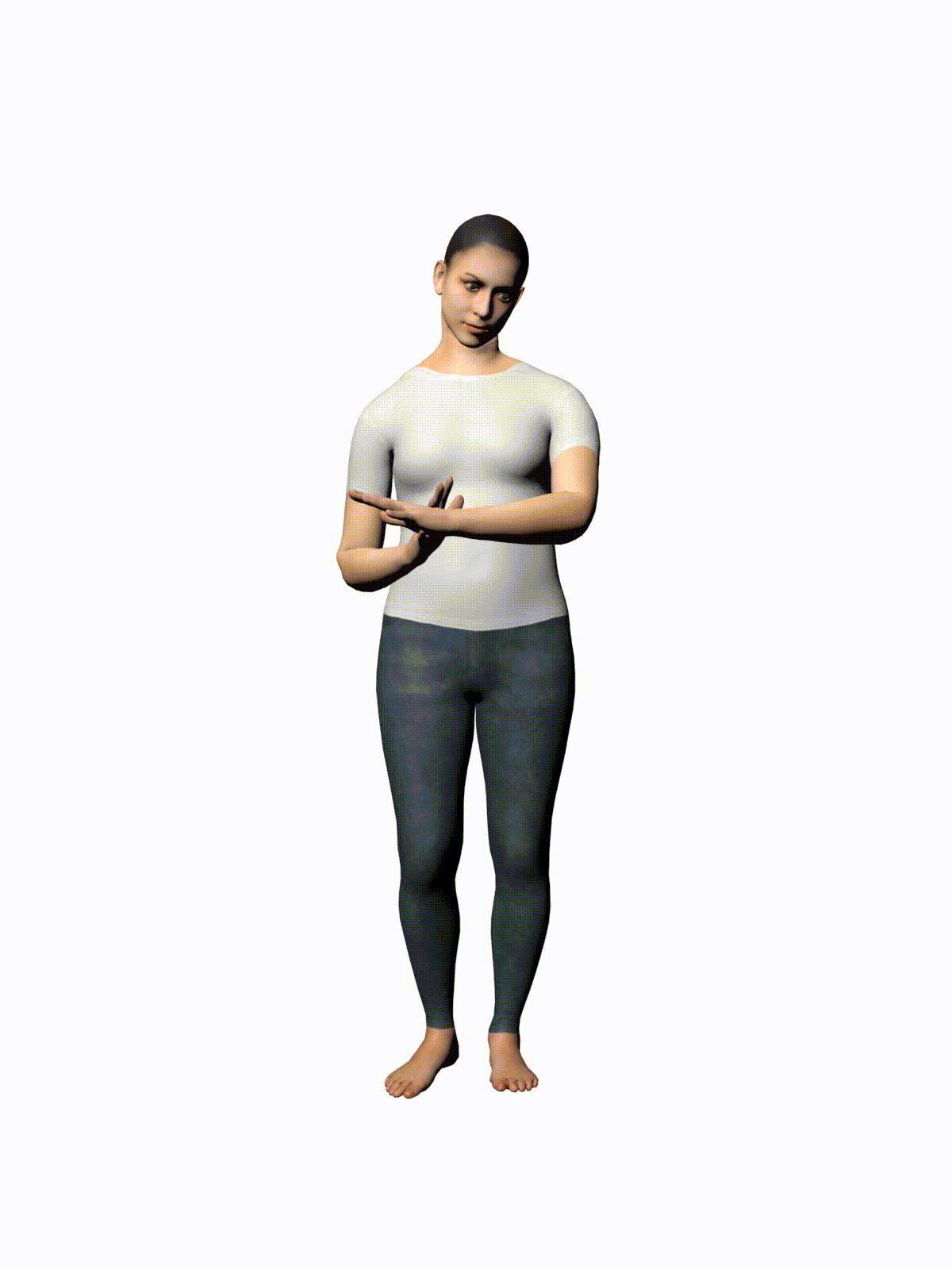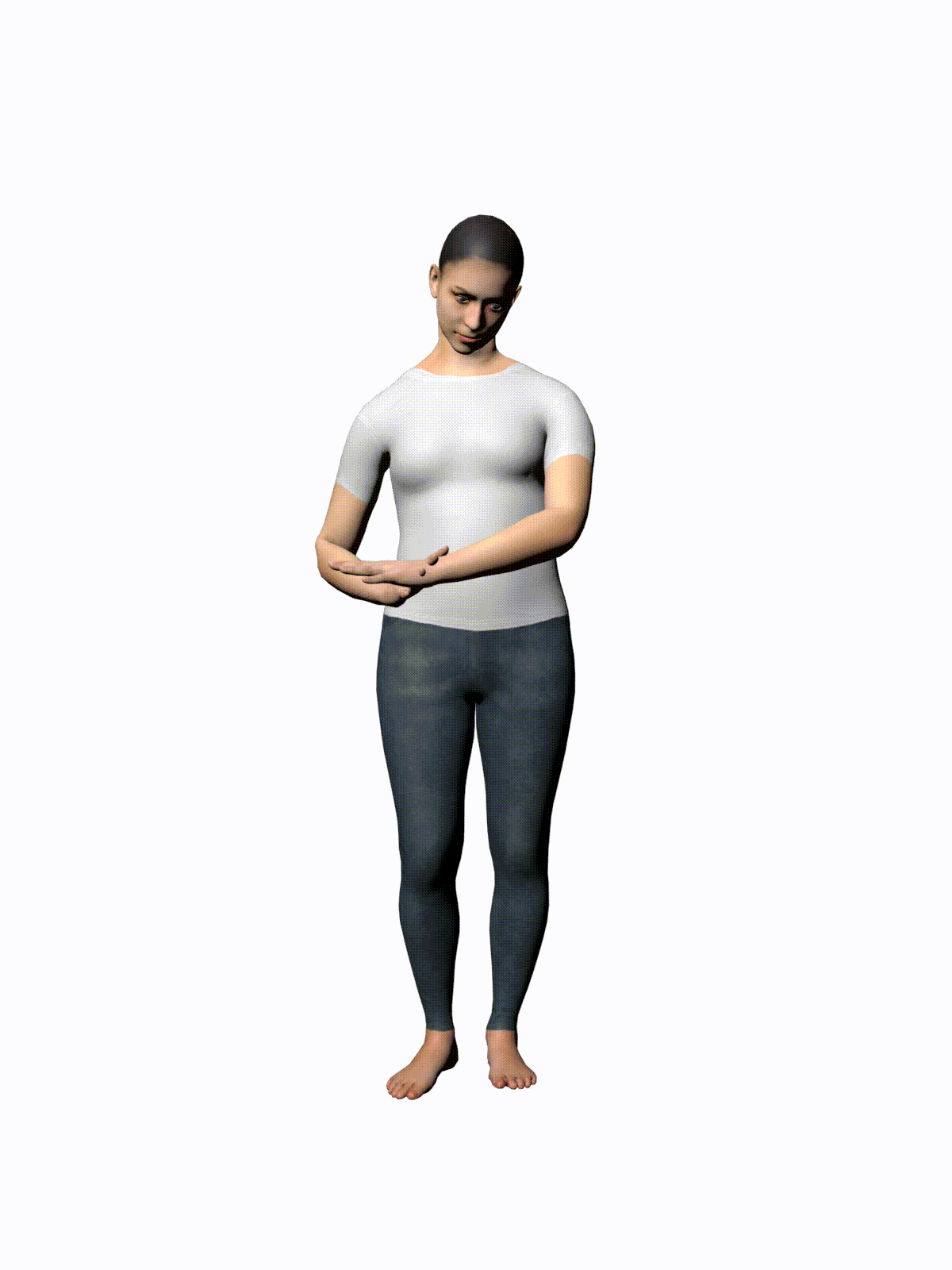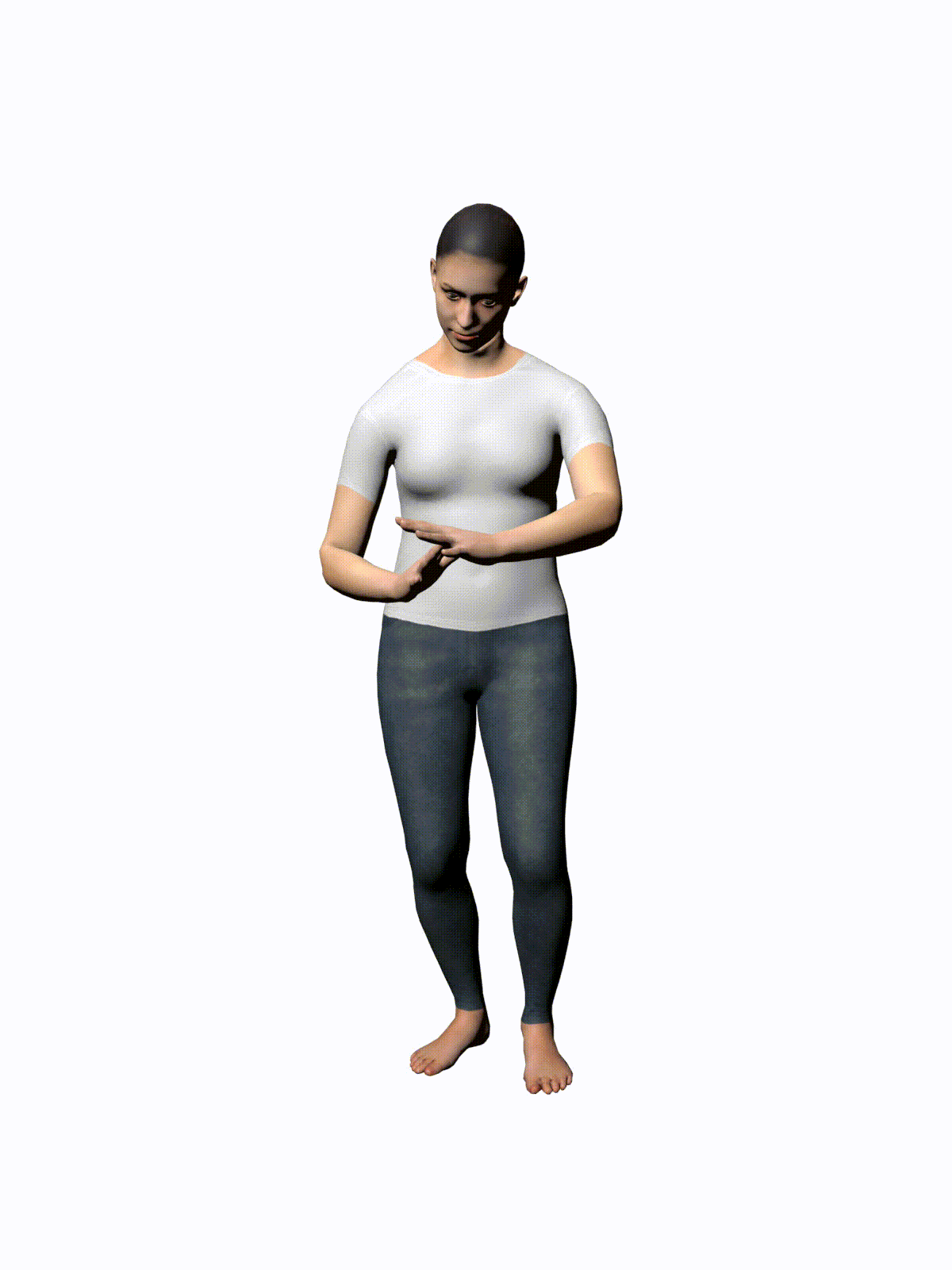
3 Likes
Hmm anyone see a new link for the Berkeley article “Understanding VQ-VAE?)”
Here is an archive of it
Part 1:
https://archive.ph/2021.07.14-200624/https://ml.berkeley.edu/blog/posts/vq-vae/
Part 2:
https://archive.ph/2022.04.24-184903/https://ml.berkeley.edu/blog/posts/dalle2/
Great work @jamesrequa. Inspired by you I also checked out the collab notebook and managed to run it on my paperspace.
Do you have the prompts saved which was used to generate these images? Your images are much better than the outputs which I could get. Wondering if you did something different compared to the collab notebook.
@vettukal Glad to hear you were inspired and nice work getting it running!
Unfortunately I didn’t save the prompts for these images. I didn’t make any significant changes to the original huggingface dreambooth sd notebook that I shared, except to:
- upload the 5 images of jeremy as the training set
- modify the
instance promptfor the newly created concept to bea photo of sks person, I could’ve changedsksto something else but I didn’t think it really mattered - I chose not to do
prior preservationbecause I didn’t plan to use the model for anything else
As for the prompts, it definitely takes a lot of experimentation & curation of outputs to get good results, some are even referring to prompt engineering as like an artform haha. I highly recommend using Lexica as a guide for creating better prompts. I believe for these images I used something along the lines of stunning portrait of sks person, by some artist, artstation & replacing some artist with various artist styles that tend to get good results (once again lexica is a great way to find out good artist names and keywords.
4 Likes
Agreed, Lexica is very good resource for prompt engineering. Of the 5 photos you used, where all of them headshots or were there some body shots also?
@vettukal I tried to have a mixed variety of images including some full body, chest up, and closeup. I think it also helps to have different angles, facial expressions, and background contexts. You definitely aren’t limited to 5 images I just wanted to test that you could get great results even with so few images.
1 Like
I just found this application of diffusion models to my field (computational chemistry):
3 Likes
There are a few different articles out there - but I got Stable Diffusion working locally on my Apple M1 Ultra using this one MacBook M1: How to install and run Stable Diffusion | by Gonzalo Ruiz de Villa | gft-engineering | Sep, 2022 | Medium. Generates an image in around 18s.
7 Likes
Cool new paper / technique shows how text-to-image diffusion models can be used as zero-shot image-to-image editors, made possible by “inferring” the random seed of the input image!
Code implementation of “CycleDiffusion” here: GitHub - ChenWu98/cycle-diffusion

8 Likes
Thanks for sharing! I have an M2 MBA with 24GB RAM and I followed that guide but it takes 1m30s per image on my side, would be so awesome to get it down to 18s. Not sure what’s wrong with my setup but been using colab in the meantime.
I haven’t been able to get the notebooks working with the M1 - just getting noise (also issues with float64). Using cpu worked ok - but the speed dropped to about 2:40 per image. I switched over to my old box, a Linux machine with an 1080TI and the default dream.py images are produced in around 11 seconds - so I might see if I can get that working with the notebooks.
I could run all of the nb (except the last cell) with a linux 1080 8G and avoid a cuda error if I reduce the width by half
height = 512
width = 256
Didn’t get the same image as in the original nb, but pretty decent “half” images

2 Likes
Thanks - and I saw the same memory issues. The deep dive notebook also runs well on the 1080TI with some kernel restarts ;).
1 Like
 - Computerphile")
Sharing this video suggested by Tanishq on Twitter. Nice overview of SD although he does leave out some details, like adding noise on the encoded output by the VAE and not on the original image.
Overall nice video.
3 Likes
4 Likes
it’s possible to run all cells at one go on Nvidia 1080 8G with some minor modifications to the nb, mostly consisting of splitting up some large cells into smaller ones
Also, the smaller images look better if you use landscape height=256 and width=512


4 Likes
I was curious about training diffusion models for generating text, so have put together a minimal implementation here. This implementation can be used to train unconditional generative model of text, and also includes a small implementation of classifier guidance for conditional generation. Will be happy to answer questions about the implementation or diffusion models in general! Also includes a denoising/generative sampling loop visualization:

9 Likes