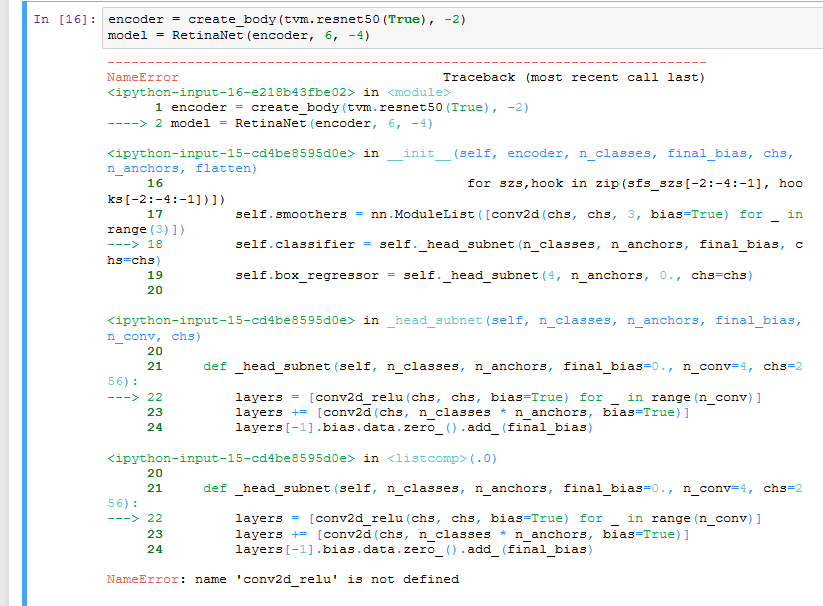
Thanks @msandroid! I am one step further now, again running into an error that seems to come from changes in teh fastai source code…
For anybody working on this, you can use my GIST as a start …
Thanks @msandroid! I am one step further now, again running into an error that seems to come from changes in teh fastai source code…
For anybody working on this, you can use my GIST as a start …