I was not able to successfully get fastai working on Windows. When I installed it following the fastai instructions (with some tweaks) I was getting a warning that the cuda version that is installed does not work with the 3090. I have made several different attempts at this with different techniques with no luck. Below is the steps i followed in the latest attempt and I recorded everything I did this time.
If you have any other suggestions for benchmarking I’m happy to give them a shot. I was not able to find any settings in NiceHash to increase the Ram utilization from the last temperature test I ran. I have not tried installing WSL2 and going down that rabbit hole, and I’m trying to avoid that to keep my windows install lightweight as it’s not what I use for real AI work anyways.
Sorry for the late response, I didn’t get any notification for this post.
Trust me, WSL2 won’t mess with your windows installation, apart from occupying some disk space. I’d encourage you to install it, as it’s quite straightfoward to work with (no rabbit hole should happen).
When you don’t need it, just leave it shut off.
I just wanted to drop in here and let people know that tons of miners are either adding Copper Plates or Re-Pasting/Re-Padding their GPUs (or both).
The reason being is that there are tons of cards with crap thermal paste/pads. coolmygpu.com is a solid choice for copper plates (which can give a significant reduction in heat) (up to 34% heat reduction on VRAM)
As for creating a system that can handle multiple GPUs. I have to say that it is definitely a challenge. One that I myself run into. (With 4x 3080TI FEs, its hard to find something that is a turnkey solution)
Also, i see a lot of people mentioning the performance difference between the 3080 and the 3090. And you might want to dig into some nvidia spec sheets. NVIDIA RTX 30-series
The 3080 10gb model is only 320-bit memory interface/bandwidth w/ 272 Tensor cores. Meaning it can only handle about 720GB/s in memory bandwidth.
Vs the 3080 12gb and 3080TI 12GB model which both have 384-bit memory interface/bandwidth (900GB/s).
For reference the
3080 has 8704/8960 CUDA + 272 Tensor cores and 68 SMs
3080Ti has 10240 CUDA + 320 Tensor cores and 80 SMs
3090 has 10496 CUDA 328 Tensor Cores and 82 SMs
3090Ti has 10752 CUDA + 336 Tensor Cores and 84 SMs
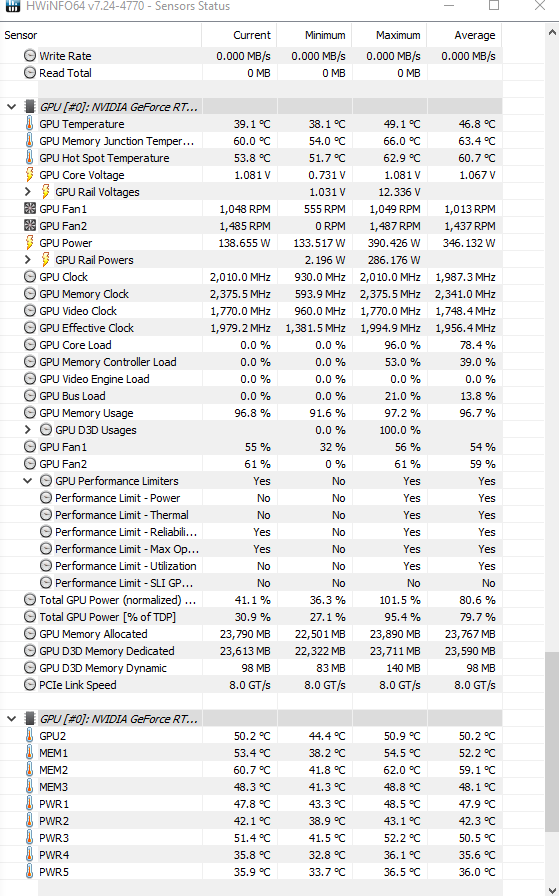
I finally got around to installing WSL2 and tested out my EVGA 3090 Hybrid Kingpin. I’m having pump issues with my other 3090. The kingpin seems to have excellent cooling. Probably overkill, but the memory temps (all temps really) when training the imdb nlp model from fastbook with fp16 and bs 384 are shockingly low. I was not planning on buying the kingpin as it’s quite a bit more expensive than the other options, but it was all I could get my hands on, though GPU availability seems to be much better now. They seem to have solved the backplate memory temp issue with this card variant.
I think that’s a good price. Particularly the bundle 3090+1600w psu.
Which kind of 3090 did you get?
Look, we can’t chase nvidia and its prices forever. I’m a bit sick & tired of this game. My A6000 has to last quite a few years, and I’m surely gonna skip this gen, maybe even 5000 gen. Consider that people is still doing DL rather gracefully on Pascal cards, and they are quite OK except for the memory amount. That was the point of getting 48gb VRAM.
Interestingly, an M1 Ultra chip is only 3 times slower than a 3090 with Pytorch.
These Apple silicons are on par with Ampere in terms of perf-per-watt, if not a tad better, and of course a Mac Studio with the M1 Ultra is much more silent than a 3090 and outputs less heat.
And, while costing as much as an A6000 (M1U, 128gb, 1Tb) it’s a whole computer, and a very good one.
Maybe the Nvidia monopoly, with its absurd prices, will end sooner than we thought, and not by the hand of AMD.
Honestly, if I had 3000 , I’d spend 2400 on a MBP 14" with 32GB RAM, and invest 600 in Jarvislabs or Paperspace for occasional A6000/A100 runs. Obviously, to get the most mileage for the money, I’d do the initial experiment on a smaller dataset on my local 1070ti or a free Kaggle GPU (which btw is equivalent to a local 1070ti with double the ram.) Once I get my ducks in order I’d fire up a beefier GPU on Jarvislabs or Paperspace, do the runs, save the results via wandb or something and stop the instances. This is more work on my part, but this also means I’d have a really nice laptop which is almost a 3050 equivalent (GPU performance wise) since pytorch performance will only get better from here on forward.
If I find that I’m really getting into this whole DL thing where having a local 3090 or equivalent will actually make a difference , then another 3000 - 4000 would be money well spent as an investment in a career where the ROI will be rather good in the larger scheme of things.
My personal perspective (but based upon experience): do not try to run anything serious on a laptop, even a good one. You’ll get mediocre performance, generate a lot of heat & noise and overcook the battery. And that’s kind of a waste on an expensive laptop.
Rather, rig a rubust desktop workstation and use that laptop to remotely log in into it (or into the cloud). For the same price, you’ll get better performance, less heat and noise, and you won’t cook the laptop.
Totally agree! I think I’m just rearing to get a laptop I don’t do anything serious with DL atm so using Paperspace/Jarvislabs and/or my local workstation with a GPU works fine for me. But I agree, for any type of serious stuff, laptop may not be the ideal platform (unless its less intensive exploratory stuff.)
Macbook pros are much more silent (at the expense of internal temps, they deem cpu temps >100C to be ok), but you’ll f*ck up the battery pretty soon all the same. Or even sooner. Two things, especially, kill li-ion batteries: fast discharge and heat.
Not to go OT but I agree, I really like the new M2 MBA design, but I don’t know about that price and with the extra power, it’ll probably throttle more. Though the prospects of holding more data in memory (upto 24GB ram) is attractive proposition.
My ideal MBA would’ve been this M2 MBA design but in 15" form factor. I love the MBA for it being so light but find that screen is too small, so I spend most of my time on my 2015 MBP i7 16GB … though performance wise a base M1 MBA blows it out of the water
Not real OTs, since this thread went for ‘general DL/ML-oriented hardware’ long ago
I don’t know guys. Maybe, or maybe not. I mean:
100 nits more is a thing for those who work outdoors, particularly during spring/summer.
+1 centimetre worth of screen diagonal is nothing to sneer at, given the device is even slightly lighter.
Unlikely to throttle, for the perf bump has been obtained with the same wattage (at least for the 8+8 version).
magsafe and a 1080p camera are nice things to have.
Likely to be more easily resellable within a couple years
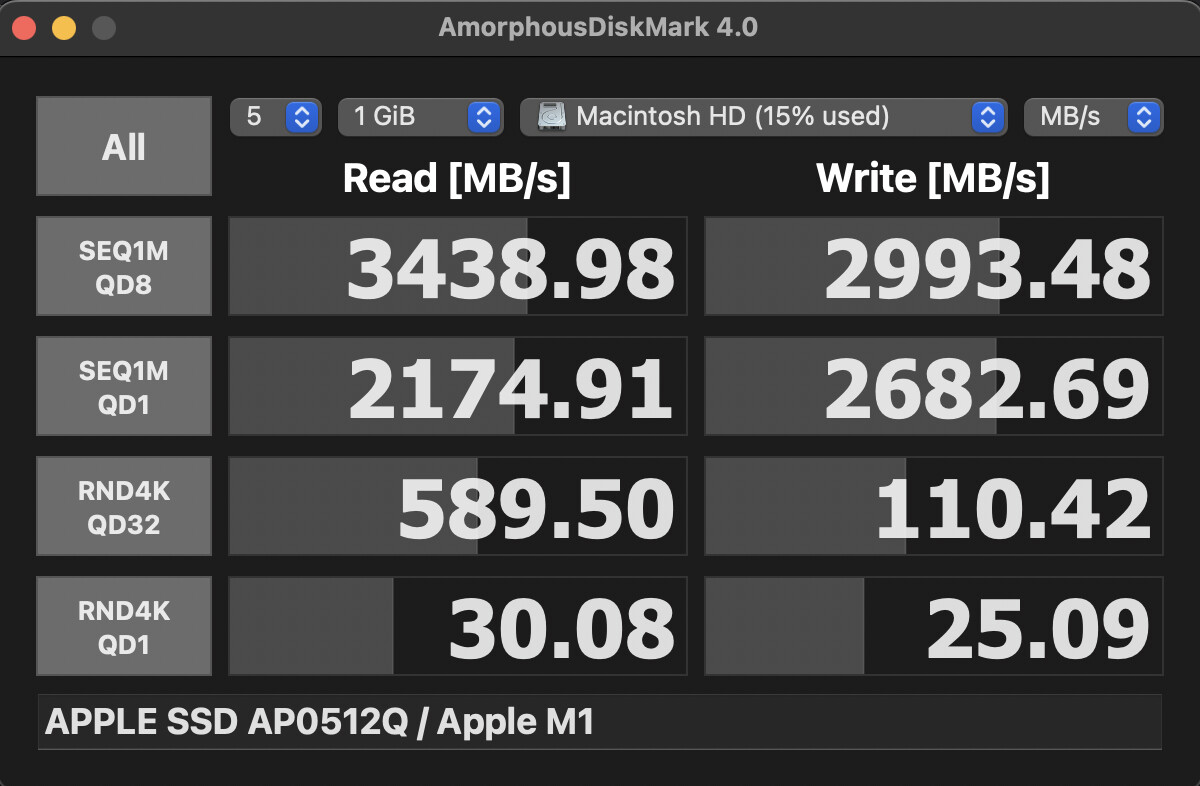
I really appreciate an ultra-portable device with 24gb ram. I don’t know if you have noticed, but once it starts swapping, MacOS takes a bigger performance hit w.r.t. PCs… Why? Well, look at this (from a 512gb M1 MBA):
As you may see, the random performance of these M1-integrated NANDs are pure and sheer crap. Like… Slower than a SATA ssd.
3090s at 1400$. Very good price. Still, I was very, very unhappy with the VRAM temps when I had the 3090s (granted, thermally speaking, managing 2 cards is quite a different business).
I hadn’t seen the disk numbers you posted but have been watching the single chip throughput fiasco on the M2 13" MBP. Hopefully apple will use both slots for the NAND chips in the MBA though my hunch is they wouldn’t.
I waited long time for the M2 MBA but after hearing about some throttling concerns on the M2 13" MBP (mainly related to apple’s weird fan curves imo) I was thinking a 14" might be worth the extra money especially since the differential is less if I were to go to a 512GB ssd and 24GB RAM. OTOH, I really appreciate the lightness of the MBA …
The points you made in your post have made me tilt back towards the MBA
Another couple points that you may want to consider:
The MBPs have air vents. In time, grime and dust will inevitably accumulate inside you macbook.
The MBP screen is mini-led. Gorgeous, but it suffers from blooming. if you are a developer working with dark backgrounds for hours, that’s a deal breaker. I’ve seen it on a 12.9 ipad pro, and it’s indeed very annoying.
I tried to realize homemade airducts using soft ducts made for other appliances.
An enormous amount of work and time wasted.
In the end, while these contraptions ameliorated the temps, they didn’t solve the problem. And don’t forget that you have to filter everything.
Note that the cooling systems of these cards already are insufficient to properly cool them. If you allow dust and grime to accumulate upon their heatsinks, that will worsen the situation.
Of course that’s just my experience. Maybe differently engineered custom solutions could succeed.
thanks for the awesome topic. I’ve read through all it and understand couple of things better, however since the original setup is 2 years old, I wonder, has anything changed in terms of things to buy?
I see that Intel i9 10x was recommended, however we have 12th gen now. Is it better? Is the AMD working better at this moment?
I am thinking about buying a new workstation with 2x RTX, since they’re cheap. I saw that blower-cards were mentioned, however they’re not for sale anymore. Is there any specific brand/type of GPU I should look into? Is TI version of RTX 3090 worth it? (I haven’t found Gigabyte Turbo in the country I live in).
What kind of PSU do we need for 2x RTX3090? Should 1200W be sufficient?
Can we do nv-link in 3090 - won’t the cards be too hot (even if limiting power to 80%?)
Mainly:
What kind of CPU in 2022? What about MBU? (if somebody recommends MBU, maybe even RAM and their speed?)
What abvout case? I can see that a lot of cases are not available unfortunately in my country.
I never had any problem with a HX1200i. But others had issues with other 1200W-class models. In any case, you need 1600W for two TIs.
NVLink does not affect the temperatures. Get the 4-slot spacing. Don’t expect substantial improvements if you’re just doing data parallelization.
Ideally, latest gen xeon and ecc ram with a generous amount of pcie lanes. If you cannot afford them, just get a 12th gen desktop processor upon a 8+8 lanes capable motherboard. AMD only if you can snatch them at bargain prices (still issues with MKL). Get twice the ram amount with respect to your total vram capacity.
If you want to save yourself some headaches, just get an used A6000, and you won’t worry about lanes or excessive heat output. Or parallelization. A 850W psu will be more than sufficient.
I never had any problem with a HX1200i. But others had issues with other 1200W-class models. In any case, you need 1600W for two TIs.
Thanks. The last time I built a PC was like 12 years ago, back then seasonic was probably the best one. Is it still the case?
NVLink does not affect the temperatures. Get the 4-slot spacing. Don’t expect substantial improvements if you’re just doing data parallelization.
That’s what I meant. I didn’t know whether nvlink works when there is space between the cards. I would like to use nvlink just in case that I need a memory > 24GB. I know that’s usually not the case, but I wanna be sure I can run something SOTA in 3 years as well…
Ideally, latest gen xeon and ecc ram with a generous amount of pcie lanes. If you cannot afford them, just get a 12th gen desktop processor upon a 8+8 lanes capable motherboard.
I am a bit lost - What kind of Xeon should I snatch? I prefer to have CPU ± 1000,- eur is that enough? I found out that the shops here have only 4 Xeons, one of them [Intel Xeon Silver 4310].
Ideally, I would like to have it sujmmed up to 6000,- with taxes. (3000 out of that are the two cards)
Can I just say the machine I built with your help has been absolutely humming along beautifully. I’ve been using it to do 3D segmentation of medical images to help in radiotherapy cancer treatment. Thank you!
My current workflow is hitting a CPU bottleneck (with all 24 pipeline processes maxed out at near 100%). Resulting in an approximate 3:1 ratio of GPU idle to full utilisation. (So a factor of 4 training speed reduction).
For a little bit of background, I am taking the 512x512x256 images and 512x512x256x40 segmentation encodings and scaling, cropping and augmenting down to training patches of 64x64x64 and 64x64x64x40 respectively with a batch size of 8 (4 per GPU). I have been using the multiprocessing toolbox so as to not hit the GIL and I have been using eliot to help flag hotspots for pipeline optimisation. The time costs right now are roughly split half and half between actually loading the efficiently cached representation from disk and then the call to skimage.measure.block_reduce. I haven’t yet looked into seeing if using something like JAX’s CPU module might solve the second half of this problem. I might also be able to undergo more clever caching to help with the first half.
Nevertheless, I had another thought, and I’d be keen for your opinion on whether or not it is a crazy idea. What if I built a separate threadripper server (or another high thread count CPU type) + raided NVMe for faster disk read that is solely dedicated to raw data scaling, cropping, and augmentation and then send the resulting training inputs over the wire. Is this a crazy idea?
Here are my back of the envelope numbers to make sure the ethernet connection won’t become the new bottleneck:
8x64x64x64 @ float32
8x64x64x64x40 @ uint8 (not one hot encoded, instead edge pixels are encoded such that the number between 0-255 details how much of a given voxel is within the segmentation)
The 2 GPUs currently run at full capacity for a little over 2 seconds running the training step, before subsequently waiting for the next pipeline item.
Therefore every 2 seconds I need the following amount of data to come through the connection:
So it doesn’t look like the ethernet would become the new bottleneck…
Is this idea of creating a standalone threadripper (or similar) + raided NVMe pipeline PC a good idea in your opinion? Or am I thinking something quite silly?
If a pipeline PC like this might be a good idea, do you have any recommendations for a build?
I have just started looking into this so no personal experience here yet, but have you looked at Rapids cucim at all? Rapids has GPU accelerated versions of a bunch of libraries which I believe includes the skimage function you’re referencing. This would take up GPU Ram but would probably be a lot faster.