You’ll probably need to use the norm-scaling idea from earlier in the thread too.
2 Likes
I’m on call this week for work so I haven’t had time to put it up yet, I promise to share it soon! I’m planning to share/present in the Cluster of Stars meetup this week as well
3 Likes
I had the same thought, with the attention mask is covering a larger prompt length for the negative prompt the weights for the ending tokens in the negative prompt should be influencing the result differently vs the end of text tokens.
2 Likes
Ahhh you are right. After running more experiments, even i am getting inconsistent results. It somehow appeared to work for me with the first few images.
1 Like
I am not sure if the model is explicitly understanding the strikethrough text as a negative prompt or if it is not understanding the strikethrough text and therefore ignoring the color and using a random color… Would be interesting feeding, for instance, a dog wearing a b̶l̶u̶e̶ hat, painting by grant wood and generate 100 images to verify that it is really understanding to avoid blue hats.
1 Like
Exploring using the img2img approach on video. Processing frames individually means very flickery video, so I’m using a tool called EBSynth to fill in between keyframes.
First test: https://twitter.com/JohnowhitakerA/status/1585833819479109632?s=20&t=PbxbLbNEDM5EXV5QW5KuXg
7 Likes
Using your notebook and looking at the tokens … Here are the tokens when space is used in the reversal versus when they are not. If you then use SD on the prompts; the “with spaces” version which ended up being letter tokens produces separated images. if you try this with any other separator or no spaces, it does not do this.



1 Like
I am working on generating images that could be used for promoting a dance instruction business. Here’s a couple images that I thought turned out well. I haven’t tried many prompts, but have been using a normalized decay on guidance. Just playing with that to try to improve the images and it’s going really well!


Lots more to try, but looking very promising!
3 Likes

Here’s my attempt to explain how to visualize CIFAR-10 images following course rules (no numpy etc.). It follows the lesson 1, but adds CIFAR-10 color images instead of black and white MNIST images. Work in progress…
According to dataset website, images are stored as 10000x3072 numpy array of uint8s. Each row of the array stores a 32x32 colour image. The first 1024 entries contain the red channel values, the next 1024 the green, and the final 1024 the blue. The image is stored in row-major order, so that the first 32 entries of the array are the red channel values of the first row of the image.
We will need to convert them to 32 by 32 by 3 array to display them with matplotlib.
To visualize this let’s say we have 2x2 pixel RGB image. We want to reorder the pixels so that the are stored as RGB RGB …

link to notebook: dlff/01_matmul-cifar.ipynb at main · miwojc/dlff · GitHub
i used excalidraw for the diagram
let me know your feedback, happy to change stuff to be more clear
7 Likes
reformatting the data must have been a good exercise ![]()
1 Like
Thanks. Yes it was!
1 Like
I’ve translated the CPU portions of 01_matmul.ipynb into Elixir and Livebook. I’ve also created a quick overview, blog post/notebook, for Python/Jupyter users to wanting to see how Elixir and Livebook are different.
The announcement blog post is at: Intro to Deep Learning from the Foundations, in Elixir. Livebook for Jupyter users is at Elixir/Livebook for Python/Jupyter Developers. Finally, the Elixir version of matmul is at Matrix multiplication from foundations
One item to note is that Livebook’s file format is markdown. My blog site is run off markdown files. So I copied the exported livebook into a .md markdown file, added a little bit of meta data at the top of the file, a Livebook launcher link, and then publish. To try out the blog post install Livebook and then click on the blue launcher button.
Feedback is welcome.
For sharp observers, yes, I’m mimicking Jeremy’s notebooks and also my son’s website, https://walkwithfastai.com/.
16 Likes
Hey everyone! I just published my first technical blogpost! It’s a documentation of my attempt to implement the DiffEdit’s paper’s first step, i.e, automatic mask generation for an input image using text prompts. It’s probably not the most advanced implementation on this thread, but it’s an honest effort. Please do take a read and let me know what you think:
https://jamesemi.github.io/blog/posts/DiffEditMask/
18 Likes
Hi all! I am pretty new to all this but I have been playing with non-linear guidance scales as I think some others have been. Here are some results of our astronaut of course, as well as a “photo” from the Hubble telescope and a classic Tom Cruise painting by Van Gogh.
The rows/cols show guidance of parameters of [4, 7.5, 10, 12.5] at the start (row) and end (col).
It looks like these parameters (and schedulers) can be manipulated to achieve particular styles, which is super interesting!



10 Likes
Wow this is huge! Really like the comparison between mutable and immutable approaches to matrix multiplication.
Has anyone tried scaling the the noise prediction? I tried applying small pred = pred * scaler multipliers here on a linear scheduler, and it has quite an impact as I guess larger values aggressively de-noise the image, making the result extremely stylised.
All of these were generated using the same parameters except the noise prediction “exaggerations”.

10 Likes
Bring paintings back to life.
I thought I would try generating a photo of Vincent Van Goph by starting with a photo of myself. What really helped here is the negative prompt. Without the prompt we end up with a painting.
prompt = ["photo, portrait, van gogh, detailed, sharp, focus, young, adult"]
negative_prompt = ["vincent, artistic, painting, drawing, style, blurry, old"]
start_step = 19
num_inference_steps = 17+start_step
guidance_scale = 7
generator = torch.manual_seed(33569313)
With and without negative prompt…



More fun this time mixing celebrities.
prompt = ["photo, portrait, elon musk, bradley cooper, detailed, sharp, focus, young, adult"]
negative_prompt = ["artistic, obama, facial hair, painting, blurry, old"]
start_step = 19
num_inference_steps = 85+start_step
guidance_scale = 7
generator = torch.manual_seed(33569313)

8 Likes
Happy Halloween, Generated using code adapted from this notebook.

prompt = [“Cartoon of a dog celebrating Halloween”]
negative_prompt = [“Diwali”]
num_inference_steps = 30
guidance_scale = 7.5
3 Likes
Here’s something I’ve been working on, it’s a project about extending stable diffusion prompts with suitable style cues using text generation model.
Here’s an example of how it works:
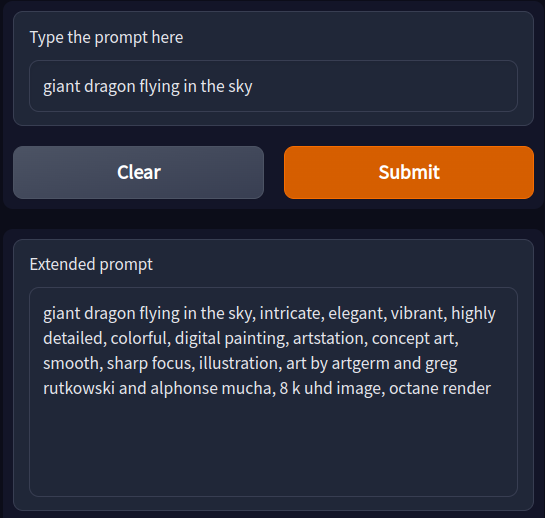
You could play with it on HuggingFace Space
For this, I trained a new tokenizer (pre-trained one butchered artist names) on the dataset of stable diffusion prompts, and then trained a GPT-2 model on the same.
Here’s the GitHub repo; it contains all the notebooks for training as well as the gradio app for it. I’ve also uploaded the model and the tokenizer on HuggingFace Hub.
I’d love to know what folks think of this, as well as any feedback or suggestions anyone might have.
6 Likes