There were a lot of questions about partial dependence and how to build some of the plots, so I’m opening up a topic to create a space for discussion, sharing insights, and asking “dumb” questions here.
As Jeremy mentioned in class, this is a tricky topic to internalize and even trickier to explain. Please feel free to use this space to confirm what you know, clarify what you don’t know, or to help others gain clarity.
I can start! I helped answer these in person, but other people (hi friends!) may have better explanations or the same questions. Let’s archive our collective knowledge here.
I’ll be using @timlee 's notes as my reference text for the code
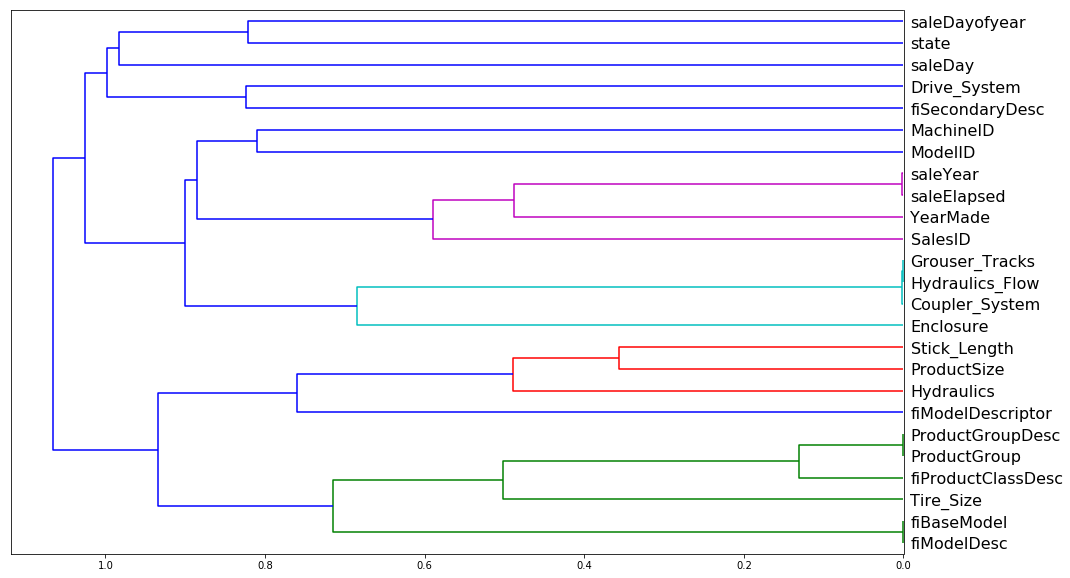
There was a question about the dendograms. Here’s the relevant code:
corr = np.round(scipy.stats.spearmanr(df_keep).correlation, 4)
corr_condensed = hc.distance.squareform(1-corr)
z = hc.linkage(corr_condensed, method=‘average’)
fig = plt.figure(figsize=(16,10))
dendrogram = hc.dendrogram(z, labels=df_keep.columns, orientation=‘left’, leaf_font_size=16)
plt.show()
How/why was that dendogram that built? Did we just pass in data frame df_keep before we passed the same data to our random forest regressor (RFR)? And then we decide which columns might be dropped? Or do we do pass our data first to RFR get the feature importance first and then pass the same data we fed to the RFR to double check the results? Where does building a dendogram happen in my order of operations with building or interpreting a tree?
Maybe the questions about the dendogram are actually proxy questions about the Spearman correlation? Feel free to provide the intuition about the Spearman correlation as well! Perhaps the question is in what part the of the random forest regressor workflow, does one do this analysis?
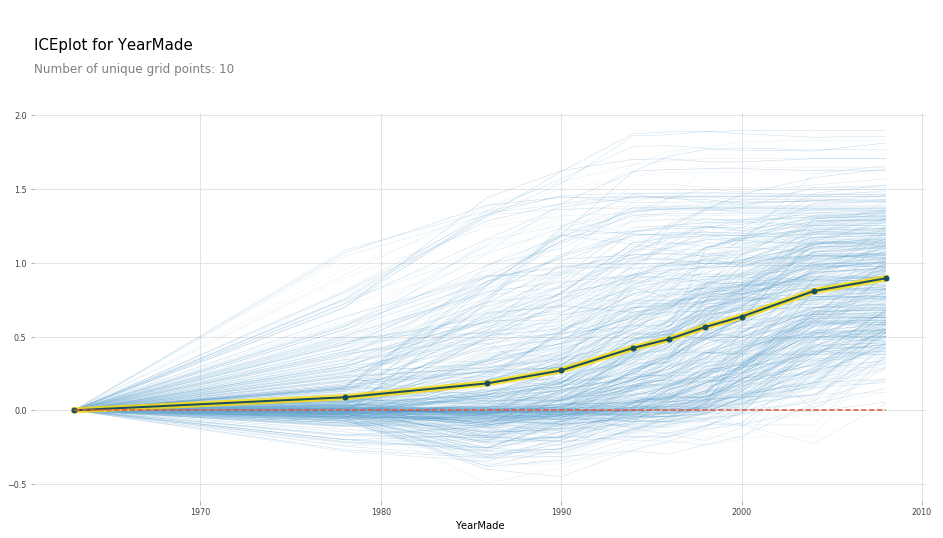
There was another question about the blue to yellow chart as part of types of plots for partial dependencies. What do those color bands mean? What exactly is being plotted?
If I’m rephrasing the questions wrong, original questioners please feel free to correct my misunderstanding!
Thanks in advance in helping your colleagues and thanks for using this topic as a way to practice your technical communication skills!



{kind=link}
{kind=link}