is it possible that it would trigger for “a photograph of an astronaut riding a horse” and that for steps 1 and 2 is black and for step 3 is nosiy image?
Well, can’t argue much here but that wording might make some NSFW results. For these kinds of stuff, I suggest posting (or searching) on the StableDiffusion subreddit.
lol and I thought stable diffusion was going to be the last lesson. Spent the last 3-6 months trying to get my head around it and JH does it in one hour. (╯°□°)╯︵ ┻━┻
Anyway, here are my notes. J refers to JH: and my questions are S:.
Let me know if there is a better place to post these notes as I plan to do this for the rest of the lectures too.
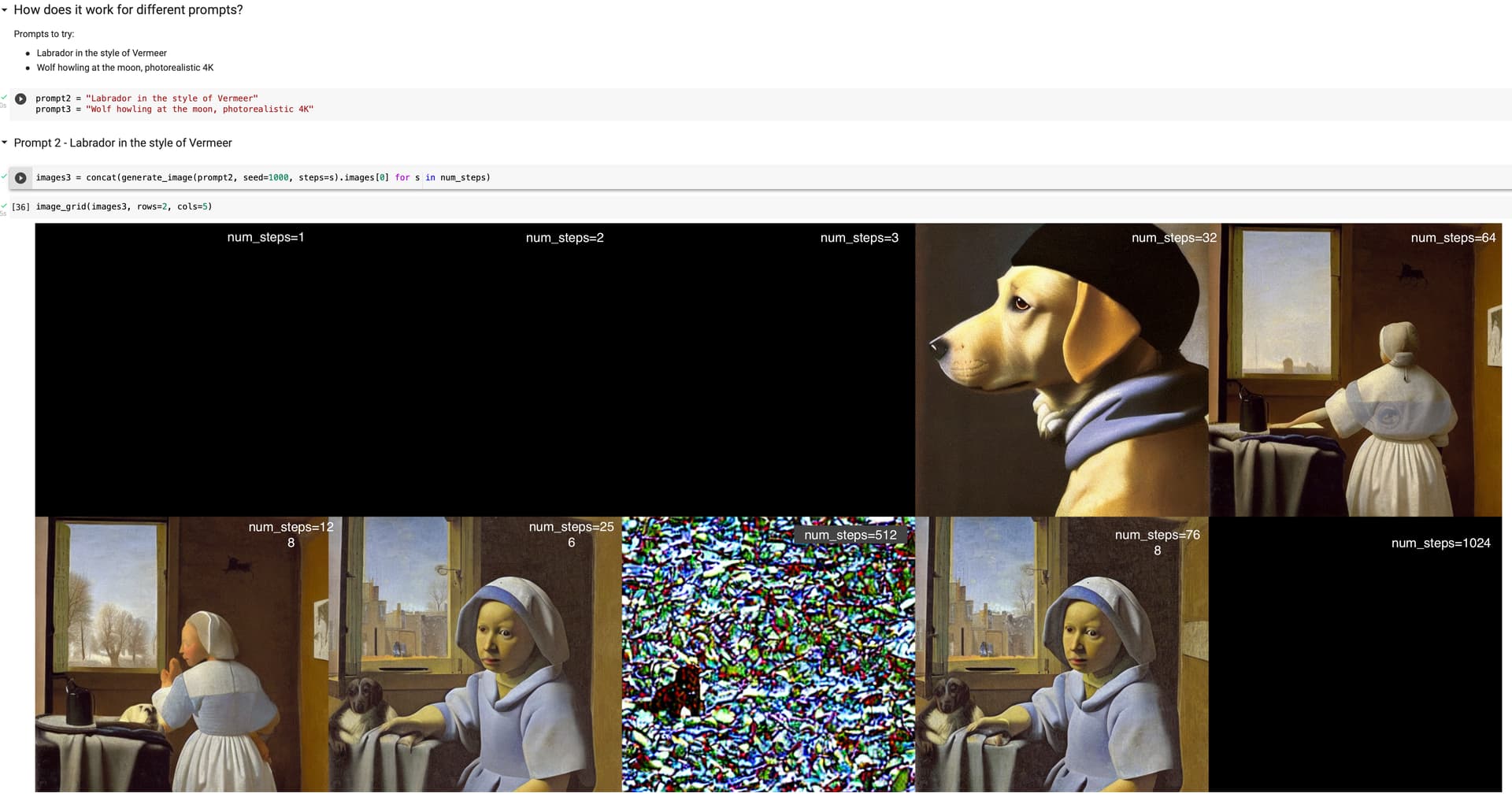
Yes. The results seem reasonable maybe upto step 64. Hugging face pipeline uses 50 as default.
For very large steps, around 512, there was noise similar to step 2. Again at num_steps 768, there was some image, very similar in appearance to num_steps 256. Happened for all the cases I tried.
I have the same feeling. I stopped at 100, here are my results:\
torch.manual_seed(1024)
num_rows,num_cols = 5,5
l = list(range(2,100,4))
prompt="a photograph of an astronaut riding a horse"
images = concat(pipe(prompt, num_inference_steps=s, guidance_scale=7).images for s in l)
But when you are predicting the noise, it was the noise introduced artificially.
OTOH, if you want to draw the digit, it can have multiple possible outlines, and all of them will be correct.
The noise, on one picture, has one correct answer.
The digit, has many.
Edit: when we are talking about one image, the model does have only one digit. But we want variations. I think, if we try and make a model that gets the digits as opposed to the noise, it will reduce the variation in generated digits.
Have you tried using wrong spelling for generating images not permitted?
Some people tried that with Dall-E 2 and they were able to generate images not officially supported then.
Photorealistic depition of public figures was not allowed by Dall-E before. But giving a prompt like- “Bbarackk Oobana sitting on a bench” returned positive results.
The model is so large and trained on so many images that it learns the mapping between wrong spellings and correct objects as well. The filters put in an ad-hoc mannet can’t catch these.
(I sometimes get better google search results by deliberately using wrong spelling. SEO clerks don’t take this into account, I guess.)
The essential idea, inspired by non-equilibrium statistical physics, is to systematically and slowly destroy structure in a data distribution through an iterative forward diffusion process. We then learn a reverse diffusion process that restores structure in data, yielding a highly flexible and tractable generative model of the data.
Using @johnowhitaker’s excellent example of showing the latent space manifold (Lesson 9A), adding normally distributed noise is equivalent to allowing these latent variables to “diffuse” away from the underlying data distribution and toward random noise.
If anyone has run into CUDA out of memory issues on their stable_diffusion.ipynb notebook, I’ve put up a quick and dirty fix as a pull request here: https://github.com/fastai/diffusion-nbs/pull/5 . This at least helped my12GB 3080 TI gpu. I’ll be looking at other ways to improve on this next (mostly based on this optimization recommendations page: https://huggingface.co/docs/diffusers/optimization/fp16 )
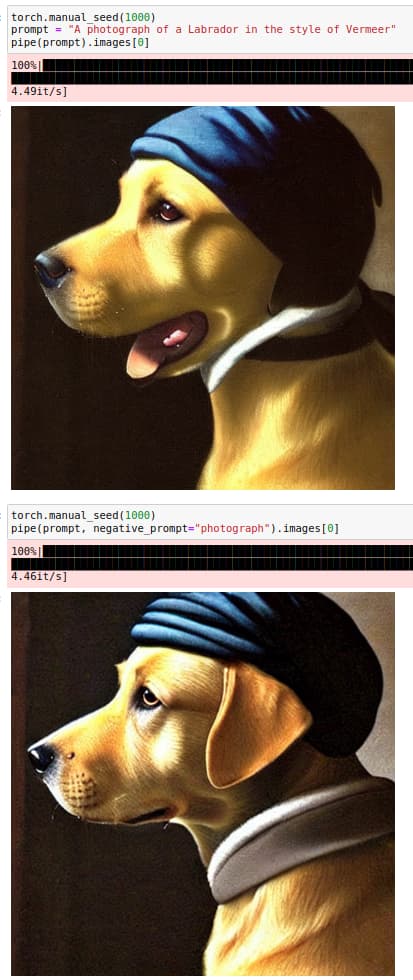
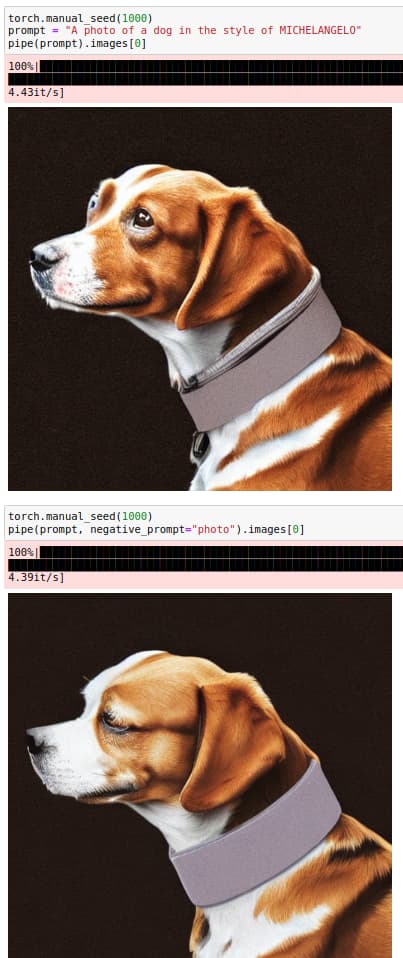
Negative prompt ideally should give a cluster, further way from the mentioned term. It seems to drag other embeddings as well. Does it have something to do with the artist? XD
Great first lecture! Saw in this paper [2208.09392] Cold Diffusion: Inverting Arbitrary Image Transforms Without Noise (linked from HN stable diffusion thread) that there is no requirement for noise to be Gaussian or even random, and can be any operation that degrades and restores the image. Wondering if anyone has any ideas on advantages/disadvantages of different approaches and if this could be an interesting direction to explore.
Here’s an interesting observation-new to me as a stable diffusion n00b at least: I get different results running through a 3080TI gpu versus a 1080TI gpu. All else is the same- the notebook code and the computer it’s running on:
I think it’s just small numerical differences occurring between the two cards that get compounded with the iterations but it’s interesting to see the effect.
Edited: For accuracy, clarity. I misread what was going on a bit.