A more detailed note on walkthru 8
00:00 starting with question and answer session
How to get things set up in a local machine?
04:44 - How to set up kaggle on a local machine?
09:47 - Setting up to run on your own GPU server locally and remotely
pathlib
14:17 What is the pathlib? From where do import this library? How do we use Path() or what can we put in as parameters? (I need to experiment on notebook and visualize examples myself)
check multiple file sizes in normal and parallel ways
15:40
How to time a program in jupyter cell?
Explore fastcore.parallel
16:50
When parallel makes a difference
How to write a lambda function inside another function
20:52
Build an ImageDataLoaders from folder and do image transform
22:03
How to pick a better model from TIMM
23:02
How to install TIMM and find exact model names
24:28
Don’t forget metrics when building a vision_learner
28:34
Explore learn.fine-tune
30:52
Explore half-precision floating point
32:11
Why use it?
When to use it?
How to use it?
How much better/faster can it get us?
(jump in time 41:29)
Install the latest TIMM on paperspace
33:56
Explore fit_one_cycle
34:32
What does scheduler do?
Why do we start with very small learning rate for even pretrained models?
When and how to increase learning rate?
When and why to decrease learning rate again?
How to increase and decrease learning rate? (in a cycle, through cosine)
How to choose a one-cycle policy?
Explore learn.lr_find
41:13
How does lr_find differ from fit_one_cycle?
How to read the graph of lr_find in terms of slope, bottom, the suggested lr rate, etc?
Why we shouldn’t pick the bottom point for learning rate?
What are the 4 suggested points for learning rate and the ideas behind them?
When to use or not use default learning rate? and why and how?
small points: update learner by lr_find and a second tab
48:20
Will we create a new learner when we run learn.lr_find? yes
Why should we make another copy of the notebook when the original is running? to work on the next thing while the model is training
Explore DataLoaders.test_dl
48:57
What should you do when you want to explore a method which you don’t remember which class it belongs to?
What does DataLoaders.test_dl do?
How to apply DataLoaders.test_dl to test dataset?
Explore learn.get_preds
51:46
What’s the difference between learn.predict and learn.get_preds?
How to quickly check all the parameters of learn.predict? shift + tab
How to get the kaggle submission format right
52:47
Let’s check with the kaggle submission sample csv file
How to autocomplete filenames when you do things like pd.read_csv("")? just write something and press tab
Where to look in order to be certain about the format of kaggle submission format? the sample csv and kaggle site for evaluation
Explore learn.get_preds continued
54:13
How to make learn.get_preds give us the specific label answer instead of the probabilities of all labels for each test item?
What does with_decoded parameter can do to get us the label?
How to access each part when learn.get_preds returns 3 parts?
How to access all the labels of the dataset or DataLoaders? dls.vocab
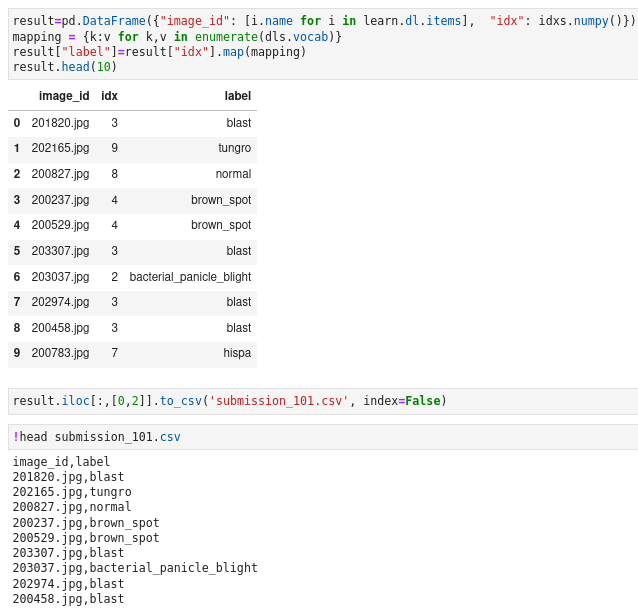
How to map idxs with label vocab with pandas
55:05
How to turn a list or a TensorBase into a pandas Series and add a name to it with name parameter?
How to use pd.map? (exploration is needed)
How to check the type of dls.vocab? type(dls.vocab)
How to turn dls.vocab into a list? list(dls.vocab)
How to create a dictionary on dls.vocab? 57:53
How to use a dictionary with pd.Series.map ( a neat trick of Jeremy’s that no one knows)? 59:46
Why we are not adviced to use a function or lambda to do pd.Series.map?
How would we do a lambda with pd.Series.map anyhow?
How to add our prection results into the kaggle submission csv file?
Visually check results and submission format
1:00:17
What does Jeremy normally do for checking results for correctness? learn.show_batch()
How to turn the final result pandas file into a csv file with ? ss.to_csv("subm.csv")
How to check the format correctness? do it in terminal with ! head subm.csv
What can index=False do for our submission format?
ss.to_csv("subm.csv", index=False)
How to submit with kaggle CLI
1:02:11
How to use kaggle -h, kaggle competitions -h, kaggle competitions submit -h to learn the command we need to use?
What to do when test dataset get shuffled
1:06:15
Where did the dataset get shuffled? get_image_files()
Can we just sort the our result to have the same order as the submission file? tst_files.sorted()
When will this kind of sorting won’t work?
How does sort() differ from sorted()? inplace or not
What to do when timm is not defined
1:10:23
You can either import timm again or restart the kernel in the notebook