May I ask which 3090 model you are operating, and which case? Thanks!
Thanks, I wasn’t aware of such memory-related issues.
Will run a furmark loop while monitoring with HWi 6.42, and let you know the results.
May I ask which 3090 model you are operating, and which case? Thanks!
Thanks, I wasn’t aware of such memory-related issues.
Will run a furmark loop while monitoring with HWi 6.42, and let you know the results.
I‘m using the Gigabyte 3090 Vision oc in a Fractal Define 7. now with 4 Arctic p14 pwm (3 Front blowing 1 back Pulling) running at Full Speed  . I use Ethminer as a Benchmark and Temps are better compared to the Stock fans. No thermal throttling with pl 280 (used to throttle before after a while).
. I use Ethminer as a Benchmark and Temps are better compared to the Stock fans. No thermal throttling with pl 280 (used to throttle before after a while).
So you watercooled it (assuming it stands for pure loop 280)?
Oh sorry, Power Limit 280.
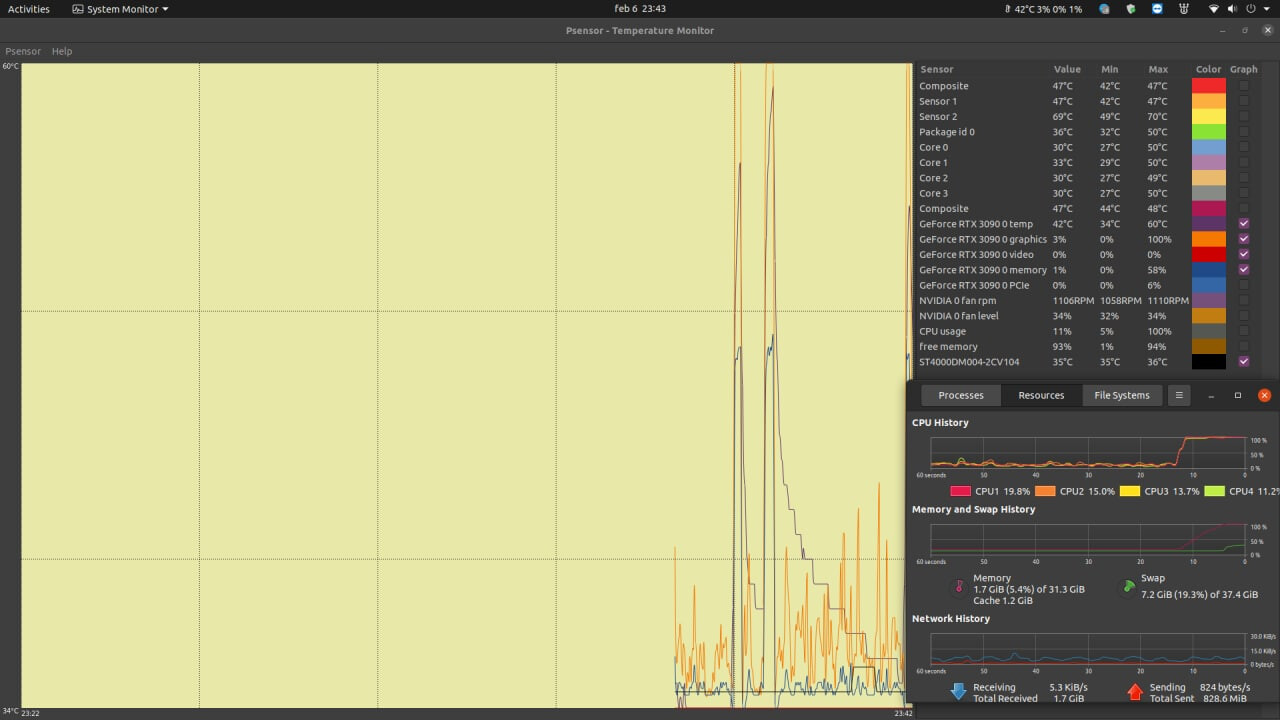
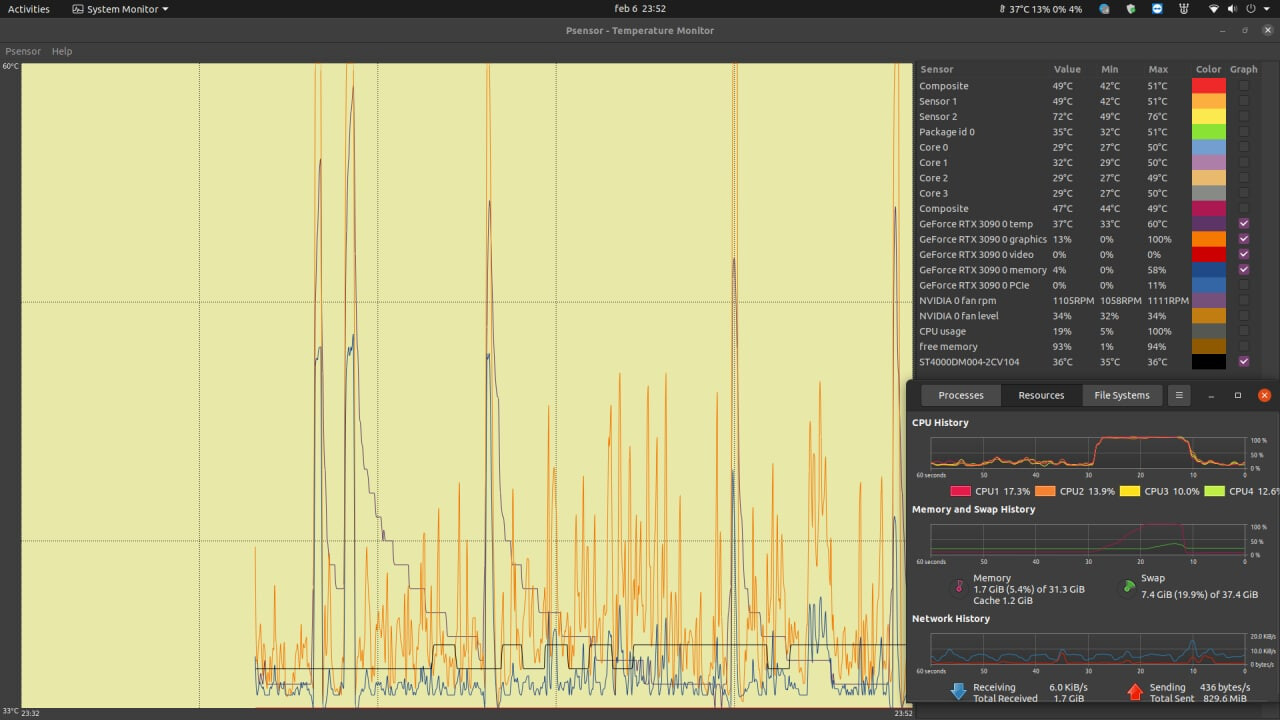
That’s the memory junction temps for my hottest GPU. The other one runs cooler by 1-2 C, but the memory temps are the same: 94C max.
The screenshot was taken during a Furmark session that was going on by ~10 mins.
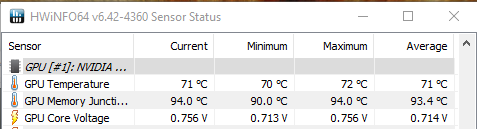
Please report your temps!
@balnazzar would you still recommend a 3090 FE for a 1 GPU setup? or given the most recent info you think it is not a great model for a DL server? I tend to run multiple experiment sequentially, so the GPU would tend to run for a few hours (sometimes days) no stop…
I have a 1080 (non Ti) which I might use for smaller experiments, until I can afford a second 3090 (FE or Turbo, depending on availability/price later this year).
I’m asking because I’m thinking to eating the markup and getting one now. Unfortunately, I can’t find a Turbo but I saw a FE that is within my price range.
If you will run a single gpu, the FE is great. Barely audible on full load. The downsides are that it’s heavy, very large, and needs at least one free slot on both sides.
So be sure to have sufficient case and motherboard clearances, particularly if you plan to add a second card at some point. If you want to nvlink them, it has to be another FE.
All in all, I prefer the FE to any other open-air model. Top-notch build quality and very silent. And it exhaust part of the hot air outside the case.
Mind that due to an awkward power connectors location, you will need more (upper) clearance than the sheer card’s height.
Last but not least, if you buy on ebay it’s better to avoid unsealed specimens and/or from vendors with just a few feedbacks.
Thanks for the tips @balnazzar. I watched a few videos and 2x3090 Turbo are really loud  Probably too loud for my taste. I’m wondering if the Turbo version is really necessary for a 2x3090 build or is more useful for 3x3090 builds (?).
Probably too loud for my taste. I’m wondering if the Turbo version is really necessary for a 2x3090 build or is more useful for 3x3090 builds (?).
If 2x3090 FE is a solid build for a DL server, I think I would go with that as they can be found for less money. I’m certainly only going to buy one for now, and evaluate later this year if it makes sense to buy a second 3090 FE. If I upgrade to 2x3090 I might also have to buy a new motherboard — I’m not sure if the Asus ROG STRIX Z370-E GAMING ATX LGA1151 motherboard can take two FEs.
I’m also getting increasingly concerned that buying the card on eBay/StockX might void the warranty. That would be a deal-breaker for me. On both websites, 3090 FE can be found at slightly less than $2,000, which is not so terrible compared to the prices I saw just a few weeks ago. Unfortunately, on Amazon they are still over $2,500 
I don’t think so… The second card will make the front panel connectors not accessible, as well as all the connectors below the last slot. Of course you can always use a riser, but at this point it’s unclear how it impacts performance (see Sanyam’s screenshot) and you won’t be able to Nvlink them.
in the end the Turbos are much more manageable, that’s their strong point.
Unclear… You can try and ask on Nvidia official forum, or send them an e-mail.
Hi there people, how can I troubleshoot restarts of computer while trainning? some times it is with an lr find, and others are with training, but I have also been able to run some trainings for a day.
ppl have said me that it probably is gpu temp, but if computer restart how to know if it was due to that (monitor gone after restart). OR how to check that it was about that, if I didnt ahve the monitor running?
Please post your configuration and the temperatures you are observing under load (cpu, chipset, gpus, mass storage devices).
Im not so sure how to collect that data to be saved even if computer restarts, I only collected some output from nvidia-smi with interval of 1 sec.
This are the specs
=== Software ===
python : 3.6.12
fastai : 2.1.11
fastprogress : 0.2.7
torch : 1.8.0a0+05c8cd7
nvidia driver : 460.32
torch cuda : 11.1 / is available
torch cudnn : 8005 / is enabled
=== Hardware ===
nvidia gpus : 1
torch devices : 1
- gpu0 : GeForce RTX 3090
=== Environment ===
platform : Linux-5.8.0-41-generic-x86_64-with-debian-bullseye-sid
distro : #46~20.04.1-Ubuntu SMP Mon Jan 18 17:52:23 UTC 2021
conda env : xla
python : /home/tyoc213/miniconda3/envs/xla/bin/python
sys.path : /home/tyoc213/miniconda3/envs/xla/lib/python36.zip
/home/tyoc213/miniconda3/envs/xla/lib/python3.6
/home/tyoc213/miniconda3/envs/xla/lib/python3.6/lib-dynload
/home/tyoc213/miniconda3/envs/xla/lib/python3.6/site-packages
/home/tyoc213/Documents/github/fastcore
/home/tyoc213/Documents/github/fastai
/home/tyoc213/Documents/github/fastai_xla_extensions
/home/tyoc213/Documents/github/pytorch
/home/tyoc213/Documents/github/pytorch/vision
/home/tyoc213/Documents/github/pytorch/xla
/home/tyoc213/miniconda3/envs/xla/lib/python3.6/site-packages/IPython/extensions
/home/tyoc213/.ipython
(gist because long log)
As you can see here from 13:51 to 14:03 I trainned a model, and let the computer there, then I started at 14:36 the notebook and it restarted without warning (and temp wasn’t hot at less from last line)
$ last -x | head | tac
reboot system boot 5.8.0-41-generic Sat Feb 6 07:22 - 11:48 (04:25)
tyoc213 :0 :0 Sat Feb 6 07:22 - down (04:25)
runlevel (to lvl 5) 5.8.0-41-generic Sat Feb 6 07:22 - 11:48 (04:25)
shutdown system down 5.8.0-41-generic Sat Feb 6 11:48 - 11:48 (00:00)
reboot system boot 5.8.0-41-generic Sat Feb 6 11:48 still running
tyoc213 :0 :0 Sat Feb 6 11:48 - crash (02:49)
runlevel (to lvl 5) 5.8.0-41-generic Sat Feb 6 11:49 - 14:38 (02:49)
reboot system boot 5.8.0-41-generic Sat Feb 6 14:38 still running
tyoc213 :0 :0 Sat Feb 6 14:38 still logged in
runlevel (to lvl 5) 5.8.0-41-generic Sat Feb 6 14:38 still running
Please issue: inxi -Fazy, and post the dump.
Other than that, you should need what follows:
lm-sensors and psensor
gpu_burn and stress
gpu_burn and stress simultaneously, using as many threads as you have, and ~75% of your physical memory.psensor to log the temps, or log them otherwise.If you have a BMC/IPMI, please look at the logs.
Just as a note, that’s why I recommend using ECC ram and a motherboard with IPMI. They make abnormal behaviour much easier to diagnose.
Last but not least, please provide some info about your PSU and about how you connected the card. I assume you did NOT daisy-chain two 8-pin connectors, and instead used two different cables connected to different outlets on the psu side, right?
Used this command line
stress --cpu 8 --io 8 --vm 4 --vm-bytes 12G --timeout 20s & ./gpu_burn -tc &
And passing -tc to gpu burn
Logs of sensors for first and second run https://gist.github.com/tyoc213/f102f5e1d3e83e9e8b95aed228653806
PSU should be a v1300-platinum
I used what I know as a “Y connector” which comes 2x(3x2+2) but on the same line, but this didn’t give much info
$ sudo dmidecode --type 39
# dmidecode 3.2
Getting SMBIOS data from sysfs.
SMBIOS 3.0.0 present.
Handle 0x0037, DMI type 39, 22 bytes
System Power Supply
Power Unit Group: 1
Location: To Be Filled By O.E.M.
Name: To Be Filled By O.E.M.
Manufacturer: To Be Filled By O.E.M.
Serial Number: To Be Filled By O.E.M.
Asset Tag: To Be Filled By O.E.M.
Model Part Number: To Be Filled By O.E.M.
Revision: To Be Filled By O.E.M.
Max Power Capacity: Unknown
Status: Present, OK
Type: Switching
Input Voltage Range Switching: Auto-switch
Plugged: Yes
Hot Replaceable: No
Input Voltage Probe Handle: 0x0033
Cooling Device Handle: 0x0035
Input Current Probe Handle: 0x0036
With those logs running, later will update to the “exact” nb that is causing a constant restart (Im also thinking that could be something of drivers and pytorch 1.8a wich I was testing because some nbs fails with latest drivers and 1.7, 1.8 should solve some incompatibilities for sm85)
How do you make gpu_burn run for 4 minutes? I only see the option for stress in timeout flag
Just ./gpu_burn 240s to have it run for 4 minutes.
I’m not getting that.
I was making reference to gpu’s connectors. You got two 8-pin connectors on the gpu. Each of them has to go directly to a psu outlet with its own cable.
If you used one cable (with two connectors) to connect the gpu to the power supply, that’s not good and will trigger the psu’s OCP.
Just received my RTX 3090 Turbo, and gosh… it is LOUD! 
What a convenience having 24GB of VRAM though. That is truly game changing.
Yes, and two of them are even more so. I’m starting to get sick tired of hearing them. Ordered two damn waterblocks, will let you know as soon as I find time and will for installing them.
I might too opt for liquid cooling… the noise is really unbearable when I need to take calls for work  let me know how it goes for you.
let me know how it goes for you.
@balnazzar Do you know if that invalidates the original Gigabyte warranty?