Yes, it worked well ! Thanks again.
I’ve used them to continue with the notebook before I found a solution to compile fasttext. And anyway it’s a lot smaller than the fasttext files for wiki models in EN and FR (that I even not finished to download yet).
Hi @Chris_Palmer. You can see in commits that there are only few commits, some fix and updates on docs so no new features. IMO you can definitely use the master branch. I do not get any issue with it for now.
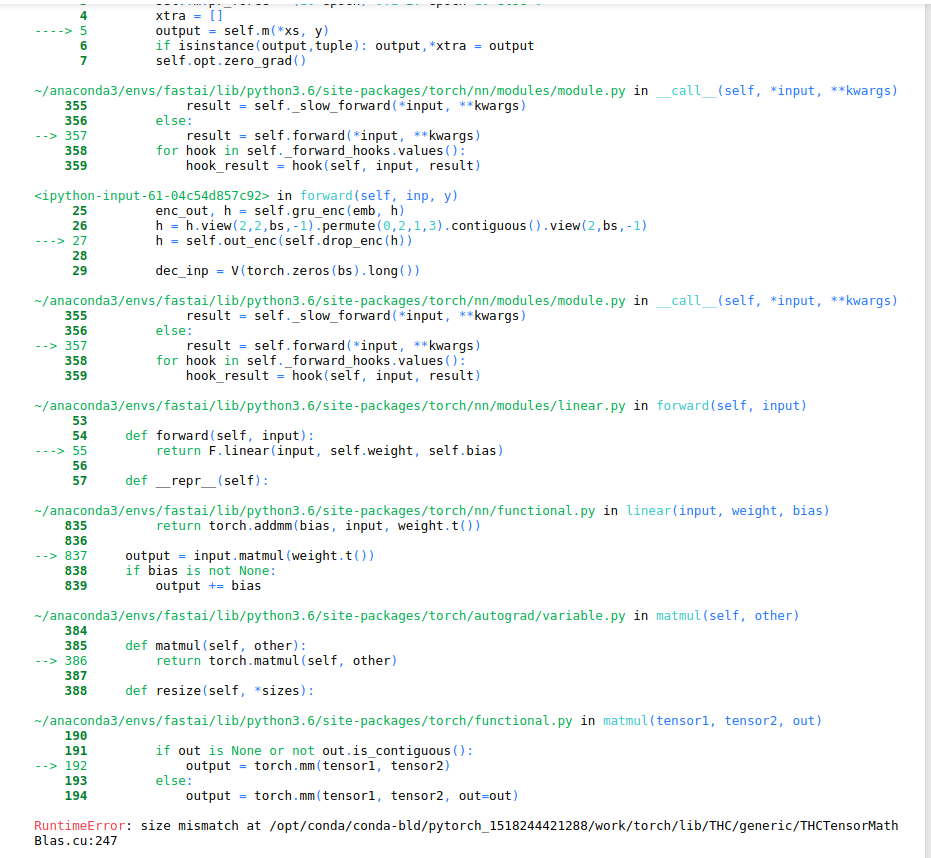
Hi, I’m trying to increase the number of layers from 2 to 3 in the final model “Seq2SeqRNN_All” to make it more expressive. I removed the nl=2 hardcoding in init().
However, when I try and run .fit() I get the following error. Does anyone know where my dimension mismatch is coming from and what I should change? As a new user I can only attach 1 image, but I added as much of the error trace as possible. Thank you!
Hi, I am kind of late here but I wonder if anyone try download the full imagenet data to run devise section? The val folder seems different compared to the jupyter notebook, instead it now contains just the JPEG files with xml annotation in another folder. Just thought the codes below would be useful to someone for grabbing the fast text word vector using the synset to word vector ( syn2wv ).
import xml.etree.ElementTree as ET
images = []
img_vecs = []
n_trn = 0
for d in (PATH/'ILSVRC/Data/CLS-LOC/train').iterdir():
if d.name not in syn2wv: continue
vec = syn2wv[d.name]
for f in d.iterdir():
images.append(str(f.relative_to(PATH)))
img_vecs.append(vec)
n_trn +=1
n_val=0
for d in (PATH/'ILSVRC/Data/CLS-LOC/val/').iterdir():
vname = d.name.split('.')[0]
extract = ET.parse(os.path.join(PATH/'ILSVRC/Annotations/CLS-LOC/val/',vname +'.xml'))
dname = extract.getroot()[-1][0].text # object-name
#print(vname, dname)
if dname not in syn2wv: continue
#print('OK', dname)
vec = syn2wv[dname]
images.append(str(d.relative_to(PATH)))
img_vecs.append(vec)
n_val += 1
was the topic of stacked RNN covered before? Jermey mentioned that in this session but I relooked at lesson 6 and lesson 7 of part one and I cannot seem to find any difference about different structures RNN cells are put together. Am I missing something?
Thank you for this amazing post, @phaniteja. Thank you too for the equally amazing reply, @stemill. I benefited a lot, but only after reading them several times
if (y is not None) and (random.random()<self.pr_force):
if i>=len(y): break
dec_inp = y[i]
My bad, actually I was trying to create a similar network with keras using attention mechanism. Due to static graphs, I wasn’t able to create one with teacher-forcing method.
i believe jeremy said during the video lecture that he switched to pytorch precisely because it was difficult to implement teacher forcing on tensorflow, so perhaps don’t try too hard on this
The link found in the translate notebook (shown above) to the fasttext word vectors has changed. Googling around and browsing the base url repo, I can’t find what would work as a replacement.
https://fasttext.cc/docs/en/english-vectors.html maybe will work. But it’s only English and definitely from a different corpus source, which I guess is fine, I just won’t reproduce the notebook.
Why is SortishSampler using the English (target) set for the sorting? Since it is translating French to English in this example, I would expected the fr_trn set to be used, in stead of the en_trn set to keep all the training data in relative same sizes…Or is it more important that the target, and therefore the output activations are of similar size?
I have been trying to follow along this lesson, however I am struggling to understand why my predictions end with several “eos eos eos”. Also, words are repeated several times no matter how much better the scores get. For example, predictions like, “you are very very very late late eos eos eos”. I don’t believe I have changed the code either. Any ideas?
I have problems with running the lesson material myself, on my computer (I have been able to run more other ones)
After the Word vectors title, fastText gets being used. I am able to import it, but then I come to this line:
To use the fastText library, you’ll need to download fasttext word vectors for your language (download the ‘bin plus text’ ones).
And the link is dead! So if I run the next block of code, it says: AttributeError: module ‘fastText’ has no attribute ‘load_model’


 ?
?