bind: Permission denied
channel_setup_fwd_listener_tcpip: cannot listen to port: 8080
Could not request local forwarding.
I’ve also run netstat -lep --tcp to check to make sure nothing else is listening on my local 8080 and nothing is.
This happened when I was restarting an instance and I also tried creating another one from scratch and got the same error. I think I’ve followed all the set up instructions correctly, but can anyone help me figure out where I’ve gone wrong?
Not sure if this is relevant, but when I go to localhost:8080/tree I get the following returned:
{
path: "$",
error: "resource does not exist",
code: "not-found"
}
SOLVED
Rookie error - leaving here in case useful to anyone else. I had a docker container running that was listening on local 8080 that for some reason didn’t come up when I ran the netstat command. Once I stopped the container, I was able to establish the tunnel.
However, the notebook is running really slow compared to some of the times shown in the notebook. I am running lesson 3 and after updating the model to take the full image size 256x256, it is taking nearly 7mins to fit one epoch.
During training I ran nvidia-smi and it showed this:
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 410.104 Driver Version: 410.104 CUDA Version: 10.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla P4 Off | 00000000:00:04.0 Off | 0 |
| N/A 85C P0 59W / 75W | 7597MiB / 7611MiB | 100% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 2951 C /opt/anaconda3/bin/python 7587MiB |
+-----------------------------------------------------------------------------+
I also ran import torch; print(torch.cuda.is_available()) and this returned True.
Why is this still so slow? Am I missing something or is this just the setup on google cloud?
I’ve just begun this course today, and I’m having trouble setting GCP… I followed the help greatly exposed. However, I still have two problems during step 3 (creating an instance):
I have this error message `ERROR: (gcloud.compute.instances.create) Could not fetch resource:
Quota ‘GPUS_ALL_REGIONS’ exceeded. Limit: 0.0 globally.` I did increased the quotas as advised (up to 32!) but this message is still displayed anytime I try to create an instance.
I have this warning message `WARNING: Some requests generated warnings:
Disk size: ‘200 GB’ is larger than image size: ‘30 GB’. You might need to resize the root repartition manually if the operating system does not support automatic resizing. See https://cloud.google.com/compute/docs/disks/add-persistent-disk#resize_pd for details.` However, when in the code suggested for the step 3 I replace 200GB by 30GB, I have another warning message telling me it may be insufficiant.
Does anyone have any idea? I’ve been trying since yesterday, and this is getting a bit annoying…
Disk size: ‘200 GB’ is larger than image size: ‘30 GB’. You might need to resize the root repartition manually if the operating system does not support automatic resizing. See https://cloud.google.com/compute/docs/disks/add-persistent-disk#resize_pd for details.
I’m having issues connecting to Jupyter notebook after successfully connecting to my GCP instance. I’m following the ‘Returning to GCP’ document at https://course.fast.ai/update_gcp.html. I ran gcloud compute ssh --zone=us-west1-b jupyter@my-fastai-instance-p100 -- -L 8080:localhost:8080. I was then able to successfully update the course repo and fastai library. But when I try to open http://localhost:8080/tree in a broswer, I get Connection refused. I’m on a Mac. Could someone point out what I’m missing?
Hi. Like @Shubhajit I’m running into SSH problems with GCP.
When I’m running the nn-vietnamese.ipynb notebook from the nlp-course of Rachel on my GCP instance, everything goes fine until the training of the learner: after some time (each time different), the connection to my instance is broken by GCP (the instance keeps running) and I get the following error message in my Ubuntu terminal (I’m using Windows 10):
Connection reset by xx.xx.xxx.xxx port 22
ERROR: (gcloud.compute.ssh) [/usr/bin/ssh] exited with return code [255].
@pierreguillou I found some temporary workaround here, changing the network (mobile hotshot - > public wifi) helped most of the times. Don’t know why this is the case, but it’s working.
First I thought my ISP was blocking the port (22), but later discovered, it wasn’t.
This is frustrating!
I would really appreciate if someone from GCP team will look at it.
Hello @Shubhajit. Thank you for your answer, but in my case, I use my Internet connection at home (not a cellular connection or a public wifi connection). But what your experiences mean is that the lost of SSH connection would come from the ISP, not from the GCP. If this is the case, it would mean that there is no way to use a cloud GPU to train large DL models such as Language Model, at least in the conventional way (ie, from home computer):
If true, it would be better to launch the connection to the GCP instance not from my home computer terminal but from an online terminal (to avoid to get my ISP between my instance ).
An idea that makes sense? Possible? Cloud Shell on GCP could allow to do that?
is either wrong or outdated (meaning that GCP became vastly more expensive, and the guide needs to be updated). As a matter of fact, the price of the standard compute option is estimated to be (80 hours of homework plus the 2 hours of working through each lesson and 2 months of storage):
Standard Compute + Storage : (80+27)$0.38 + $9.6*2 = $54.92
per month. Since the course duration is 2 months (in the above scenario), the total cost will be 112.9$. The main error in the https://course.fast.ai/start_gcp.html estimate is the cost of storage per month, which is 40.8$, not 9.6$.
I think in the fastai docs in the GCP guide the ‘Standard Provisioned Space’ was chosen, whereas you chose the SSD Provisioned Space, which is more expensive. @AndreaPi Here is the estimate for the standard option for the region you picked: (Note: I think I did not pick the same estimated using time, so my price is a bit higher than yours because of the slightly higher costs for the instance which was around 17 USD)
Did your command activate the SSD or the standard disk option?
This is exactly the same command as given in the fastai docs for GCP, so there are only two possibilities:
either the fastai docs are wrong, and the command above activates an expensive SSD disk
or the command is correct, and GCP is cheating, because it’s charging me the rate of a SSD permanent disk, even though I activated a standard permanent disk.
I’m not sure what to think. Which command did you use, and how much does it cost you for day when you don’t use the VM, I.e., what’s the storage coat you’re incurring?
Hi AndreaPi,
I just set my fastai project at GCP up and I used the exact same commands stated in the fastai docs for GCP. When I look at my ‘Compute Engine’/‘Disks’ for my project, it says ‘Type: Standard persistent disk’ with the size of 200 GB. There aren’t any costs showed yet, but I will tell you as soon as I see them in my account.
What does the disk type for your instance say - is there something mentioned like ‘SSD’ ?
I think I found the issue: if I’m correct, then the GCP fastai docs are essentially correct and no modification is needed.
My boot disk type is “Standard persistent disk”, size 200 Gb
It appears that the monthly cost is deduced upfront from your free credits as soon as you create the instance, rather than gradually each day (so, by deleting and recreating the instance, I payed twice ), thus I overestimated the cost. The reason for the misunderstanding is connected to this:
The costs are actually already there but you don’t see them because of the 300$ free credits. To show the actual costs, go to Billings>Reports and uncheck “one time credits” in the bottom right corner. You’ll see how much you actually consumed (of your free credits) until now. If you can do this check and let me know what you see, that would be great.
Nice, thanks for that tip! Now I can see the costs, they are 0.76€ right now, but I have not used the instance for more than 2 hours or so I guess up until now
I also found that in the documentation of the API it says the default option for disk type is ‘pd-standard’, so the commands shown in the fastai course docs should correctly create such a disk
Right now I am trying to detach the boot disk and create a second CPU-only instance with that disk, so that I can use this disk for both instances and don’t get charged for GPU time when I don’t need that. This strategy was mentioned in some posts within this thread, so I hope this will work
Thus yesterday, training seemed to be quite slow when I was experimenting with the course notebooks I think I will have to check if the GPU is running or not.
@noskill That’s a neat procedure! One question: I just created a CPU+GPU instance as shown in the fastai course docs with 200GB boot disk. I guess it is not possible to detach this boot disk and attach it to a CPU only instance like you mentioned because the disk source image is the ‘pytorch-latest-gpu’ (and for for a CPU-only instance the boot disk image probably has to be 'pytorch-latest-cpu)?
Thus, you are writing of an ‘external disk’: are your CPU and GPU instances having a small boot disk size (like 10GB or so) and are sharing a larger external disk which is attached and detached as needed?
So, I had the SSH passphrase issue.
This link solved the problem. Took a few hours of trying various solutions to get this final solution.
Feel free to ask any dobt.
The last couple of weeks, my instances have been preempted with such regularity to the point of making them almost useless. Has anyone else experienced this??
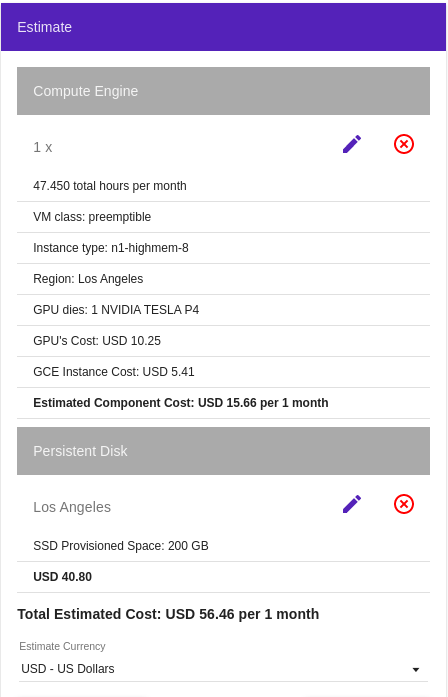
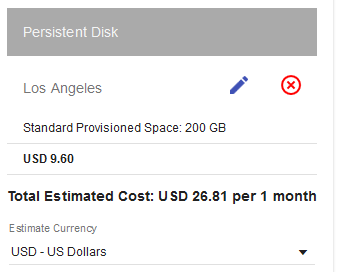
 (Note: I think I did not pick the same estimated using time, so my price is a bit higher than yours because of the slightly higher costs for the instance which was around 17 USD)
(Note: I think I did not pick the same estimated using time, so my price is a bit higher than yours because of the slightly higher costs for the instance which was around 17 USD)


 I think I will have to check if the GPU is running or not.
I think I will have to check if the GPU is running or not.