My attempt so far: https://github.com/KeremTurgutlu/deeplearning/blob/master/PORTO%20SEGURO%20WINNER%20SOLUTION.ipynb.
But got an error about invalid combination of arguments.
My attempt so far: https://github.com/KeremTurgutlu/deeplearning/blob/master/PORTO%20SEGURO%20WINNER%20SOLUTION.ipynb.
But got an error about invalid combination of arguments.
It’s a really old method I’m afraid. You should just train it with plain old SGD ![]()
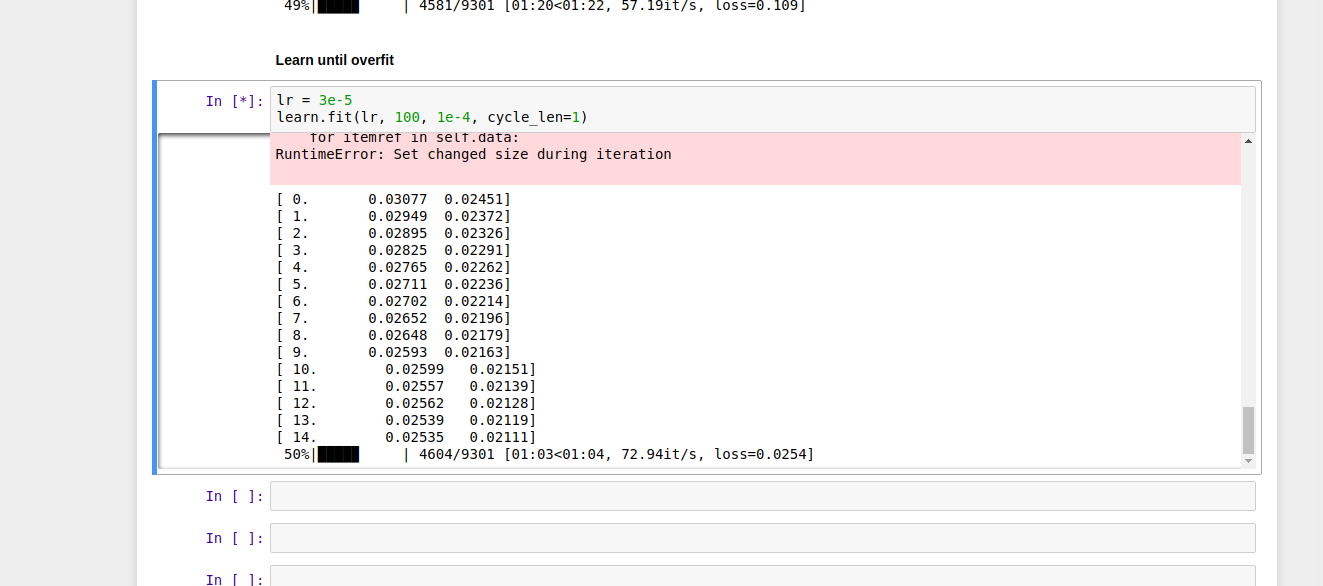
1000 epochs with bs=128, with ~1.5 M datapoints
0% 2/1000 [02:00<16:42:36, 60.28s/it] 
Hey @jeremy, I have a question which I’ve also asked to Michael, should we corrupt variables (denoising) at each batch with shuffle on the fly or before the training stage for only once ?
And also this confuses me lr decay is 0.995 isn’t it too much or is it ok because we have 1000 epochs?

Thanks
You should add data augmentation on the fly every batch.
For lr decay, 0.995^1000 = 0.006, which sounds about right as a scaling factor for LR for the last epoch.
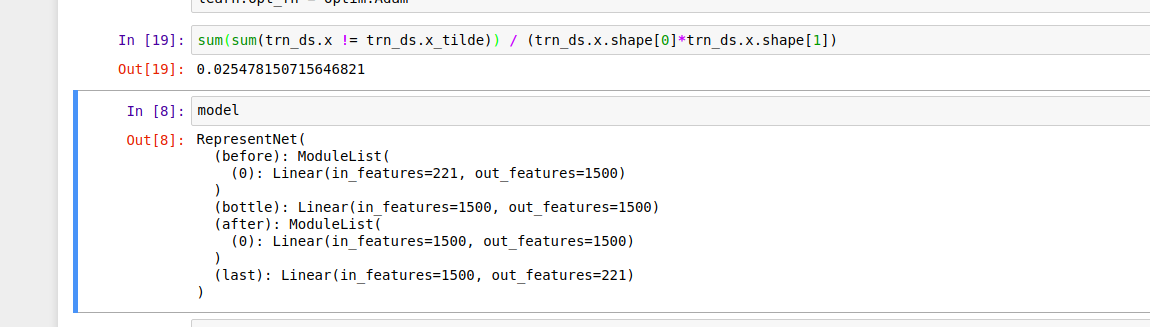
Any tips for not running out of memory or making the process more efficient when creating new dataset with size 1.5m x 4500 from activations ?
I am learning a lot about OOP, pytorch and fastai all together with this implementation attempt. But I think I may use tips in order to it better and hence learn even more. Here is the code I’ve written for DAEs:
https://github.com/KeremTurgutlu/deeplearning/blob/master/DAE.py
My only concern at this point is if I miss one single bit of the winning solution or interpret it in a wrong way, it will not get that good results 
For those who are interested in data augmentation for structured data:
I read through this thread and through Michael’s summary but I still conceptually do not understand what is happening here.
Why autoencoders? We use them essentially instead of feature engineering? Instead of doing something to the features manually, we use the activations that the autoencoder learns as they should be zoning in on the signal we are after, on the important parts?
Why data augmentation? Is this in any way related to the use of autoencoders or is this a separate issue? Is the data augmentation really as simple as just replacing 15% of values in one row of inputs with values from randomly selected rows? Autoencoder should still work without this but this just makes it work slightly bit better?
@kcturgutlu I would guess that the empirical “mixup” style augmentation from the winning solution would outperform exponential distribution noise - does that sound right to you? Have you tried both to compare?
-[quote=“radek, post:28, topic:8499”]
Why autoencoders?
[/quote]
They are used as a generative model, here to generate a noisy version of new data (adding noise is common in practice)
Yes think this process as automated feature engineering. Activations are basically linear and non-linear 2-3-many way interactions of features.
This part is also called denoising, which is a special case for DAE (Denoising Autoencoders). Michael used input swap noise and he mentions that choosing the denoising method is very crucial to a successful solution.
You can search for stacked autoencoders where activations are used as new features by another algorithm.
Yeap, pretty much. Although there are some distributional assumptions and a lot of trial and error.
If you don’t use denoising autoencoders but rather autoencoders while having activations layers that doesn’t allow your data to be compressed, then you will be in trouble since the network would learn just a 1-to-1 map which identity (because input == output). But if you have layers that compresses data you might get compression such that we see in SVD or PCA, which doesn’t require any denoising process.
All these been said, my aws instance $1 / hr still running and I think it will take a long time to see if it really works (I mean if I can get it work ![]() ) Sure I will let you know about it ! Hope this helps
) Sure I will let you know about it ! Hope this helps
I am currently running the autoencoder with input swap right now, as soon as I get the results and show that the new features indeed outperform raw data MLP approach. My next step will be to try other denoising functions too. I hope I am not missing anything though.
I am also kind of doing a hybrid study where I use his methods but also using Fast.ai functionalities like lr_find, wds and SGDR + Adam. So I am not sure how all this will effect the solution. But main idea is that we should any how get good representations after training it until overfitting.
@jeremy The part I am not sure is that how sensitive these representation learners are to denoising ratio, dropout, minima convergence, and so on… Anohter interesting thing I am observing while training the dautoencoder is that my training error is always greater than validation even after 50 epochs for example, so may be it really takes a very long time and very little improvements in optimization effects a lot. Although I can save it time to time while training and make predictions to see how sensitive optimization is to our final solution.
Kerem, thank you for your reply Really appreciate it.
I just googled it and it cannot be this simple. So a denoising autoencoder is just an autoencoder that has a lot of hidden units… we don’t want it to learn the identity transform… so we purpusefully corrupt parts of the input? And we want the autoencoder to learn the structure of the input to be able to recover it?! Is there all there is to this? Also, why would we want to use this instead of just bottlenecking the middle layer?
Either way, to use as features, we would only pick the middle middle layer activations, right?
So to paraphrase, Michael was feeding 15% random features into the denoising autoencoder and using the activations it learned to produce (as in, he trained it on the perturbed examples and then fed it real data and grabbed the activations)? BTW what about embeddings? Is this only useful for continuous variables and not used for categorical ones?
He both tried bottleneck and full activations in his experiments.
In his solution he uses one hot encoding then normalizes all data with rankgauss. Then all this data is fed into autoencoder. One thing we may try is to take categorical variables apart as embeddings to be concatenated with the rest of the data which would be learned with DAEs. I personally tried embeddings with raw data but it didn’t give any better results than one hot encoding, it may not be working for this dataset or I may not be able to train them well enough.
Here is Michael’s pipeline with his words:
pipeline is: raw->normalization(=RankGauss)->DAE->nn no normalization after DAE.
But may be the most important thing I’ve learned through reading his solution is that you nearly try everything before having a winning solution ![]()
Don’t think of it as denoising - think of it as data augmentation, just like we used in class. So if you don’t use enough augmentation, you’ll overfit the training set. Therefore, you can simply use the kinds of approaches to recognizing overfitting that we did in class - and use the appropriate amount of augmentation and dropout to maximize your validation accuracy.
(At least, that’s my expectation - I haven’t tried this particular approach so I’m replying on my intuitive understanding!)
Amazing conversation ITT Thank you Kerem again - this now makes much more sense to me, really appreciate your help.
No problem at all ! We are all learning together here
@jeremy This is how autoencoder learner looks like now, as I mentioned training seems to be following from behind. Does this mean it will take many epochs until convergence ?
I’d say you’re underfitting. Decrease dropout and augmentation lots so that you overfit quickly and a lot. Then gradually add more. (This is assuming you’ve got a bottleneck layer that’s small enough, mind you.)
With p = 0.15 denoising level I am getting very low difference between x_tilde and x (denoised and original input) - this is due to sparsity in data I assume. Also I don’t use any dropout.
fwiw thought I’d throw in results of a couple tests. When the Porto Seguro post first popped up I started playing a bit with autoencoders too. @kcturgutlu - I was finding it common to take > 100 epochs to converge with various techniques just on mnist. @radek - the limited testing I did showed much better results when the data was noised up and dropout used (on both constrictive and expansive architectures).
I have no idea if this is a one off or general finding, but the best performance I stumbled across was when I alternated between the noised up data and the non-noised data (4:1) with high dropout -> a standard denoising ae trained this way wound up performing as well as a convolutional ae on mnist (haven’t had time to try it with the cae). Mixing in the odd minibatch of non-noised data seemed to pop past plateaus (again, would need more work).
What I am hoping to test soon is a slightly different approach for augmenting structured data. The thought is to work with variational ae’s and / or adversarial ae’s. If you trained a vae on the structured data, since you learn distributions over the latent representation, it seems like it would be natural to augment by encoding a sample, randomly choosing features in the latent space and replacing them by sampling the learned distributions. A lot of the structured data I care about is time series - I’m hoping this allows one to noisy a series without losing it general / latent structure. Planning on trying this approach with the Porto Seguro data set.