I tried it and got this error: RuntimeError: Expected object of scalar type Long but got scalar type Float for argument #2 'other'.
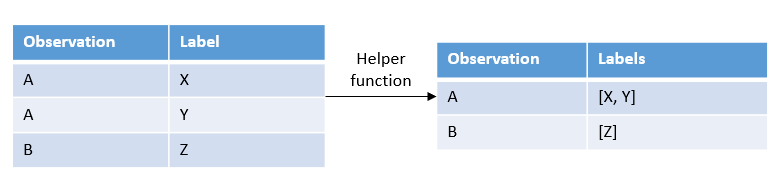
I think the model doesn’t handle the input and output for the metric correctly. I now use data in the following format (list of tags, not one-hot-encoded), where rm is a list of my labels:

The number of output features (targets) is correct, i.e. equal to my number of classes and the classes were also correctly identified in the classes.txt. This is model’s summary
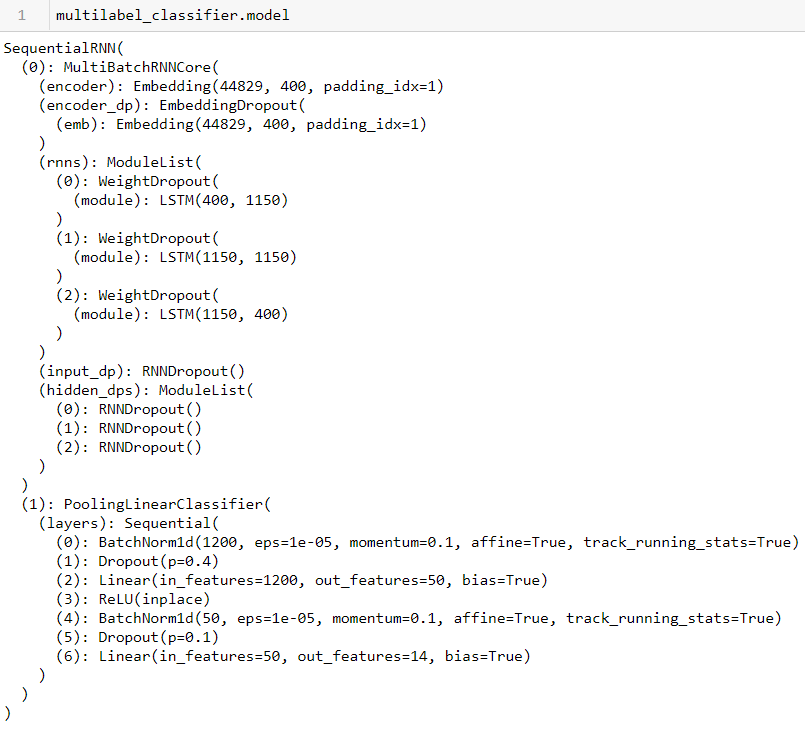
And my code:
data_lm = TextLMDataBunch.from_df(path, train_df, valid_df, test_df, bs=48, text_cols = 'fulltext')
learn = language_model_learner(data_lm, pretrained_model = URLs.WT103)
learn.unfreeze()
learn.fit_one_cycle(1, 1e-2, moms = (0.8, 0.7))
learn.save_encoder('lm_encoder')
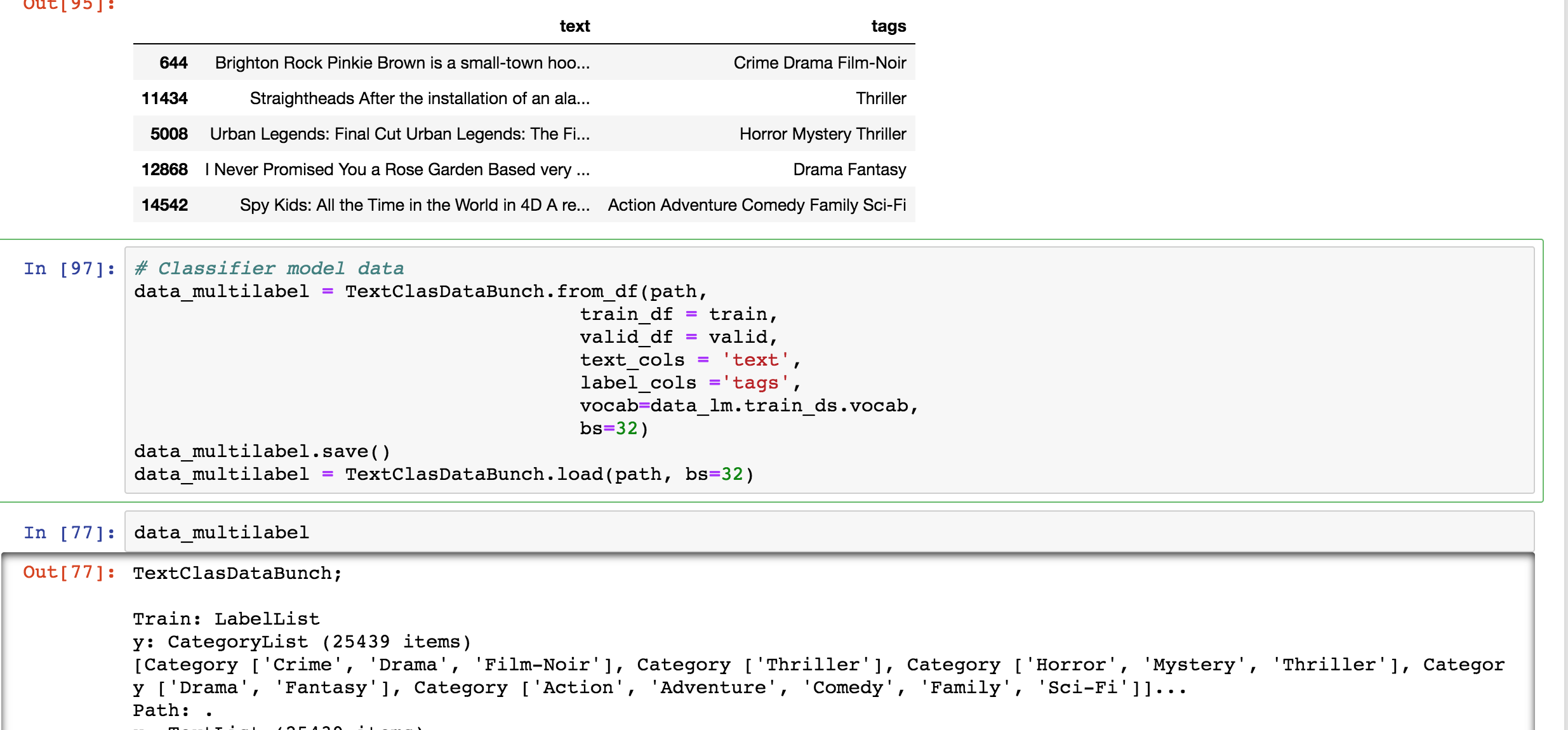
multilabel_data = TextClasDataBunch.from_df(path, train_df, valid_df, bs=32,
text_cols = 'fulltext', label_cols ='rm', vocab=data_lm.train_ds.vocab)
multilabel_classifier = text_classifier_learner(multilabel_data)
multilabel_classifier.load_encoder('lm_encoder')
multilabel_classifier.freeze()
multilabel_classifier.fit_one_cycle(1, 1e-2, moms = (0.8,0.7))
How can I fix this error? Is this due to the wrong metric/loss? (I use defaults: accuracy, FlattenedLoss)
Here is the entire error log:
RuntimeError Traceback (most recent call last)
<ipython-input-16-ba28a844a782> in <module>()
4 multilabel_classifier.load_encoder('lm_encoder')
5 multilabel_classifier.freeze()
----> 6 multilabel_classifier.fit_one_cycle(1, 1e-2, moms = (0.8,0.7))
~/.local/lib/python3.6/site-packages/fastai/train.py in fit_one_cycle(learn, cyc_len, max_lr, moms, div_factor, pct_start, wd, callbacks, **kwargs)
19 callbacks.append(OneCycleScheduler(learn, max_lr, moms=moms, div_factor=div_factor,
20 pct_start=pct_start, **kwargs))
---> 21 learn.fit(cyc_len, max_lr, wd=wd, callbacks=callbacks)
22
23 def lr_find(learn:Learner, start_lr:Floats=1e-7, end_lr:Floats=10, num_it:int=100, stop_div:bool=True, **kwargs:Any):
~/.local/lib/python3.6/site-packages/fastai/basic_train.py in fit(self, epochs, lr, wd, callbacks)
164 callbacks = [cb(self) for cb in self.callback_fns] + listify(callbacks)
165 fit(epochs, self.model, self.loss_func, opt=self.opt, data=self.data, metrics=self.metrics,
--> 166 callbacks=self.callbacks+callbacks)
167
168 def create_opt(self, lr:Floats, wd:Floats=0.)->None:
~/.local/lib/python3.6/site-packages/fastai/basic_train.py in fit(epochs, model, loss_func, opt, data, callbacks, metrics)
92 except Exception as e:
93 exception = e
---> 94 raise e
95 finally: cb_handler.on_train_end(exception)
96
~/.local/lib/python3.6/site-packages/fastai/basic_train.py in fit(epochs, model, loss_func, opt, data, callbacks, metrics)
87 if hasattr(data,'valid_dl') and data.valid_dl is not None and data.valid_ds is not None:
88 val_loss = validate(model, data.valid_dl, loss_func=loss_func,
---> 89 cb_handler=cb_handler, pbar=pbar)
90 else: val_loss=None
91 if cb_handler.on_epoch_end(val_loss): break
~/.local/lib/python3.6/site-packages/fastai/basic_train.py in validate(model, dl, loss_func, cb_handler, pbar, average, n_batch)
52 if not is_listy(yb): yb = [yb]
53 nums.append(yb[0].shape[0])
---> 54 if cb_handler and cb_handler.on_batch_end(val_losses[-1]): break
55 if n_batch and (len(nums)>=n_batch): break
56 nums = np.array(nums, dtype=np.float32)
~/.local/lib/python3.6/site-packages/fastai/callback.py in on_batch_end(self, loss)
237 "Handle end of processing one batch with `loss`."
238 self.state_dict['last_loss'] = loss
--> 239 stop = np.any(self('batch_end', not self.state_dict['train']))
240 if self.state_dict['train']:
241 self.state_dict['iteration'] += 1
~/.local/lib/python3.6/site-packages/fastai/callback.py in __call__(self, cb_name, call_mets, **kwargs)
185 def __call__(self, cb_name, call_mets=True, **kwargs)->None:
186 "Call through to all of the `CallbakHandler` functions."
--> 187 if call_mets: [getattr(met, f'on_{cb_name}')(**self.state_dict, **kwargs) for met in self.metrics]
188 return [getattr(cb, f'on_{cb_name}')(**self.state_dict, **kwargs) for cb in self.callbacks]
189
~/.local/lib/python3.6/site-packages/fastai/callback.py in <listcomp>(.0)
185 def __call__(self, cb_name, call_mets=True, **kwargs)->None:
186 "Call through to all of the `CallbakHandler` functions."
--> 187 if call_mets: [getattr(met, f'on_{cb_name}')(**self.state_dict, **kwargs) for met in self.metrics]
188 return [getattr(cb, f'on_{cb_name}')(**self.state_dict, **kwargs) for cb in self.callbacks]
189
~/.local/lib/python3.6/site-packages/fastai/callback.py in on_batch_end(self, last_output, last_target, **kwargs)
272 if not is_listy(last_target): last_target=[last_target]
273 self.count += last_target[0].size(0)
--> 274 self.val += last_target[0].size(0) * self.func(last_output, *last_target).detach().cpu()
275
276 def on_epoch_end(self, **kwargs):
~/.local/lib/python3.6/site-packages/fastai/metrics.py in accuracy(input, targs)
37 input = input.argmax(dim=-1).view(n,-1)
38 targs = targs.view(n,-1)
---> 39 return (input==targs).float().mean()
40
41 def error_rate(input:Tensor, targs:Tensor)->Rank0Tensor:
RuntimeError: Expected object of scalar type Long but got scalar type Float for argument #2 'other'