I have uploaded another example here. It is a notebook that allows you to train your fast.ai model using SageMaker notebook instance then it shows how to upload the model to S3 and deploy as a SageMaker endpoint. You can deploy the endpoint locally to test as well.
There is no support for Elastic Inference with PyTorch models as far as I know. In any case you can launch an endpoint with a CPU based instance (instead of GPU). We recently announced support for ONNX models and the Elastic Inference. An example is shown here.
@matt.mcclean Thanks for providing this info. After reviewing it, it seems we jump through a lot of hoops to use SageMaker’s predefined interface and I am not so sure it can scale since it did not support EI. Do you think it is better off to package them (fastai/model/data) in docker and deployed with lambda/API gateway? I might be wrong here. Please feel free to correct me
Not sure what you mean by it won’t scale as it doesn’t support EI. It will depend on the type of fast.ai model and your latency and cost constraints. You can run fast.ai models with non-GPU based instances (e.g m4, m5, c5 etc.) but you may have increased latency on your inference calls compared to a GPU or EI based instance.
For sure you can scale out the SageMaker endpoints horizontally using the Autoscaling feature.
I would recommend you testing out your model with different instance types to find the optimum one taking into consideration both performance/latency and costs
I figured out the issue, other people in my company also use sagemaker and they’re trashing my envs. The “Python3” environment already existed and so the Lifecycle scripts did not configure that environment correctly.
Is there anyone who can tell me how to modify my start up scripts/etc to provide a clean environment and hopefully name it something unique so other people will not trample it? I did quite a bit of googling on conda/source/activate/etc but I honestly can’t make it all work on my own, I’m not super familiar with nix environments and this is the first I’m looking at python, which google is telling me has a pretty rough time with these exact problems.
The instructions to setup a SageMaker notebook are now even easier and faster. We can now provision all the resources in a CloudFormation script avoiding manual steps.
I setup sagemaker, I was very careful to start and stop instance. I did not even use it much as I got working with something else. Yet I just got a 300$ bill. I am not even sure why. There is no detail of what exactly caused it. I thought I was being very careful: how could I have run in such costs without my even noticing?
Anyway, one piece of advice: set a budget limit alarm!
I think personally when you first start using sagemaker you should be alerted by default. Up to you to raise your budget alarm…
Hi I have tried to follow the Sagemaker setup here: https://course.fast.ai/start_sagemaker.html I think that AWS has changed their UI and that the setup instructions are (perhaps) no longer valid. AWS keeps prompting me for some S3 bucket where the cloud formation template is stored.
Hey @matt.mcclean, would you happen to have any examples on distributed or parallel training with SageMaker and Pytorch/fast.ai? I made some attempts with nn.DataParallel(model) on an ml.p2.8xlarge, but it actually made things slower. I’m not sure if it is because I set the model to the devices incorrectly (tried following this code: https://pytorch.org/tutorials/beginner/blitz/data_parallel_tutorial.html#create-model-and-dataparallel) or because my model architecture (I’m doing some negative sampling).
I am facing network latency when using aws java sdk… can anyone help me in reducing it.
long invokeStart = System.currentTimeMillis();
InvokeEndpointRequest request = new InvokeEndpointRequest();
InvokeEndpointResult p = amazonSageMakerRuntime.invokeEndpoint(request.withEndpointName("<endpoint>").withAccept("application/json").withContentType("application/json").withBody(ByteBuffer.wrap(data.getBytes())));
System.out.println("Invoke time : "+(System.currentTimeMillis() - invokeStart));
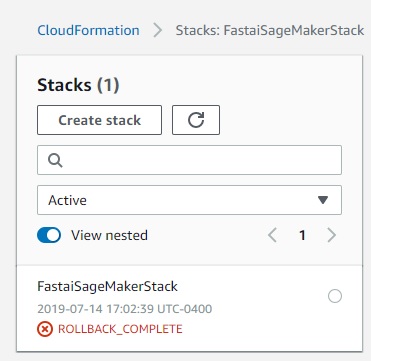
Hello, I followed the instruction on setting up the stack in Cloudformation, but receiving the error msg’ROLLBACK_COMPLETE’ , no notebook has been created in SageMaker. Could anyone advise me on the solution? Thanks!
Hi - looking for help with an ImportError: … undefined symbol message. Used this tutorial, https://course.fast.ai/start_sagemaker.html, to create an instance. Going through the 00_notebook I ran the cell
# Import necessary libraries
from fastai.vision import *
import matplotlib.pyplot as plt

 Also, I have faced the same problem as
Also, I have faced the same problem as