Was the transformers updated needed for the pipei2i call or other parts of the notebook?
I’m running latest stable transformers, version 4.23.0.
Nope, it was for the first pipe(prompt) pipei2i is still failing for me. Trying to set up a new environment, since apparently there were some conflicts with fastbook. But I cannot work on it right now
It wasn’t produced by SD, was it…?? ![]()
1 Like
I was running into this problem using a gradient nb and finally got it to work. there are 2 separate things i did and at least one of them “worked” ![]()
- installed the latest transformers and diffusers libs using:
# i read above in the thread that we need a version of diffusers > 0.4.1
# there may be a better way, but i just installed from the latest commit
!pip install git+https://github.com/huggingface/diffusers.git@797b290ed09a84091a4c23884b7c104f8e94b128
!pip install transformers -U
- not sure how this could’ve helped, but i’m currently using paperspace gradient’s jupyterlab interface. after i reset my kernel and did (1) above, it still wasn’t working, so i flipped back over to paperspace’s homebrewed interface and everything ran just fine. it then worked again when i flipped back over to jupyterlab ¯_(ツ)_/¯
possibly related: here suggests that this error “happens when you try to switch to cpu”
4 Likes
Fp16 not expected
On paperspace gradient nb , with stable_diffusion.ipynb. when calling
pipe(prompt).images[0]
I get the following error, which seems to indicate that an internal library did not expect fp16.
Are there any additional recommendations for configuration given the revision=“fp16” ?
RuntimeError: expected scalar type Float but found Half
/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1100 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1101 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1102 return forward_call(*input, **kwargs)
1103 # Do not call functions when jit is used
1104 full_backward_hooks, non_full_backward_hooks = [], []
/opt/conda/lib/python3.7/site-packages/transformers/models/clip/modeling_clip.py in forward(self, hidden_states, attention_mask, causal_attention_mask, output_attentions)
254 attn_weights = attn_weights_reshaped.view(bsz * self.num_heads, tgt_len, src_len)
255 else:
--> 256 attn_weights_reshaped = None
257
258 attn_probs = nn.functional.dropout(attn_weights, p=self.dropout, training=self.training)
RuntimeError: expected scalar type Float but found Half
1 Like
Hey all, I wanted to share some Stable Diffusion related demos you can try out very quickly
- Stable Diffusion Stable Diffusion - a Hugging Face Space by stabilityai
- Diffuse the rest (image to image) Diffuse The Rest - a Hugging Face Space by huggingface-projects
- Inpainting Stable Diffusion Inpainting - a Hugging Face Space by multimodalart
- Outpainting with infinite canvas Stablediffusion Infinity - a Hugging Face Space by lnyan
- Waifu Diffusion Waifu Diffusion Demo - a Hugging Face Space by hakurei
- SD Conceptualizer (textual inversion) sd-concepts-library (Stable Diffusion concepts library)
- Japanese Stable Diffusion Japanese Stable Diffusion - a Hugging Face Space by rinna
29 Likes
Do we have to set torch.manual_seed each time before running pipe(prompt)? I got different images for cell with torch.manual_seed(1) set before pipe(prompt) and immediate cell with pipe(prompt).
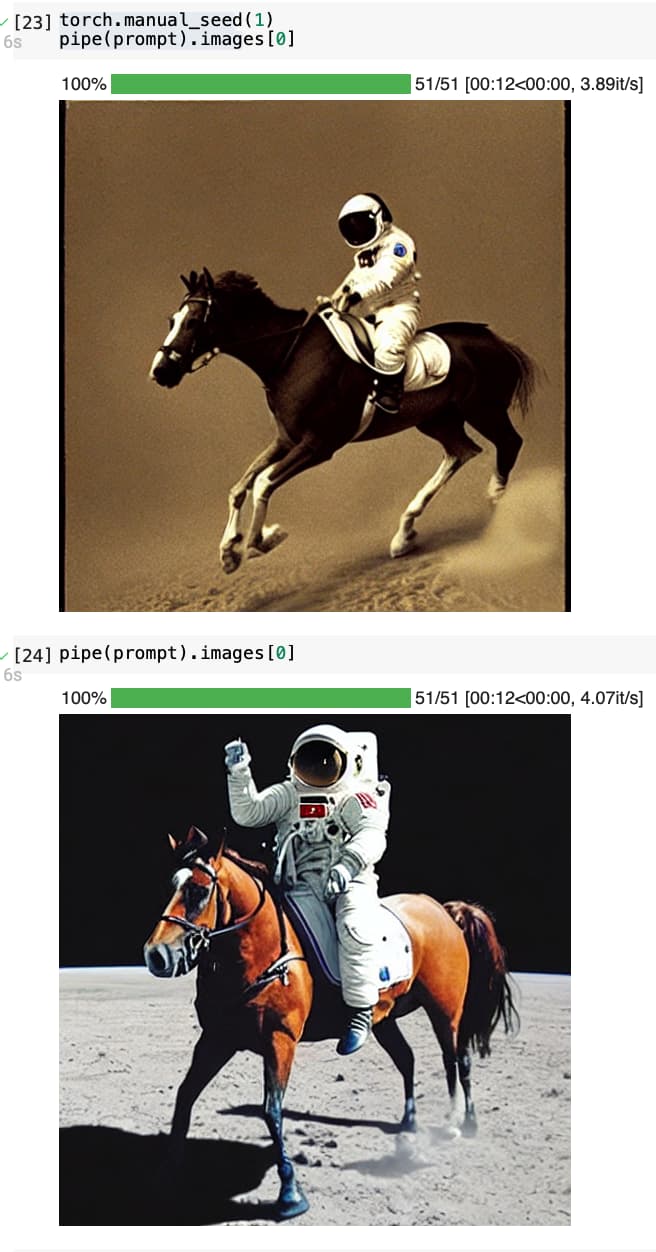
4 Likes
hey! i was running into that also. try this.
I keep running into this error regardless of cpu or cuda , due to the fp16
RuntimeError: "LayerNormKernelImpl" not implemented for 'Half'
1 Like
Folks please make sure you have the latest nvidia drivers and latest versions of transformers, pytorch, and diffusers. We’re working on the cutting edge now so expect to be updating these regularly!
19 Likes
Amazing lecture as always. Mind-blowing-level material!
I missed the last 10 minutes of it, so was wondering when the recording would be made available to this audience. In the past, I think it happened in a couple of days to give Jeremy the time to make the editing, but just checking.
4 Likes
It was a youtube stream so it became immediately available under the very same link, go for it! ![]()
3 Likes
I believe you need to run it each time because as per the doc torch.manual_seed returns a torch.Generator object, so their content is not stored in memory.
1 Like
My life just changed for the better ![]()
3 Likes
I feel you ![]()
1 Like
you gotta set it each time, and if you set it then the generation is deterministic as long as you repeat the same seed
1 Like
Make sure you have installed the latest versions of diffusers, transformers and pytorch, these work great for me for example:
pip install git+https://github.com/huggingface/diffusers.git@797b290ed09a84091a4c23884b7c104f8e94b128
pip install transformers -U
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
5 Likes
seen similar issues when the versions of pytorch, diffusers and transformers are not the very latest ones
2 Likes
Ah okay. Thanks!
1 Like
great question,
precision as well as other issues like bleed, sequences, text rendering etc are some of the areas where gen AI struggles, some of those have to do with what we call system-2 processes (of course, things are improving all the time, I expected something like phenaki to appear way in the future and its already here!!)
in any case, consider that you are locating a point in latent space and decoding it to produce the final image. That point in latent space will include a table but also other things related to your prompts. So it’s pretty difficult to tightly control something without affecting other things unless you do something like inpainting or outpainting. So basically, you create a transparent image with your Study Table on it. And then perform inpainting or outpainting to generate more content around the table without affecting the table and yeah that would be a way to make it work.