Thanks!
I was typing text as I was doing my experiments…sorry if the comments were too lengthy & repetitive.
I’ve submitted a PR with fewer markdown and more concise comments.
3 Likes
Thanks! This worked like a charm
Added a PR that does this: Memory fix for sortsampler and sortishsampler in text.py by EvenOldridge · Pull Request #323 · fastai/fastai · GitHub
In my testing I only ran into one OOM error out of a half dozen runs. I didn’t encounter any with the other version and the memory scaling was very consistent. That said I was only able to test each a half dozen times. Hopefully the community at large can test and if there are issues we can revert.
The LM Classifier was about 9 gigs all told so I’m not sure that this will be a fix for those with smaller devices, but it’s probably worth adding in anyway.
3 Likes
That’s great @even. If you have a moment it would be nice to add some comments to SortishSampler to explain what’s going on - it was already a bit hairy, and now it’s even more complex!
@nok It looks like you’re converging on a solution much more quickly, both for your language model and for the classifier.
Your epoch 3 is very close to Jeremy’s final solution, and is still on par with the current SOTA.
1 Like
Sure. I didn’t want to add anything because most of the library doesn’t have any per the format guidelines. Should I add a summary above the function itself rather than commenting inline?
Well the format guidelines I think say that it’s nice to mention what you’re doing. So perhaps a docstring that summarizes what it does would be enough?
Done 
1 Like
I think I also figured out why the language model memory fix made such a difference, but that the classifier fix isn’t as impactful.
The language model batch widths vary normally by 5 stdevs, which can create wildly varying sequences of widths. I haven’t done the analysis, but I’d be very surprised if the length of the reviews in the classifier example vary by more than 1-2 stdevs and that most reviews are of a similar length, so you hit the max much more quickly.
I’m also not 100% but I suspect cuda/pytorch must be doing some estimation on the size of the buffer based on that first batch and not using it’s size exactly, but I need to read into the inner workings to understand if that’s the case. It’s also possible that the buffer growth strategy means that it grows quickly to the right size.
1 Like
Interesting!
Yes, but I could not reach 94.8 and it overfit very quickly.
Still, the bounce of validation loss puzzle me, in Jeremy’s notebook the val loss bounce quite a lot on 2 epoch and slowly converge.
Nup that’s not what happens - it’s N(bptt,5). So stdev of 5 tokens.
Having a well trained LM definitely helps there. Also try having your LR go up slowly using CLR.
1 Like
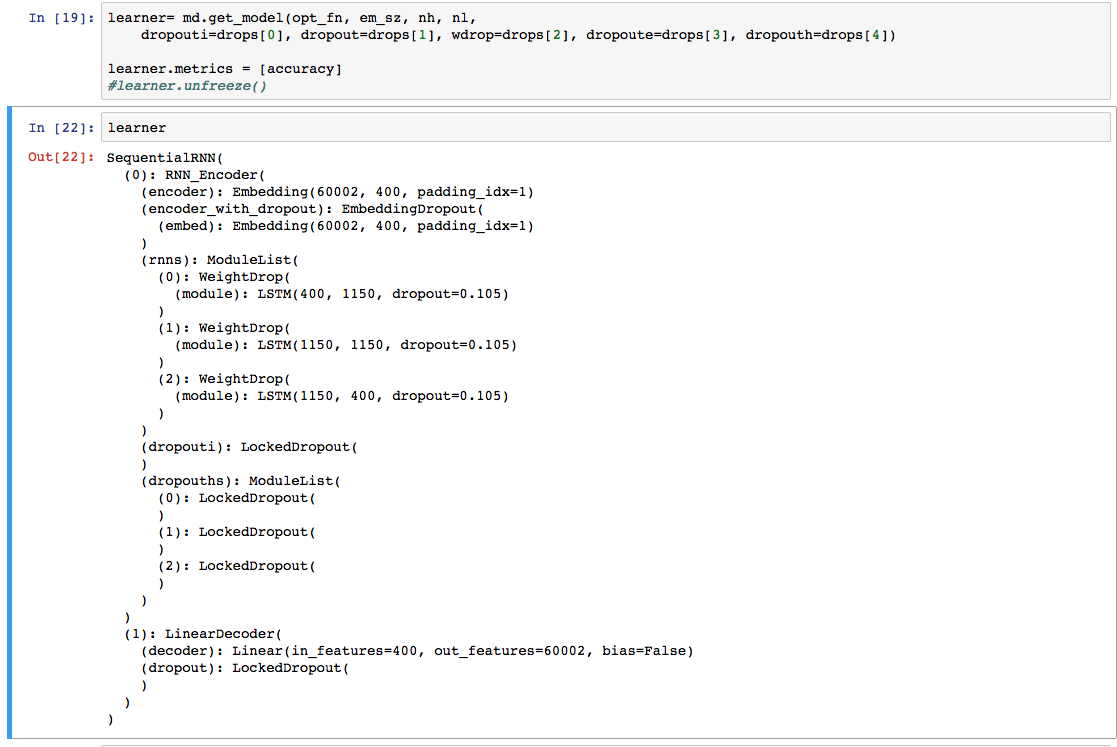
Can someone help me understand the learner architecture here
I’m having a hard time visualising it. (Any links to articles also appreciated)
Ok…any specific questions?
Hi Arvind,
Okay so firstly, is this a stacked LSTM and 3 LSTM’s are stacked vertically ?
and as per what I was able to think,
- First is an embedding layer (Converts vocab to 400 dim vector)
- Then embeddings are fed to the 3 stacked LSTM’s (cell output dim’s changes from 1150->1150->400)
- The final output is fed to a decoding layer (Converts back 400dim to a vocab number)
- And then the whole things is trained end to end using sequence length 70 and then there is dropout in between…
Lastly, how is out_features=60,002 in the LinearDecoder layer ?
Appreciate your time given to answer my questions
4 Likes
Here is a great and timely example of an annotated (i.e for human) paper – very much along the lines of what Jeremy’s been championing here.
http://nlp.seas.harvard.edu//2018/04/03/attention.html
Best,
A
3 Likes
You’ve got it right.
The sequence length is approximately 70(we keep changing the values each batch). Batch size is fixed.
The LM has to predict what the next word will be, given previous set of bptt words. The decoder layer tries to output probabilities for every single item in the vocab(60k words + unk and pad tokens = 60002 tokens). We then have to pick the argmax from the output to see which word has the highest probability.
Hope that’s clear.
4 Likes
Oh, yes the probabilities !
Thanks for clearing that up 
1 Like
Note that the results I previously posted were for a baseline- without the wikitext103 weights. The most rapid increase in accuacy change was from the first epoch (accuracy of 0.04 on full dataset from memory) to the third epoch as you’d expect as without good starting weights the model has to learn them.
I was curious to know how much an effect a smaller dataset would have on the language model accuracy with wikitext103 pre-trained weights (all using same bs of 52, could also try with changing bs so that the actual batch size value is constant)
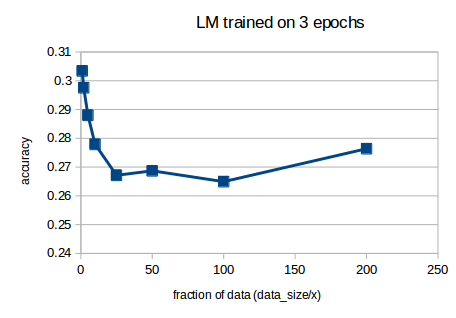
or in log form:
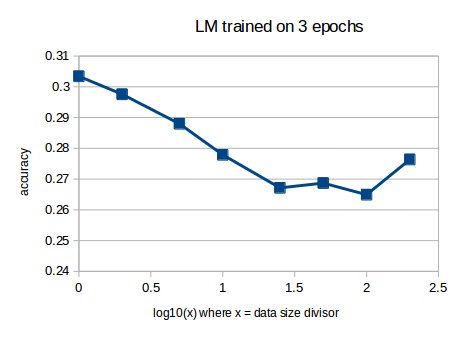
The log10 trend isn’t quite a straight line from full dataset (x=1) to 1/25th of the dataset (i was thinking along lines of how big a dataset would we need to get 0.5 accuracy).
I wonder why we get a ‘stable’ minimum from 1/25th of data size onwards, perhaps reflecting the underlying wikitext103 baseline accuracy?
I also ran some sensitivities to batch size prarameter (ie bs value) for a 1/50th of data sample, I think id need to run this again with full data to see what trend that would give before could make any conclusions:
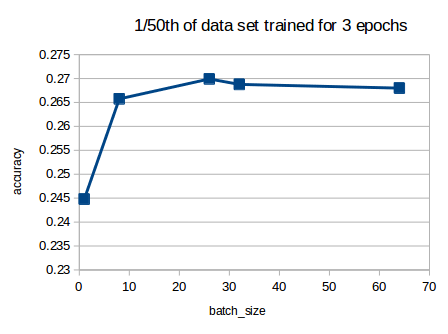
Also I ran tests on the dropout scalar with a couple of dataset sizes and didnt see any meaningful patterns in the accuracy or loss variation results, but probably need to run more tests.
1 Like