That’s definitely interesting! Nice find there. My hope is that was a comparison between Pillow and opencv’s python api. Probably worth trying bindings for opencv’s cpp api to give a fair comparison.
I’d say opencv tends to be faster than pillow across more areas - although pillow-simd has a few very optimized pieces.
1 Like
The latest master now supports setting SwiftPM flags for the packages that you install. Add %install-swiftpm-flags to the same cell where you have %install, and it’ll set those flags for all the packages that it’s installing. For example,
%install-swiftpm-flags -Xswiftc -Ounchecked -Xcc -ffast-math -Xcc -O2 -Xcc -march=native
%install '.package(url:"https://github.com/jph00/BaseMath.git", from: "1.0.0")' BaseMath
I checked and the flags seem to be actually doing something. For example, this snippet changes from ~3ms for me without the above flags to ~0.1ms with the above flags:
import BaseMath
let testArrN = 1_000_000
let testArr = (1...testArrN).map(Float.init)
time(repeating: 100) { testArr.sum() }
2 Likes
Super great @marcrasi! Is there a way to have our actual notebook code compile with flags too?
The Jupyter kernel calls directly into internal bits of the Swift compiler’s C++ implementation, bypassing the flag-parsing piece of the compiler. So there is no place to pass flags in.
If there are particular sets of flags that you are interested in, I could add some configuration options to the Jupyter kernel that cause it to invoke the Swift compiler internal bits in the same way that the flags would have invoked those internal bits.
Currently, it’s hardcoded to compile as if you passed “-O”.
Thanks! The flags used in BaseMath would be perfect. ![]()
So, just -Ounchecked, because all the other flags are C compiler flags that have no effect on compilation of Swift code?
Oh yeah good point - yes just that then. What I really want is the equivalent of -ffast-math for swift code. I don’t suppose there’s any way to do that, is there? It makes a huge difference in practice to the C code we use in ML, and the teeny tiny changes it makes to behavior are vanishingly unlikely to impact ML use cases (or really anything other than highly specialized code AFAICT).
It should be possible to pass flags to LLVM with -Xllvm. I’m not sure if LLVM has a ffast-math equivalent, or if it’s even helpful to do ffast-math by the time the code has been lowered all the way to LLVM IR.
Maybe “-enable-unsafe-fp-math”? I’ll play with this a bit and see if it does anything.
That would be super. I tried a few things thru the compiler frontend a couple of months ago but nothing would stick.
It’s sum() that’s the problem. Because strictly speaking you can’t do it in parallel due to fp semantics - although it would be very odd code that cared about such a thing in practice! So without fast/unsafe-math it doesn’t vectorize sums. And in DL we do a lot of sums! ![]()
Hmm, I asked our swiftc what the LLVM options are with swiftc -Xllvm -help, and -enable-unsafe-fp-math isn’t one. Maybe it doesn’t actually exist.
Yes that’s what I tried too. Hoping there’s something in the compiler bowels that does it! Because I don’t see why it shouldn’t be possible. Perhaps it’s just never been surfaced…
Made a really simple OpenCV wrapper here!
It can load an image, do listed manipulations and convert to ShapedArray/Tensor that displays correctly via Python integration:
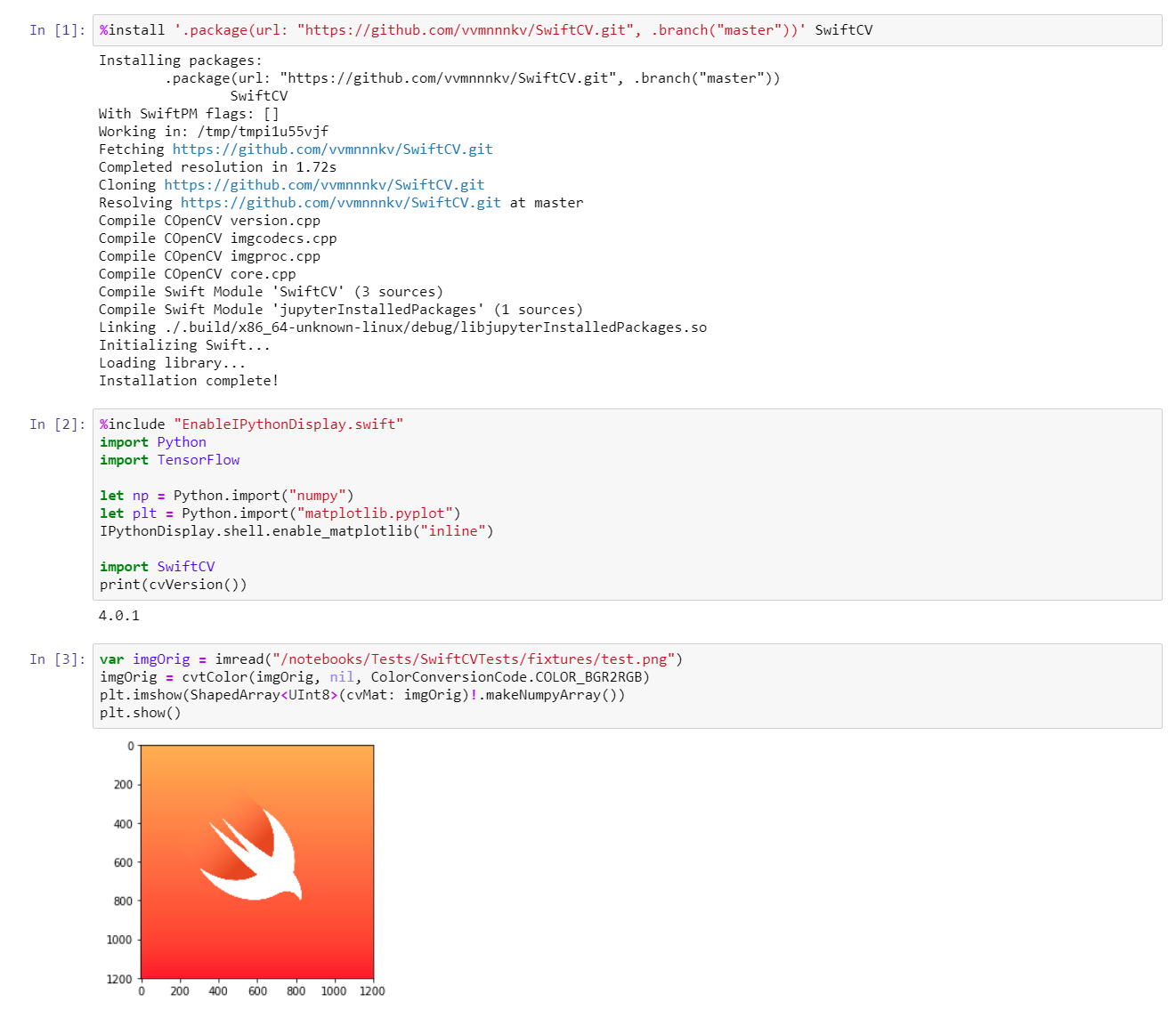
To run this notebook I used modified swift-jupyter docker image that has opencv4 installed. OpenCV itself is compiled with jpeg-turbo and native optimizations, but I didn’t try benchmarking yet. I’ll probably try to load & resize imagenette and compare with PIL.
The API is very simple and doesn’t feel Swifty :), basically it just resembles Python or CPP API.
I don’t like that the image is exposed as OpenCV’s Mat type in Swift (vs. in Python it uses numpy array) but otherwise it seems slower to convert image back and forth in the processing pipeline because OpenCV functions operate on Mat.
I’d love to hear any suggestions on better module API design!
5 Likes
Looks like cv::Mat can be constructed in a fashion where it aliases memory provided to it: https://docs.opencv.org/4.1.0/d3/d63/classcv_1_1Mat.html#a9fa74fb14362d87cb183453d2441948f
I believe python tensorflow / pytorch have aliasing constructors which lets them interop well with with numpy. Theoretically, all these overheads should be able to be eliminated and let you use a single uniform tensor type.
1 Like
I’m so happy to see this!  @clattner @saeta I think this would be a great example of interfacing with C for the course, since many fast.ai students are already familiar with opencv from the v0.7 lib, and many people know of it as the fastest CV lib around. We could also build on this to create a much more swifty harebrain vision library than the tf.data approach we have now - and that could also leverage much of the work that happened for fastai v0.7 (I was actually pretty happy with that bit of the library, and was sad to have to leave it behind due to the problems with opencv and python multiproc compatibility.
@clattner @saeta I think this would be a great example of interfacing with C for the course, since many fast.ai students are already familiar with opencv from the v0.7 lib, and many people know of it as the fastest CV lib around. We could also build on this to create a much more swifty harebrain vision library than the tf.data approach we have now - and that could also leverage much of the work that happened for fastai v0.7 (I was actually pretty happy with that bit of the library, and was sad to have to leave it behind due to the problems with opencv and python multiproc compatibility.
@vova would you be interested in creating a little jupyter notebook demonstrating opening and manipulating images, and doing a PR here with it?: https://github.com/fastai/fastai_docs/tree/master/dev_swift . It doesn’t have to be anything fancy - just a minimal demo. I’d love to show off how easy Swift/C interfacing is! 
This looks great! If I understand it correctly you just need to have the OpenCV libraries installed in your system, is that right? So there’d be no need in running jupyter from the docker image.
Thank you all for feedback,
Interesting, I’ll definitely try that for Tensor → cv::Mat conversion (right now it’s not implemented ![]() ). But when converting in the opposite direction (cv::Mat → Tensor), it seems that the data must be contiguous? I’ve actually borrowed code from
). But when converting in the opposite direction (cv::Mat → Tensor), it seems that the data must be contiguous? I’ve actually borrowed code from PythonConversion.swift and doing the same check for cv::Mat using isContinuous() and making cv::Mat clone if it’s not. If I understand correctly, some operations on cv::Mat can make it non-continuous and making it continuous in order to convert to Tensor may result in additional overhead.
As for numpy to tensor conversion in TF & pytorch, I can’t quite follow when they copy memory and when alias.
There might be difficulties with running that notebook. Are your swift_dev notebooks supposed to be working in colab and locally using official swift-jupyter or Jeremy’s Harebrained installation procedures?
Wrapper expects that OpenCV is installed and so far I’ve only tested it with OpenCV 4.0.1 compiled from source.
Not sure how to better tackle that - perhaps for colab I could start notebook with executing commands to compile/install OpenCV (e.g. using shellCommand from 00_load_data). For local installation I could create additional prep script like your gist and check these scripts together?
Note that OpenCV compilation is rather time consuming ![]() I can check if wrapper works with binary distribution (i.e. from conda), but it probably won’t be compiled for max performance in that case.
I can check if wrapper works with binary distribution (i.e. from conda), but it probably won’t be compiled for max performance in that case.
So far I’ve only checked it with Ubuntu 18 and OpenCV 4.0.1 compiled/installed from source. Docker itself is not required (I just don’t have another option in Win10 ![]() )
)
You can see commands used to build OpenCV in this Dockerfile.
Don’t worry about opencv installation or colab. Just a notebook that works in regular jupyter and assumes opencv is already installed would be fine.
Just a couple of notes for those compiling from source and not using the docker container @vova created.
- Compilation without cuda is easier and it’s not really necessary at this point, so consider a simple cuda-less build first.
- After building and installing, ensure that the Swift process is able to find the OpenCV libraries. My OpenCV libraries were installed to
/usr/local/lib, so I created the following file and then runldconfig:
(env) pedro@deep-hack:s4tf$ cat /etc/ld.so.conf.d/opencv.conf
/usr/local/lib/
- I compiled OpenCV version
4.1.0instead of4.0.1and I could successfully replicate @vova’s test notebook!
If you do want to include cuda support, keep these in mind:
- I had to install Nvidia’s Video Codec SDK, in addition to the cuda and cuDNN libraries I already had. Note that the package is behind a registration wall.
- Ensure that Nvidia’s
nvcccompiler is the one installed alongside the cuda library. I had a copy in/usr/bin/nvccthat was used instead of the one in/usr/local/cuda/bin/nvcc. If the build process fails and complains about unsupportedgccversions, this is why.
1 Like
I don’t think there’s any need to use opencv’s cuda support afaict, at least for now.