Even examples 3 and 4 can be simplified by using ColReader,
Instead of getting the image files -> extracting the filename -> looking up in the df -> getting the labels
you can use pref (prefix) argument in ColReader to append the parent path of the images to the ids (use suf to add extensions if needed) to directly read the images from the df.
1 Like
Example-3 is a deliberate attempt to show a different approach and example-4 cannot use ColReader because the path object consists of another column value inside the dataframe.
get_y = ColReader(1)/'imgs'/ColReader(2) is unacceptable thus the need for a custom function. 
1 Like
I see, my bad I didn’t look at the paths closely., I would have created new column by concatenating “classname” and “img” with a “/” in the middle, Anyway there are no unique solution to solve a problem I have a doubt though, why are you returning PILImage.create(path) in the get_paths_from_df function instead of just returning the path?
That I can agree to. We don’t need this @arora_aman because the ImageBlock takes care of this. It adds in a type transform that will call PILImage.create (so essentially you’re doing PILImage.create(PILImage.create()) I think) (Writing said article on this now to explain it)
1 Like
Ok, so I see we already have 4-5 people doing blogs… Maybe its worth creating a separate page wich is organized alphabetically and link all the blog pages ? My apologies if this exist =)
2 Likes
I made it, didn’t post much on it because I was waiting for this exact moment. Perhaps we can rephrase the top wiki to include everyones blogs… give me a few minutes
1 Like
great! thanks!
i am paying around with cnn feature extraction (hooks) to find similar images. is there a way to get a single decoded image (by id or path) from the dataloader that I can pass to my plt.imshow()? right now I just read the images again from the jpg file … but I guess there must be a more elegant way using fastai?!
You can do dls.dataset and pass in the index of it (or find the path/id, start by exploring there)
1 Like
Also you can straight up decode a batch of data. IE:
batch = dls.one_batch()
dec = dls.decode_batch(*tuplify(batch[0]), *tuplify(batch[1]))
thank you - using dls.dataset was easier than I thought  thank you
thank you
regarding decode_batch … I came across that code snippet when debugging show_batch but I couldn’t find a way to decode a special image (by id / path) using the batch methods.
Yeah it assumes you’ve already got it transformed in some way (also I think you can have a batch of 1 in with it)
I decided to follow @philchu suggestion and I’m building a fastai cookbook: fastcook
The quotes above describes exactly what I’m trying to do, a collection of recipes (snippets of code) on how to use some standard and not so standard functionality of fastai.
While this is a bit different from the work that is being done here, I think both ideas complement each other very nicely! I don’t want to go very “behind the scenes” in the cookbook, and instead I’ll be adding a lot of links to the blogs produced here, so if the reader wants to go more in depth, he can ![]()
There are two ways of exploring the cookbook, you can check the nbs directly or you can browse the generated docs. The docs have a sidebar and a search function (not working yet) so it should be easier to use. You can also link to specific parts of the documentation like: How to use callbacks? which can make it really easy to share specific recipes.
I hope this will be helpful to us all ![]()
![]()
3 Likes
Please add it to the blog thread @lgvaz
1 Like
Hi everyone, as some of you know I shared implementation of Devise in fastai here
I used
dls=ImageDataLoaders.from_lists(path="./",fnames=images,labels=img_vecs,y_block=RegressionBlock,bs=256,seed=123)
to read create the dataloader, here the images are a list of image paths, and the img_vecs is the list of word vector arrays of the labels.
I wanted to use the Datablock API here but couldn’t figure out how first, but after digging the source code I came up with
def _zip(x):
return L(x).zip()
dblock=DataBlock(blocks=(ImageBlock,RegressionBlock),get_items=_zip,getters=[ItemGetter(0),ItemGetter(1)],splitter=RandomSplitter(seed=123))
dls = dblock.dataloaders((images,img_vecs))
that is exactly what happens when you use ImageDataLoaders.from_lists, but I still don’t know why get_items=_zip is needed, I’m guessing the dataloader expects each item in x,y as inputs separately rather than a batch or list of them so that it can transform them properly, stack them and return as a batch? Can anyone explain me what is happening here?
2 Likes
I’ve allowed myself to add a debugging tutorial I had made to the wiki “Five ways to debug fastai”
2 Likes
I was going through 05_data_transform, and the get_files function is defined as follows:

Can someone explain this line of code:
if len(folders) !=0 and i==0 and '.' not in folders: continue
and why is it used?
Also why is the library os preferred over pathlib?
I’m working on some model training on a GCP instance which has 16gb GPU RAM and even though I restart my kernel I see that around 9gb ram is being used when nothing is running as shown below:
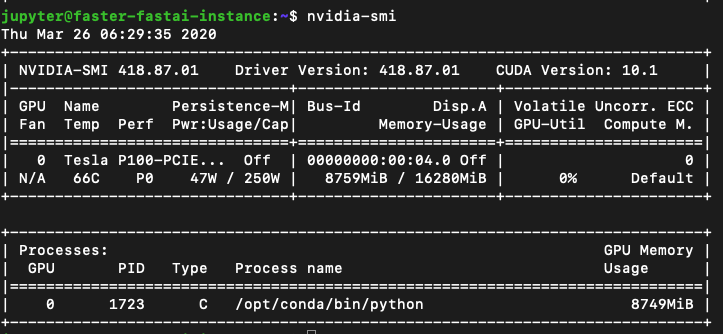
And when I actually start training a model, a parallel process starts up like this:
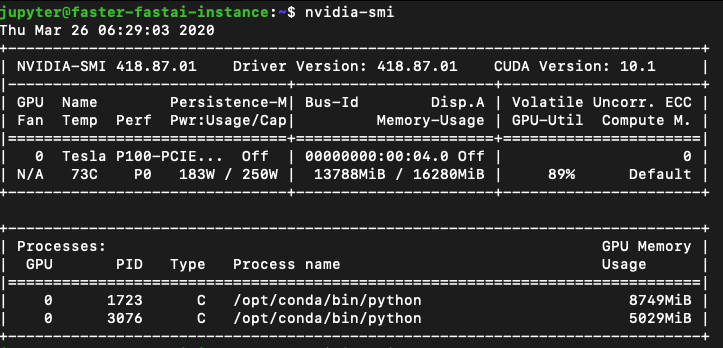
Is there a way to clear up GPU ram? I was able to run an xresnet50 model initially on a bs of 64 but now need to scale down to 16 due to this blockage of memory…
os used because of os.scandir - it is fastest way to iterate through folders. And Pathlib still used - Path is from pathlib.
1 Like
This looks like a second jupyter kernel running. Check if you have another notebook opened and shutdown its kernel.
If that fails you can restart jupyter or manually kill the python process.