import matplotlib.pyplot as plt
#import nltk
import numpy as np
import pandas as pd
import seaborn as sns
#from wordcloud import WordCloud, STOPWORDS
df = pd.read_csv(’…/…/…/data/datasets/women_reviews.csv’)
print (df.head())
#print df.shape
for column in [“Division Name”,“Department Name”,“Class Name”,“Review Text”]:
df = df[df[column].notnull()]
df.drop(df.columns[0], inplace=True, axis=1)
#print df.shape
df[‘Label’]=0
df.loc[df.Rating>=3, [‘Label’]] = 1
#print df.head()
cat_dtypes = [‘Rating’,‘Label’]
increment=0
f, axes = plt.subplots(1, len(cat_dtypes), figsize=(16, 6), sharex=False)
for i in range(len(cat_dtypes)):
sns.countplot(x=cat_dtypes[increment], data=df, order=df[cat_dtypes[increment]].value_counts().index, ax=axes[i])
axes[i].set_title(‘Frequency Distribution for\n{}’.format(cat_dtypes[increment]))
axes[i].set_ylabel(‘Occurrence’)
axes[i].set_xlabel(’{}’.format(cat_dtypes[increment]))
increment += 1
axes[1].set_ylabel(’’)
#axes[2].set_ylabel(’’)
plt.savefig(‘freqdist-rating-recommended-label.png’, format=‘png’, dpi=300)
#plt.show()
‘’‘huevar = ‘Rating’
f, axes = plt.subplots(1, 2, figsize=(16, 7))
sns.countplot(x=‘Rating’, hue=‘Recommended IND’, data=df, ax=axes[0])
axes[0].set_title(‘Occurrence of {}\nby {}’.format(huevar, ‘Recommended IND’))
axes[0].set_ylabel(‘Count’)
percentstandardize_barplot(x=‘Rating’, y=‘Percentage’, hue=‘Recommended IND’, data=df, ax=axes[1])
#axes[1].set_title(‘Percentage Normalized Occurrence of {}\nby {}’.format(huevar, ‘Recommended IND’))
#axes[1].set_ylabel(’% Percentage by Rating’)
plt.savefig(‘rating-recommended.png’, format=‘png’, dpi=300)
plt.show()’’’
pd.set_option(‘max_colwidth’, 300)
#print df[[“Title”,“Review Text”, “Rating”, “Label”]].sample(10)
import os, sys
import re
import string
import pathlib
import random
from collections import Counter, OrderedDict
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import spacy
from tqdm import tqdm, tqdm_notebook, tnrange
tqdm.pandas(desc=‘Progress’)
import torch.cuda
if torch.cuda.is_available():
import torch.cuda as t
else:
import torch as t
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
import torch.nn.functional as F
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence
import torchtext
from torchtext import data
from torchtext import vocab
from sklearn.model_selection import StratifiedShuffleSplit, train_test_split
from sklearn.metrics import accuracy_score
import warnings
warnings.filterwarnings(‘ignore’)
#device = torch.device(“cuda:0”)
datapath = pathlib.Path(’./datasets’)
print (datapath)
df=df.rename(columns={‘Review Text’: ‘ReviewText’})
#print df.head()
df[‘ReviewText’]=df.ReviewText.progress_apply(lambda x: re.sub(’\n’, ’ ', x))
#split datasets
def split_dataset(df, test_size=0.2):
train, val=train_test_split(df, test_size=test_size, random_state=42)
return train.reset_index(drop=True), val.reset_index(drop=True)
traindf, valdf=split_dataset(df, test_size=0.2)
#shape of traindf, valdf
‘’'print ‘train-shape’
print traindf.shape
print traindf.Label.value_counts()
print (‘val-shape’)
print valdf.Label.value_counts()’’’
#save csv files for training and validation
traindf.to_csv(‘traindf.csv’, index=False)
valdf.to_csv(‘valdf.csv’, index=False)
#preprocessing
#print traindf.head()
nlp = spacy.load(‘en’, disable=[‘parser’, ‘tagger’, ‘ner’])
def tokenizer(s):
return [ w.text.lower() for w in nlp(tweet_clean(s))]
def tweet_clean(txt):
txt=re.sub(r’[^A-Za-z0-9]+’, ’ ‘, txt)
txt=re.sub(r’https?://\S+’, ’ ', txt)
return txt.strip()
‘’‘For text columns or fields, below parameters are used.
‘sequential=True’
It tell torchtext that the data is in form of sequence and not discrete
‘tokenize=tokenizer’
This attribute takes a function that will tokenize a given text. In this case the function will tokenize a single tweet. You can also pass ‘spacy’ string in this attribute if spacy is installed.
‘include_lengths=True’
Apart from tokenized text we will also need the lengths of the tweets for RNN
‘use_vocab=True’
Since this is used to process the text data, we need to create the vocabulary of unique words. This attribute tells torchtext to create the vocabulary
‘’’
‘’'For label columns or fields, below parameters are used.
‘sequential=False’
Now we are defining the blueprint of label columns. Labels are not sequential data, they are discrete. So this attribute is false
‘use_vocab=False’
Since it is a binary classification problem and labels are already numericalized, we will set this to false
‘pad_token=None’
‘unk_token=None’
We don’t need padding and out of vocabulary tokens for labels.’’’
#define fields
txt_field=data.Field(sequential=True,tokenize=tokenizer,include_lengths=True,use_vocab=True, postprocessing= lambda x: float(x))
label_field=data.Field(sequential=False, use_vocab=False,pad_token=None,unk_token=None,postprocessing=data.Pipeline(lambda x: float(x)))
train_val_fields=[
(‘Clothing ID’, None),
(‘Age’, None),
(‘Title’, None),
(‘ReviewText’, txt_field),
(‘Rating’,None),
(‘Recommended IND’,None),
(‘Positive Feedback Count’,None),
(‘Division Name’, None),
(‘Department Name’, None),
(‘Class Name’,None),
(‘Label’, label_field)]
‘’‘path=’./data’
Path were the csv or tsv files are stores
format=‘csv’
format of the files that will be loaded and processed
train=‘traindf.csv’
Name of train file. The final path will become ./data/traindf.csv
validation=‘valdf.csv’
Name of validation file. The final path will become ./data/valdf.csv
fields=train_val_fields
Tell torchtext how the coming data will be processed
skip_header=True
skip the first line in the csv, if it contains header’’’
trainds, valds = data.TabularDataset.splits(path=’’,format=‘csv’,train=‘traindf.csv’,validation=‘valdf.csv’,fields=train_val_fields,skip_header=True)
print (type(trainds))
print ((len(trainds), len(valds)))
print (trainds.fields.items())
example = trainds[0]
print (type(example))
print (type(example.ReviewText))
print (type(example.Label))
#load pretrained word vectors
from torchtext import vocab
#vec = vocab.Vectors(‘glove.42B.300d.txt’, ‘…/…/…/data/’)
vec = vocab.GloVe(name=‘twitter.27B’, dim=100)
print (vec)
txt_field.build_vocab(trainds, valds,max_size=100000, vectors=vec)
#build vocab for labels
#label_field.build_vocab(trainds)
print (txt_field.vocab.vectors.shape)
#print (txt_field.vocab.vectros[txt_field.vocab.stoi[‘awesome’]])
help withme error of this code
Jupyter Notebook
Untitled1
Last Checkpoint: 15 hours ago
(autosaved)
Current Kernel Logo
Python 3
File
Edit
View
Insert
Cell
Kernel
Widgets
Help
import matplotlib.pyplot as plt
#import nltk
import numpy as np
import pandas as pd
import seaborn as sns
#from wordcloud import WordCloud, STOPWORDS
df = pd.read_csv(’…/…/…/data/datasets/women_reviews.csv’)
print (df.head())
#print df.shape
for column in [“Division Name”,“Department Name”,“Class Name”,“Review Text”]:
df = df[df[column].notnull()]
df.drop(df.columns[0], inplace=True, axis=1)
#print df.shape
df[‘Label’]=0
df.loc[df.Rating>=3, [‘Label’]] = 1
#print df.head()
cat_dtypes = [‘Rating’,‘Label’]
increment=0
f, axes = plt.subplots(1, len(cat_dtypes), figsize=(16, 6), sharex=False)
for i in range(len(cat_dtypes)):
sns.countplot(x=cat_dtypes[increment], data=df, order=df[cat_dtypes[increment]].value_counts().index, ax=axes[i])
axes[i].set_title(‘Frequency Distribution for\n{}’.format(cat_dtypes[increment]))
axes[i].set_ylabel(‘Occurrence’)
axes[i].set_xlabel(’{}’.format(cat_dtypes[increment]))
increment += 1
axes[1].set_ylabel(’’)
#axes[2].set_ylabel(’’)
plt.savefig(‘freqdist-rating-recommended-label.png’, format=‘png’, dpi=300)
#plt.show()
‘’‘huevar = ‘Rating’
f, axes = plt.subplots(1, 2, figsize=(16, 7))
sns.countplot(x=‘Rating’, hue=‘Recommended IND’, data=df, ax=axes[0])
axes[0].set_title(‘Occurrence of {}\nby {}’.format(huevar, ‘Recommended IND’))
axes[0].set_ylabel(‘Count’)
percentstandardize_barplot(x=‘Rating’, y=‘Percentage’, hue=‘Recommended IND’, data=df, ax=axes[1])
#axes[1].set_title(‘Percentage Normalized Occurrence of {}\nby {}’.format(huevar, ‘Recommended IND’))
#axes[1].set_ylabel(’% Percentage by Rating’)
plt.savefig(‘rating-recommended.png’, format=‘png’, dpi=300)
plt.show()’’’
pd.set_option(‘max_colwidth’, 300)
#print df[[“Title”,“Review Text”, “Rating”, “Label”]].sample(10)
import os, sys
import re
import string
import pathlib
import random
from collections import Counter, OrderedDict
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import spacy
from tqdm import tqdm, tqdm_notebook, tnrange
tqdm.pandas(desc=‘Progress’)
import torch.cuda
if torch.cuda.is_available():
import torch.cuda as t
else:
import torch as t
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
import torch.nn.functional as F
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence
import torchtext
from torchtext import data
from torchtext import vocab
from sklearn.model_selection import StratifiedShuffleSplit, train_test_split
from sklearn.metrics import accuracy_score
import warnings
warnings.filterwarnings(‘ignore’)
#device = torch.device(“cuda:0”)
datapath = pathlib.Path(’./datasets’)
print (datapath)
df=df.rename(columns={‘Review Text’: ‘ReviewText’})
#print df.head()
df[‘ReviewText’]=df.ReviewText.progress_apply(lambda x: re.sub(’\n’, ’ ', x))
#split datasets
def split_dataset(df, test_size=0.2):
train, val=train_test_split(df, test_size=test_size, random_state=42)
return train.reset_index(drop=True), val.reset_index(drop=True)
traindf, valdf=split_dataset(df, test_size=0.2)
#shape of traindf, valdf
‘’'print ‘train-shape’
print traindf.shape
print traindf.Label.value_counts()
print (‘val-shape’)
print valdf.Label.value_counts()’’’
#save csv files for training and validation
traindf.to_csv(‘traindf.csv’, index=False)
valdf.to_csv(‘valdf.csv’, index=False)
#preprocessing
#print traindf.head()
nlp = spacy.load(‘en’, disable=[‘parser’, ‘tagger’, ‘ner’])
def tokenizer(s):
return [ w.text.lower() for w in nlp(tweet_clean(s))]
def tweet_clean(txt):
txt=re.sub(r’[^A-Za-z0-9]+’, ’ ‘, txt)
txt=re.sub(r’https?://\S+’, ’ ', txt)
return txt.strip()
‘’‘For text columns or fields, below parameters are used.
‘sequential=True’
It tell torchtext that the data is in form of sequence and not discrete
‘tokenize=tokenizer’
This attribute takes a function that will tokenize a given text. In this case the function will tokenize a single tweet. You can also pass ‘spacy’ string in this attribute if spacy is installed.
‘include_lengths=True’
Apart from tokenized text we will also need the lengths of the tweets for RNN
‘use_vocab=True’
Since this is used to process the text data, we need to create the vocabulary of unique words. This attribute tells torchtext to create the vocabulary
‘’’
‘’'For label columns or fields, below parameters are used.
‘sequential=False’
Now we are defining the blueprint of label columns. Labels are not sequential data, they are discrete. So this attribute is false
‘use_vocab=False’
Since it is a binary classification problem and labels are already numericalized, we will set this to false
‘pad_token=None’
‘unk_token=None’
We don’t need padding and out of vocabulary tokens for labels.’’’
#define fields
txt_field=data.Field(sequential=True,tokenize=tokenizer,include_lengths=True,use_vocab=True, postprocessing= lambda x: float(x))
label_field=data.Field(sequential=False, use_vocab=False,pad_token=None,unk_token=None,postprocessing=data.Pipeline(lambda x: float(x)))
train_val_fields=[
(‘Clothing ID’, None),
(‘Age’, None),
(‘Title’, None),
(‘ReviewText’, txt_field),
(‘Rating’,None),
(‘Recommended IND’,None),
(‘Positive Feedback Count’,None),
(‘Division Name’, None),
(‘Department Name’, None),
(‘Class Name’,None),
(‘Label’, label_field)]
‘’‘path=’./data’
Path were the csv or tsv files are stores
format=‘csv’
format of the files that will be loaded and processed
train=‘traindf.csv’
Name of train file. The final path will become ./data/traindf.csv
validation=‘valdf.csv’
Name of validation file. The final path will become ./data/valdf.csv
fields=train_val_fields
Tell torchtext how the coming data will be processed
skip_header=True
skip the first line in the csv, if it contains header’’’
trainds, valds = data.TabularDataset.splits(path=’’,format=‘csv’,train=‘traindf.csv’,validation=‘valdf.csv’,fields=train_val_fields,skip_header=True)
print (type(trainds))
print ((len(trainds), len(valds)))
print (trainds.fields.items())
example = trainds[0]
print (type(example))
print (type(example.ReviewText))
print (type(example.Label))
#load pretrained word vectors
from torchtext import vocab
#vec = vocab.Vectors(‘glove.42B.300d.txt’, ‘…/…/…/data/’)
vec = vocab.GloVe(name=‘twitter.27B’, dim=100)
print (vec)
txt_field.build_vocab(trainds, valds,max_size=100000, vectors=vec)
#build vocab for labels
#label_field.build_vocab(trainds)
print (txt_field.vocab.vectors.shape)
#print (txt_field.vocab.vectros[txt_field.vocab.stoi[‘awesome’]])
import matplotlib.pyplot as plt
#import nltk
import numpy as np
import pandas as pd
import seaborn as sns
#from wordcloud import WordCloud, STOPWORDS
df = pd.read_csv(’…/…/…/data/datasets/women_reviews.csv’)
print (df.head())
#print df.shape
for column in [“Division Name”,“Department Name”,“Class Name”,“Review Text”]:
df = df[df[column].notnull()]
df.drop(df.columns[0], inplace=True, axis=1)
#print df.shape
df[‘Label’]=0
df.loc[df.Rating>=3, [‘Label’]] = 1
#print df.head()
cat_dtypes = [‘Rating’,‘Label’]
increment=0
f, axes = plt.subplots(1, len(cat_dtypes), figsize=(16, 6), sharex=False)
for i in range(len(cat_dtypes)):
sns.countplot(x=cat_dtypes[increment], data=df, order=df[cat_dtypes[increment]].value_counts().index, ax=axes[i])
axes[i].set_title(‘Frequency Distribution for\n{}’.format(cat_dtypes[increment]))
axes[i].set_ylabel(‘Occurrence’)
axes[i].set_xlabel(’{}’.format(cat_dtypes[increment]))
increment += 1
axes[1].set_ylabel(’’)
#axes[2].set_ylabel(’’)
plt.savefig(‘freqdist-rating-recommended-label.png’, format=‘png’, dpi=300)
#plt.show()
‘’‘huevar = ‘Rating’
f, axes = plt.subplots(1, 2, figsize=(16, 7))
sns.countplot(x=‘Rating’, hue=‘Recommended IND’, data=df, ax=axes[0])
axes[0].set_title(‘Occurrence of {}\nby {}’.format(huevar, ‘Recommended IND’))
axes[0].set_ylabel(‘Count’)
percentstandardize_barplot(x=‘Rating’, y=‘Percentage’, hue=‘Recommended IND’, data=df, ax=axes[1])
#axes[1].set_title(‘Percentage Normalized Occurrence of {}\nby {}’.format(huevar, ‘Recommended IND’))
#axes[1].set_ylabel(’% Percentage by Rating’)
plt.savefig(‘rating-recommended.png’, format=‘png’, dpi=300)
plt.show()’’’
pd.set_option(‘max_colwidth’, 300)
#print df[[“Title”,“Review Text”, “Rating”, “Label”]].sample(10)
import os, sys
import re
import string
import pathlib
import random
from collections import Counter, OrderedDict
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import spacy
from tqdm import tqdm, tqdm_notebook, tnrange
tqdm.pandas(desc=‘Progress’)
import torch.cuda
if torch.cuda.is_available():
import torch.cuda as t
else:
import torch as t
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
import torch.nn.functional as F
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence
import torchtext
from torchtext import data
from torchtext import vocab
from sklearn.model_selection import StratifiedShuffleSplit, train_test_split
from sklearn.metrics import accuracy_score
import warnings
warnings.filterwarnings(‘ignore’)
#device = torch.device(“cuda:0”)
datapath = pathlib.Path(’./datasets’)
print (datapath)
df=df.rename(columns={‘Review Text’: ‘ReviewText’})
#print df.head()
df[‘ReviewText’]=df.ReviewText.progress_apply(lambda x: re.sub(’\n’, ’ ‘, x))
#split datasets
def split_dataset(df, test_size=0.2):
train, val=train_test_split(df, test_size=test_size, random_state=42)
return train.reset_index(drop=True), val.reset_index(drop=True)
traindf, valdf=split_dataset(df, test_size=0.2)
#shape of traindf, valdf
‘’‘print ‘train-shape’
print traindf.shape
print traindf.Label.value_counts()
print (‘val-shape’)
print valdf.Label.value_counts()’’’
#save csv files for training and validation
traindf.to_csv(‘traindf.csv’, index=False)
valdf.to_csv(‘valdf.csv’, index=False)
#preprocessing
#print traindf.head()
nlp = spacy.load(‘en’, disable=[‘parser’, ‘tagger’, ‘ner’])
def tokenizer(s):
return [ w.text.lower() for w in nlp(tweet_clean(s))]
def tweet_clean(txt):
txt=re.sub(r’[^A-Za-z0-9]+’, ’ ‘, txt)
txt=re.sub(r’https?://\S+’, ’ ', txt)
return txt.strip()
‘’‘For text columns or fields, below parameters are used.
‘sequential=True’
It tell torchtext that the data is in form of sequence and not discrete
‘tokenize=tokenizer’
This attribute takes a function that will tokenize a given text. In this case the function will tokenize a single tweet. You can also pass ‘spacy’ string in this attribute if spacy is installed.
‘include_lengths=True’
Apart from tokenized text we will also need the lengths of the tweets for RNN
‘use_vocab=True’
Since this is used to process the text data, we need to create the vocabulary of unique words. This attribute tells torchtext to create the vocabulary
‘’’
‘’'For label columns or fields, below parameters are used.
‘sequential=False’
Now we are defining the blueprint of label columns. Labels are not sequential data, they are discrete. So this attribute is false
‘use_vocab=False’
Since it is a binary classification problem and labels are already numericalized, we will set this to false
‘pad_token=None’
‘unk_token=None’
We don’t need padding and out of vocabulary tokens for labels.’’’
#define fields
txt_field=data.Field(sequential=True,tokenize=tokenizer,include_lengths=True,use_vocab=True, postprocessing= lambda x: float(x))
label_field=data.Field(sequential=False, use_vocab=False,pad_token=None,unk_token=None,postprocessing=data.Pipeline(lambda x: float(x)))
train_val_fields=[
(‘Clothing ID’, None),
(‘Age’, None),
(‘Title’, None),
(‘ReviewText’, txt_field),
(‘Rating’,None),
(‘Recommended IND’,None),
(‘Positive Feedback Count’,None),
(‘Division Name’, None),
(‘Department Name’, None),
(‘Class Name’,None),
(‘Label’, label_field)]
‘’‘path=’./data’
Path were the csv or tsv files are stores
format=‘csv’
format of the files that will be loaded and processed
train=‘traindf.csv’
Name of train file. The final path will become ./data/traindf.csv
validation=‘valdf.csv’
Name of validation file. The final path will become ./data/valdf.csv
fields=train_val_fields
Tell torchtext how the coming data will be processed
skip_header=True
skip the first line in the csv, if it contains header’’’
trainds, valds = data.TabularDataset.splits(path=’’,format=‘csv’,train=‘traindf.csv’,validation=‘valdf.csv’,fields=train_val_fields,skip_header=True)
print (type(trainds))
print ((len(trainds), len(valds)))
print (trainds.fields.items())
example = trainds[0]
print (type(example))
print (type(example.ReviewText))
print (type(example.Label))
#load pretrained word vectors
from torchtext import vocab
#vec = vocab.Vectors(‘glove.42B.300d.txt’, ‘…/…/…/data/’)
vec = vocab.GloVe(name=‘twitter.27B’, dim=100)
print (vec)
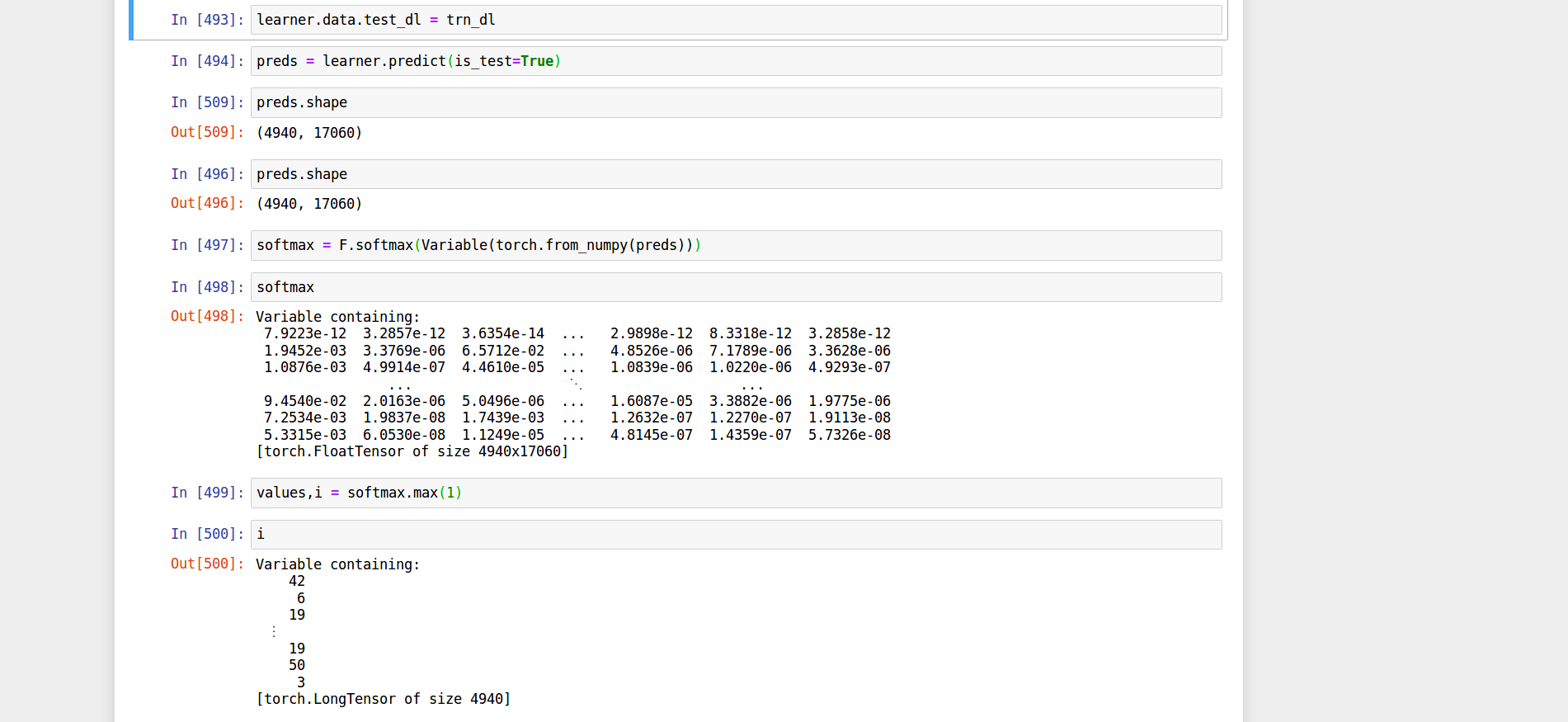
txt_field.build_vocab(trainds, valds,max_size=100000, vectors=vec)
#build vocab for labels
#label_field.build_vocab(trainds)
print (txt_field.vocab.vectors.shape)
#print (txt_field.vocab.vectros[txt_field.vocab.stoi[‘awesome’]])
#loading data in batches
#traindl, valdl=data.BucketIterator.splits(datasets=(trainds, valds), batch_sizes(3,3),sort_key=lambda x: len(x.ReviewText), device=None, sort_within_batch=True,repeat=False)
#print len(traindl), len(valdl)
#batch = next(iter(traindl))
#generate batch
‘’‘class BatchGenerator:
def init(self, dl, x_field, y_field):
self.dl, self.x_field, self.y_field=dl, x_field, y_field
def len(self):
return len(self.dl)
def iter(self):
for batch in seld.dl:
X = getattr(batch, self.x_field)
y = getattr(batch, self.y_field)
yield (X,y)
‘’’
Unnamed: 0 Clothing ID Age Title
0 0 767 33 NaN
1 1 1080 34 NaN
2 2 1077 60 Some major design flaws
3 3 1049 50 My favorite buy!
4 4 847 47 Flattering shirt
Review Text \
0 Absolutely wonderful - silky and sexy and comfortable
1 Love this dress! it’s sooo pretty. i happened to find it in a store, and i’m glad i did bc i never would have ordered it online bc it’s petite. i bought a petite and am 5’8". i love the length on me- hits just a little below the knee. would definitely be a true midi on someone who is truly …
2 I had such high hopes for this dress and really wanted it to work for me. i initially ordered the petite small (my usual size) but i found this to be outrageously small. so small in fact that i could not zip it up! i reordered it in petite medium, which was just ok. overall, the top half was com…
3 I love, love, love this jumpsuit. it’s fun, flirty, and fabulous! every time i wear it, i get nothing but great compliments!
4 This shirt is very flattering to all due to the adjustable front tie. it is the perfect length to wear with leggings and it is sleeveless so it pairs well with any cardigan. love this shirt!!!
Rating Recommended IND Positive Feedback Count Division Name
0 4 1 0 Initmates
1 5 1 4 General
2 3 0 0 General
3 5 1 0 General Petite
4 5 1 6 General
Department Name Class Name
0 Intimate Intimates
1 Dresses Dresses
2 Dresses Dresses
3 Bottoms Pants
4 Tops Blouses
Progress: 100%|██████████| 22628/22628 [00:00<00:00, 336453.11it/s]
datasets
<class ‘torchtext.data.dataset.TabularDataset’>
(18392, 4608)
dict_items([(‘Clothing ID’, None), (‘Age’, None), (‘Title’, None), (‘ReviewText’, <torchtext.data.field.Field object at 0x7fe1931da390>), (‘Rating’, None), (‘Recommended IND’, None), (‘Positive Feedback Count’, None), (‘Division Name’, None), (‘Department Name’, None), (‘Class Name’, None), (‘Label’, <torchtext.data.field.Field object at 0x7fe15199b160>)])
<class ‘torchtext.data.example.Example’>
<class ‘list’>
<class ‘str’>
<torchtext.vocab.GloVe object at 0x7fe10c781630>
AttributeError Traceback (most recent call last)
in ()
228 print (vec)
229
–> 230 txt_field.build_vocab(trainds, valds,max_size=100000, vectors=vec)
231
232 #build vocab for labels
~/anaconda3/envs/fastai/lib/python3.6/site-packages/torchtext/data/field.py in build_vocab(self, *args, **kwargs)
247 sources.append(arg)
248 for data in sources:
–> 249 for x in data:
250 if not self.sequential:
251 x = [x]
~/anaconda3/envs/fastai/lib/python3.6/site-packages/torchtext/data/dataset.py in getattr(self, attr)
145 if attr in self.fields:
146 for x in self.examples:
–> 147 yield getattr(x, attr)
148
149 @classmethod
AttributeError: ‘Example’ object has no attribute ‘ReviewText’
torch.cuda.is_available()
True