Perfect, will take a look at that and I will def send you anything I end up using so that you can give back to the community. I am so about giving back to this community in anyway that I can.
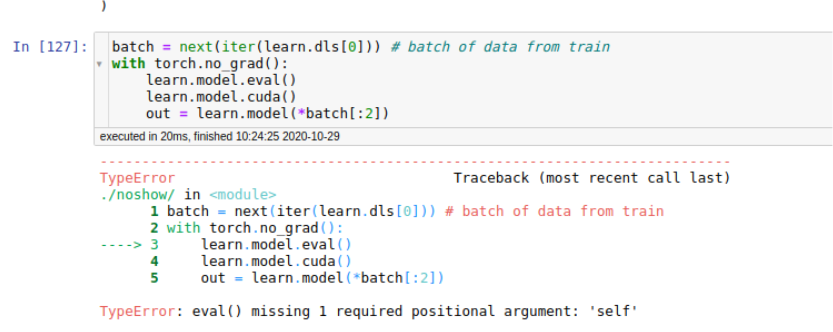
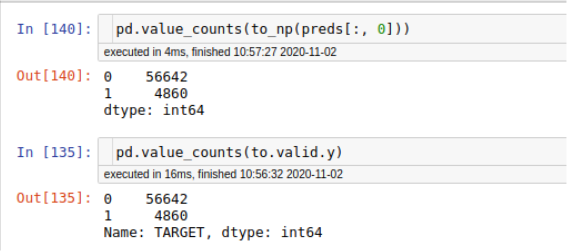
I will most def be using this moving forward so thank you. I can see there is something wrong here I wanted to compare the standard Tabular approach in fastai to this approach and then really dig into the differences between them.
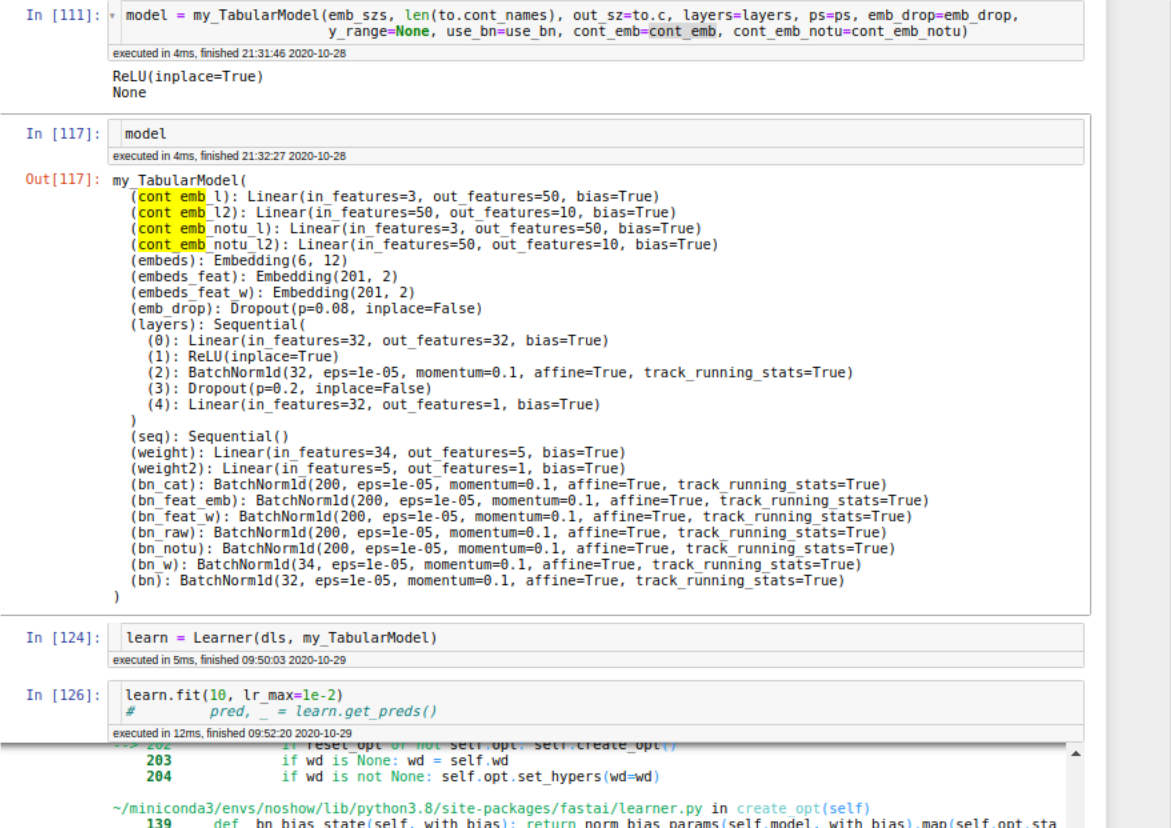
Seems like some adjustments are needed to be made to the structure of the model as it was written 2 years ago.
For anyone wondering what model I am talking about kaggle post slight changes were made already as some of the functions are deprecated ie embedding --> Embedding simple change, but it’s a change fastai2
# This is the NN structure, starting from fast.ai TabularModel.
class my_TabularModel(nn.Module):
"Basic model for tabular data."
def __init__(self, emb_szs, n_cont, out_sz, layers, ps=None,
emb_drop:float=0., y_range=None, use_bn:bool=True, bn_final:bool=False,
cont_emb=2, cont_emb_notu=2):
super().__init__()
# "Continuous embedding NN for raw features"
self.cont_emb = cont_emb[1]
self.cont_emb_l = torch.nn.Linear(1 + 2, cont_emb[0])
self.cont_emb_l2 = torch.nn.Linear(cont_emb[0], cont_emb[1])
# "Continuous embedding NN for "not unique" features". cf #1 solution post
self.cont_emb_notu_l = torch.nn.Linear(1 + 2, cont_emb_notu[0])
self.cont_emb_notu_l2 = torch.nn.Linear(cont_emb_notu[0], cont_emb_notu[1])
self.cont_emb_notu = cont_emb_notu[1]
ps = ifnone(ps, [0]*len(layers))
ps = listify(ps)*len(layers)
# Embedding for "has one" categorical features, cf #1 solution post
self.embeds = Embedding(emb_szs[0][0], emb_szs[0][1])
# At first we included information about the variable being processed (to extract feature importance).
# It works better using a constant feat (kind of intercept)
self.embeds_feat = Embedding(201, 2)
self.embeds_feat_w = Embedding(201, 2)
self.emb_drop = nn.Dropout(emb_drop)
n_emb = self.embeds.embedding_dim
n_emb_feat = self.embeds_feat.embedding_dim
n_emb_feat_w = self.embeds_feat_w.embedding_dim
self.n_emb, self.n_emb_feat, self.n_emb_feat_w, self.n_cont,self.y_range = n_emb, n_emb_feat, n_emb_feat_w, n_cont, y_range
sizes = self.get_sizes(layers, out_sz)
actns = [nn.ReLU(inplace=True)] * (len(sizes)-2) + [None]
layers = []
# Typically the acts gives us the ability to add a RELU(Inplace)
# for i,(n_in,n_out,dp) in enumerate(zip(sizes[:-1],sizes[1:],[0.]+ps)):
for i,(n_in,n_out,dp,act) in enumerate(zip(sizes[:-1],sizes[1:],[0.]+ps,actns)):
print(act)
layers += bn_drop_lin(n_in, n_out, bn=use_bn and i!=0, p=dp, actn=act)
self.layers = nn.Sequential(*layers)
self.seq = nn.Sequential()
# Input size for the NN that predicts weights
inp_w = self.n_emb + self.n_emb_feat_w + self.cont_emb + self.cont_emb_notu
# Input size for the final NN that predicts output
inp_x = self.n_emb + self.cont_emb + self.cont_emb_notu
# NN that predicts the weights
self.weight = nn.Linear(inp_w, 5)
self.weight2 = nn.Linear(5,1)
mom = 0.1
self.bn_cat = nn.BatchNorm1d(200, momentum=mom)
self.bn_feat_emb = nn.BatchNorm1d(200, momentum=mom)
self.bn_feat_w = nn.BatchNorm1d(200, momentum=mom)
self.bn_raw = nn.BatchNorm1d(200, momentum=mom)
self.bn_notu = nn.BatchNorm1d(200, momentum=mom)
self.bn_w = nn.BatchNorm1d(inp_w, momentum=mom)
self.bn = nn.BatchNorm1d(inp_x, momentum=mom)
def get_sizes(self, layers, out_sz):
return [self.n_emb + self.cont_emb_notu + self.cont_emb] + layers + [out_sz]
def forward(self, x_cat:Tensor, x_cont:Tensor) -> Tensor:
b_size = x_cont.size(0)
# embedding of has one feat
x = [self.embeds(x_cat[:,i]) for i in range(200)]
x = torch.stack(x, dim=1)
# embedding of intercept. It was embedding of feature id before
x_feat_emb = self.embeds_feat(x_cat[:,200])
x_feat_emb = torch.stack([x_feat_emb]*200, 1)
x_feat_emb = self.bn_feat_emb(x_feat_emb)
x_feat_w = self.embeds_feat_w(x_cat[:,200])
x_feat_w = torch.stack([x_feat_w]*200, 1)
# "continuous embedding" of raw features
x_cont_raw = x_cont[:,:200].contiguous().view(-1, 1)
x_cont_raw = torch.cat([x_cont_raw, x_feat_emb.view(-1, self.n_emb_feat)], 1)
x_cont_raw = F.relu(self.cont_emb_l(x_cont_raw))
x_cont_raw = self.cont_emb_l2(x_cont_raw)
x_cont_raw = x_cont_raw.view(b_size, 200, self.cont_emb)
# "continuous embedding" of not unique features
x_cont_notu = x_cont[:,200:].contiguous().view(-1, 1)
x_cont_notu = torch.cat([x_cont_notu, x_feat_emb.view(-1,self.n_emb_feat)], 1)
x_cont_notu = F.relu(self.cont_emb_notu_l(x_cont_notu))
x_cont_notu = self.cont_emb_notu_l2(x_cont_notu)
x_cont_notu = x_cont_notu.view(b_size, 200, self.cont_emb_notu)
x_cont_notu = self.bn_notu(x_cont_notu)
x = self.bn_cat(x)
x_cont_raw = self.bn_raw(x_cont_raw)
x = self.emb_drop(x)
x_cont_raw = self.emb_drop(x_cont_raw)
x_cont_notu = self.emb_drop(x_cont_notu)
x_feat_w = self.bn_feat_w(x_feat_w)
# Predict a weight for each of the previous embeddings
x_w = torch.cat([x.view(-1,self.n_emb),
x_feat_w.view(-1,self.n_emb_feat_w),
x_cont_raw.view(-1, self.cont_emb),
x_cont_notu.view(-1, self.cont_emb_notu)], 1)
x_w = self.bn_w(x_w)
w = F.relu(self.weight(x_w))
w = self.weight2(w).view(b_size, -1)
w = torch.nn.functional.softmax(w, dim=-1).unsqueeze(-1)
# weighted average of the differents embeddings using weights given by NN
x = (w * x).sum(dim=1)
x_cont_raw = (w * x_cont_raw).sum(dim=1)
x_cont_notu = (w * x_cont_notu).sum(dim=1)
# Use NN on the weighted average to predict final output
x = torch.cat([x, x_cont_raw, x_cont_notu], 1) if self.n_emb != 0 else x_cont
x = self.bn(x)
x = self.seq(x)
x = self.layers(x)