Thanks!
Will this be sufficient for retrieving what I need?
I also found this:
Which I think can be helpful.
If I need some callback that saves a decoded prediction of the image in a specific folder, say every epoch, then would it be it?
Thanks!
Will this be sufficient for retrieving what I need?
I also found this:
Which I think can be helpful.
If I need some callback that saves a decoded prediction of the image in a specific folder, say every epoch, then would it be it?
Hi,
I was wondering about the Avg and MaxPool2d layers that are the last step of CNN networks just before the head. In classification models they “compress” 49 (7x7) features from the last conv layer into a single feature vector using element-wise mean and max.
I tried to take some of the convolutional features from the 7x7 layer and build an image-search model (using BarlowTwins for unsupervised training) with them. If I take a single feature and calculate cosine similarity then it works really well. But when I try to calculate the element-wise mean or max of several features the cosine similarity is no longer working well – the more features are mix into the “search query” the less relevant the matches (ordered by cosine similarity).
Has anybody encountered this before?
I am also wondering how this affects transfer-learning:
My hypothesis:
Maybe the conv features have to be fine-tuned to each task to optimaly “survive” the pooling and give good accuracy? Would it be beneficial to add a randomly-initilized ResBlock between the last conv layer and the pooling later and train it with the same learning rate as the head?
What would be a good fine-tuning task & dataset (not object-detection since they don’t use max/avg pool layers) on which I could test this hypothesis? It has to be sufficiently different from ImageNet for the
I know it is still a little early for NLP. But has anyone tried codeBert? A quick search does not show up in the forums.
“We probe four models that vary in their expected knowledge of
code properties: BERT (pre-trained on English), CodeBERT and
CodeBERTa (pre-trained on source code, and natural language
documentation), and GraphCodeBERT (pre-trained on source
code with dataflow). While GraphCodeBERT performs more
consistently overall, we find that BERT performs surprisingly
well on some code tasks, which calls for further investigation.”
I’d suggest reading the source for this callback, since it’s close to what you want:
And of course read the docs for fastai callbacks in general:
PS: I found both of these by just googling for “fastai callback” – there’s lots of tutorials and stuff around about these to help you get started, so I’d suggest taking a look thru the links you’ll find there too.
Thank you for your guidance! @jeremy
The first link of yours is something that I’ve not seen yet. Great!
I’ve actually googled too, and have seen that second webpage that you posted. After sweeping through that, I kept searching and found out this: (As in my previous message)
Because get_preds also seems to be like something I’m looking for
You can just use predict() like we did in the last lesson - also shown in ch1 of the book. We’ll be using that more in the next lesson too FYI.
Hey there,
I’m brushing up my knowledge a little bit, and just got surprised with a new function vision_learner that replaces cnn_learner.
How is vision_learner different than unet_learner? When and which is better to use which?
(Answer that I think that I found: vision_learner fits more of classification tasks, while unet_learner fits more of regression/segmentation tasks)
Another few questions:
learn = vision_learner(dls, resnet34, metrics=error_rate)
learn.fit_one_cycle(3, 3e-3)
learn.unfreeze()
learn.fit_one_cycle(12, lr_max=slice(1e-6,1e-4))
unfreeze() between training? I only understood that it helps us not update the weights of the last layer. But I kinda got lost in beforehand. What happens if I don’t unfreeze()?slice(), does the 1e-6 apply to the later layers? (=“lowest”)Info came from here:
Thanks
Thanks. predict() is indeed useful after the training is over, while I want to use callback that outputs a sequence of [input,target,preds] of images and save them in a folder every epoch (while training)
I think vision_learner replaces cnn_learner.
cnn_learner was built at the time when CNN base algorithms like
were used for image-based tasks. As the use of transformer based architectures for image-based data has increased cnn_learner became vision_learner.
Its more than a name change, now we can use all the amazing models from timm
We should be able to use vision_learner for regression too, and you guessed it right. unet_learner is used for image segmentation.
After training the head, we unfreeze which trains the full model. I guess slice lets us use something called discriminative learning where we train groups of layers with different learning rates.
Thanks for the info!
Just questions to clarify:
timm's models so much more incredible?vision_learner for training where the output is an image as well?unet_learner with vision_learner, but got an error that the input tensor only got two axis [bs,ch] rather than the four axis [bs,ch,h,w])Timm models offer a consistent API and pretrained weights for 100’s of models. You can check the kaggle kernel by Jeremy to explore more.
fastai fine_tune method just trains the head for 1 epoch. If the dataset is similar to imagenet I would finetune longer and if it is different I usually train by unfreezing from start. It works for me, you can play with different choices to get a feel of it.
When you want to predict an image I think you should be using unet_learner. It is called segmentation.
Thanks!
It’s funny to say, but when I use freeze() without unfreeze() afterward, I get my training metric goes better at a linear rate. That’s even more impressive. Could I say that it’s just that my dataset very resembles the ImageNet?
With timm models, could it mean that I may use a better model of Resnet50? That is, being pretrained on a much more diverse dataset than ImageNet?
I did some similarity projects (vision and text) and if you want really good results you’ll have to find a training objective to fine tune your model on the task. The features after pooling work fine - e.g. in fastai I just take the concat-pool outputs. There are differences in avg pool, max pool and concat pool but all are ok.
Why fine-tune? Self supervised trained models (nlp / vision) or models pretrained on ImageNet don’t work that well - the results often aren’t similar in a human sense.
How to fine-tune (from easy 1 to hard 3)?
1a) vision: self supervised pretraining on your dataset instead of using a pretrained model e.g. Self Supervised Learning with Fastai | self_supervised
1b) text: fine-tune your language model on your dataset
2) vision + nlp: do you have a label dataset? train a classifier. better: train a multi label model - it doesn’t matter how good the models work but classes / labels will produce similar feature vectors.
3) vision + nlp: contrastive learning will give the best results but it’s often hard / impossible to create the required dataset (quality and size) e.g. sentence transformers for nlp https://www.sbert.net
If you want something that works out of the box and it’s a real world dataset (photos) I’d just use CLIP: GitHub - rom1504/clip-retrieval: Easily compute clip embeddings and build a clip retrieval system with them 
I just have a weird question:
Does training a dataset have momentum?
Meaning, will I reach the same maximum potential in both ways:
Imagine this as if I squeeze an orange juice. Will I be able to gain the same juice by squeezing it fast and forcibly, or slowly with low efforts? Or would it yield different results?
Very different results!
BTW @Danrohn most of your questions are actually answered at length in the book - because they’re very good and important questions, and they’re the questions we try to ensure are answered. Full answers to them require a book length treatment - which is what we have!
So I’d strongly recommend making your way through the book, since it’s going to tell you exactly what you’re trying to understand
(Which is not a way of discouraging you from asking - but I don’t have a better answer than what’s in the book, so I’m not going to be able to add much here…)
resnet50 implementation across torchvision and timm are almost identical.
So we will find similar results. The advantage what timm offers is access to 100’s of models, and Ross Wightman continuously updates his repo with the latest models and weights for it.
Just to clarify what learn.fine_tune does is:
You can technically pass in the number of epochs that only the head is trained for (the default being 1). I recommend checking out the source code for Learner.fine_tune.
The idea is that the first two layers are untrained (we add a custom head after all) so instead we train just the head to “calibrate” it with the rest of the model. Then we can unfreeze and train the whole model much more easily.
This is definitely an interesting observation and it is likely that indeed the datasets closely resembles ImageNet so you don’t really need to adjust the body of the model. As a side point, make sure your validation metrics are improving, not just your training metrics.
Hey man! Your messages, like once, are clarified as cutting butter with a warm knife. Thanks!
Your explanation is wonderful, but I already figured out this by looking at the source code, and by reading this:
I have kept reading those explanations so many often, but it ain’t feeling so clear to me. If I don’t unfreeze(), would it mean that the “body” stays untrained?
This is definitely an interesting observation and it is likely that indeed the datasets closely resembles ImageNet so you don’t really need to adjust the body of the model. As a side point, make sure your validation metrics are improving, not just your training metrics.
Yes, both the valid_loss and the metrics go better, without overfitting.
| epoch | train_loss | valid_loss | ssim | psnr | time |
|---|---|---|---|---|---|
| 0 | 0.236554 | 0.208531 | 0.183433 | 11.753738 | 02:09 |
| 1 | 0.179139 | 0.148908 | 0.236383 | 13.805398 | 02:05 |
| 2 | 0.164469 | 0.179590 | 0.292767 | 12.279366 | 02:06 |
| 3 | 0.144973 | 0.139101 | 0.338365 | 14.361961 | 02:05 |
| 4 | 0.132566 | 0.115691 | 0.383597 | 15.746257 | 02:05 |
| 5 | 0.123076 | 0.140860 | 0.408780 | 14.752694 | 02:05 |
| 6 | 0.124454 | 0.101365 | 0.442580 | 16.926208 | 02:05 |
| 7 | 0.112748 | 0.102430 | 0.499645 | 16.352867 | 02:04 |
| 8 | 0.108559 | 0.099927 | 0.507152 | 17.267815 | 02:04 |
| 9 | 0.108745 | 0.096709 | 0.531147 | 17.573277 | 02:02 |
| 10 | 0.131972 | 0.105292 | 0.546981 | 16.911779 | 02:03 |
| 11 | 0.122663 | 0.106509 | 0.569845 | 17.131609 | 02:06 |
| 12 | 0.117344 | 0.116483 | 0.586394 | 16.417915 | 02:06 |
| 13 | 0.118717 | 0.096780 | 0.601940 | 17.860203 | 02:02 |
| 14 | 0.109777 | 0.108330 | 0.622874 | 16.764353 | 02:02 |
| 15 | 0.107149 | 0.086118 | 0.636838 | 18.321262 | 02:02 |
| 16 | 0.099475 | 0.098193 | 0.657461 | 17.738472 | 02:04 |
| 17 | 0.100719 | 0.132301 | 0.639843 | 15.730131 | 02:04 |
| 18 | 0.111611 | 0.107994 | 0.666687 | 16.818670 | 02:03 |
| 19 | 0.111105 | 0.120799 | 0.679617 | 16.494234 | 02:03 |
| 20 | 0.114704 | 0.207559 | 0.639382 | 12.127844 | 02:04 |
| 21 | 0.099970 | 0.098086 | 0.707660 | 17.849594 | 02:03 |
| 22 | 0.099835 | 0.089594 | 0.700292 | 18.560604 | 02:01 |
| 23 | 0.106707 | 0.138295 | 0.674177 | 15.729656 | 02:04 |
| 24 | 0.099064 | 0.073961 | 0.725095 | 20.033642 | 02:03 |
| 25 | 0.102635 | 0.084740 | 0.737844 | 18.210724 | 02:06 |
| 26 | 0.108957 | 0.155416 | 0.677125 | 14.684962 | 02:01 |
| 27 | 0.100712 | 0.096362 | 0.740240 | 18.032732 | 02:02 |
| 28 | 0.091303 | 0.098734 | 0.757668 | 17.141289 | 02:03 |
| 29 | 0.095276 | 0.082612 | 0.747881 | 18.612074 | 02:01 |
| 30 | 0.090979 | 0.079308 | 0.766427 | 19.219879 | 02:02 |
| 31 | 0.088959 | 0.062391 | 0.781548 | 21.137724 | 02:05 |
| 32 | 0.092504 | 0.070026 | 0.772093 | 19.750147 | 02:01 |
| 33 | 0.087208 | 0.074354 | 0.783176 | 19.588976 | 02:05 |
| 34 | 0.083044 | 0.066101 | 0.794248 | 19.470947 | 02:01 |
| 35 | 0.080781 | 0.075523 | 0.785750 | 18.851494 | 02:04 |
| 36 | 0.076060 | 0.088846 | 0.795860 | 16.493053 | 02:01 |
| 37 | 0.074469 | 0.068146 | 0.805137 | 19.896648 | 02:04 |
| 38 | 0.071076 | 0.070530 | 0.806764 | 20.062801 | 02:03 |
| 39 | 0.075082 | 0.070611 | 0.802137 | 20.234707 | 02:01 |
| 40 | 0.076525 | 0.073114 | 0.810220 | 18.325096 | 02:05 |
| 41 | 0.070763 | 0.070393 | 0.813122 | 18.819860 | 02:05 |
| 42 | 0.068504 | 0.073804 | 0.805940 | 18.706667 | 02:05 |
| 43 | 0.065610 | 0.068306 | 0.816073 | 19.237278 | 02:02 |
| 44 | 0.060239 | 0.064983 | 0.826524 | 19.970503 | 02:04 |
| 45 | 0.064982 | 0.084969 | 0.812253 | 18.099051 | 02:03 |
| 46 | 0.059241 | 0.054122 | 0.831039 | 21.738705 | 02:05 |
| 47 | 0.056639 | 0.056747 | 0.836223 | 22.513317 | 02:02 |
| 48 | 0.057209 | 0.046792 | 0.846990 | 24.197918 | 02:05 |
| 49 | 0.056328 | 0.046437 | 0.846901 | 23.958132 | 02:03 |
| 50 | 0.054749 | 0.047320 | 0.850570 | 24.019894 | 02:03 |
| 51 | 0.051009 | 0.047988 | 0.852203 | 23.820242 | 02:05 |
| 52 | 0.050929 | 0.047600 | 0.850500 | 24.071835 | 02:06 |
| 53 | 0.051956 | 0.043077 | 0.862234 | 24.669596 | 02:03 |
| 54 | 0.050984 | 0.043307 | 0.857978 | 24.458191 | 02:06 |
| 55 | 0.048370 | 0.046028 | 0.858897 | 23.934223 | 02:04 |
| 56 | 0.048205 | 0.044067 | 0.861460 | 24.493036 | 02:06 |
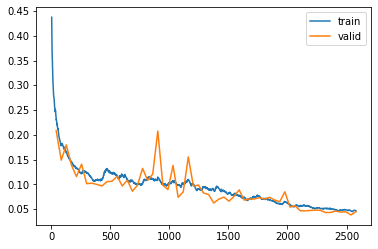
I reached up to ssim=0.90.
I used fit_one_cycle() but I tried to squeeze it even more by using a callback ReduceLROnPlateau(), but it seems to not work on the case of fit_one_cycle (the lr doesn’t get updated). So then I tried fit(), on which that callback does work, but the performance is slightly lesser than with fit_one_cycle(). What am I doing wrong, then?
Yeah, it means that the “body” remains as the ImageNet-pretrained weights and is not adjusted any further through training.
This is expected ,ReduceLROnPlateau() is meant to be used just with fit and is kind of a (dynamic) LR schedule itself so it doesn’t work with other LR schedules. Sounds to me like fit_one_cycle is better for your use-case then.
What problem are you working on? Given that you are going SSIM and PSNR metrics, sounds like maybe an image super-resolution or restoration project?
Thanks for the snippet here. These are sometimes like grain salt on a medium-well steak. 
I’ll probably be glad to start using timm models as well as torchvision's