@piaoya
Hi Sanyam,
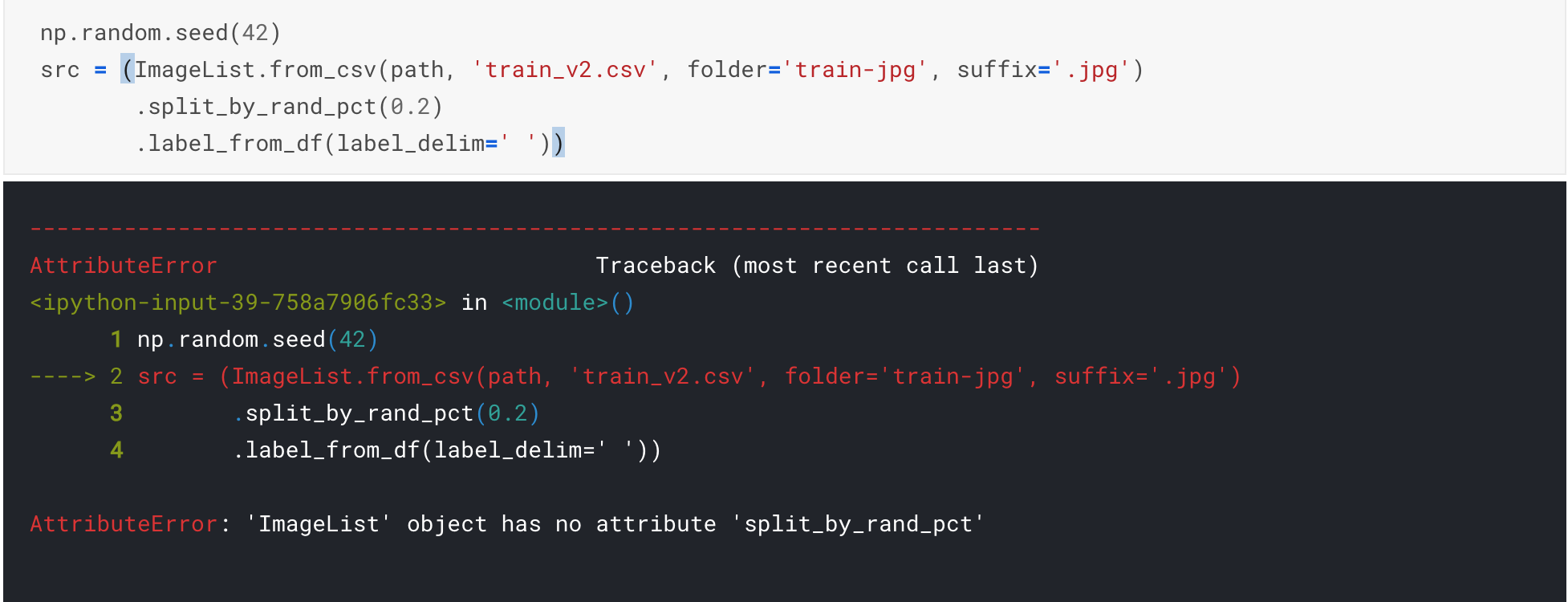
I believe something has changed after kaggle updated their p100 or fastai library (just checked, now is under 1.0.46).
Now even if you set model_dir = ‘writable directory’
learn.lr_find() will crash.
I traced to the fastai library, it seems to me that during the training, the purge() method calls torch.save(), and self.path/self.model_dir end up trying to save to …/input/purge-tmp.pkl.
I am still looking for the root cause of this issue, but I guess is the self.path/self.model_dir part, it ends up using self.path, which is …/input in kaggle kernels. (assuming most people loads data at …/input, so you have self.path = ‘…/input’, self.model_dir = ‘/kaggle/model’, but somehow self.path/self.model_dir returns …/input)
But yup, when creating learner and set model_dir to writable directory no longer work…
Currently I use piaoya’s way to move around data…
Here is the trace:
OSError Traceback (most recent call last)
<ipython-input-32-d81c6bd29d71> in <module>()
----> 1 learn.lr_find()
/opt/conda/lib/python3.6/site-packages/fastai/train.py in lr_find(learn, start_lr, end_lr, num_it, stop_div, wd)
30 cb = LRFinder(learn, start_lr, end_lr, num_it, stop_div)
31 epochs = int(np.ceil(num_it/len(learn.data.train_dl)))
---> 32 learn.fit(epochs, start_lr, callbacks=[cb], wd=wd)
33
34 def to_fp16(learn:Learner, loss_scale:float=None, max_noskip:int=1000, dynamic:bool=False, clip:float=None,
/opt/conda/lib/python3.6/site-packages/fastai/basic_train.py in fit(self, epochs, lr, wd, callbacks)
180 if defaults.extra_callbacks is not None: callbacks += defaults.extra_callbacks
181 fit(epochs, self.model, self.loss_func, opt=self.opt, data=self.data, metrics=self.metrics,
--> 182 callbacks=self.callbacks+callbacks)
183
184 def create_opt(self, lr:Floats, wd:Floats=0.)->None:
/opt/conda/lib/python3.6/site-packages/fastai/utils/mem.py in wrapper(*args, **kwargs)
87
88 try:
---> 89 return func(*args, **kwargs)
90 except Exception as e:
91 if ("CUDA out of memory" in str(e) or
/opt/conda/lib/python3.6/site-packages/fastai/basic_train.py in fit(epochs, model, loss_func, opt, data, callbacks, metrics)
101 exception = e
102 raise
--> 103 finally: cb_handler.on_train_end(exception)
104
105 loss_func_name2activ = {'cross_entropy_loss': F.softmax, 'nll_loss': torch.exp, 'poisson_nll_loss': torch.exp,
/opt/conda/lib/python3.6/site-packages/fastai/callback.py in on_train_end(self, exception)
289 def on_train_end(self, exception:Union[bool,Exception])->None:
290 "Handle end of training, `exception` is an `Exception` or False if no exceptions during training."
--> 291 self('train_end', exception=exception)
292
293 class AverageMetric(Callback):
/opt/conda/lib/python3.6/site-packages/fastai/callback.py in __call__(self, cb_name, call_mets, **kwargs)
212 "Call through to all of the `CallbakHandler` functions."
213 if call_mets: [getattr(met, f'on_{cb_name}')(**self.state_dict, **kwargs) for met in self.metrics]
--> 214 return [getattr(cb, f'on_{cb_name}')(**self.state_dict, **kwargs) for cb in self.callbacks]
215
216 def set_dl(self, dl:DataLoader):
/opt/conda/lib/python3.6/site-packages/fastai/callback.py in <listcomp>(.0)
212 "Call through to all of the `CallbakHandler` functions."
213 if call_mets: [getattr(met, f'on_{cb_name}')(**self.state_dict, **kwargs) for met in self.metrics]
--> 214 return [getattr(cb, f'on_{cb_name}')(**self.state_dict, **kwargs) for cb in self.callbacks]
215
216 def set_dl(self, dl:DataLoader):
/opt/conda/lib/python3.6/site-packages/fastai/callbacks/lr_finder.py in on_train_end(self, **kwargs)
43 # restore the valid_dl we turned off on `__init__`
44 self.data.valid_dl = self.valid_dl
---> 45 self.learn.load('tmp')
46 if hasattr(self.learn.model, 'reset'): self.learn.model.reset()
47 print('LR Finder is complete, type {learner_name}.recorder.plot() to see the graph.')
/opt/conda/lib/python3.6/site-packages/fastai/basic_train.py in load(self, name, device, strict, with_opt, purge)
241 def load(self, name:PathOrStr, device:torch.device=None, strict:bool=True, with_opt:bool=None, purge:bool=True):
242 "Load model and optimizer state (if `with_opt`) `name` from `self.model_dir` using `device`."
--> 243 if purge: self.purge(clear_opt=ifnone(with_opt, False))
244 if device is None: device = self.data.device
245 state = torch.load(self.path/self.model_dir/f'{name}.pth', map_location=device)
/opt/conda/lib/python3.6/site-packages/fastai/basic_train.py in purge(self, clear_opt)
287 state['cb_state'] = {cb.__class__:cb.get_state() for cb in self.callbacks}
288 if hasattr(self, 'opt'): state['opt'] = self.opt.get_state()
--> 289 torch.save(state, open(tmp_file, 'wb'))
290 for a in attrs_del: delattr(self, a)
291 gc.collect()
OSError: [Errno 30] Read-only file system: '../input/purge-tmp.pkl'