Medicine also invented one-shot learning: “See one, do one, train one”
Or the limitations of the diagnosis process: “Pathologists know everything but it’s too late”
3 Likes
Why do we calculate variance using y.pow(2).mean() instead of y.std().pow(2)?
Looking at the equation for standard deviation/variance I can see that using y.pow(2).mean() calculated the variance assuming a zero mean. I assume using y.std().pow(2) would calculate variance relative to the true mean of y.
Why did we choose to use the first form?
2 Likes
This lesson is actually what turned into that tutorial on the pytorch site. 
2 Likes
Very happy to hear that!
If the question is regarding advanced indexing in nll I am not sure how I arrived at it either. It might be I saw it somewhere (most likely pytorch forums) or that this way of doing it seemed to make sense to me at the point of writing the code.
This is just a tiny step really from going about this in any other way. I’m quite certain I was not born with it and if there was a process that led to it, it was working on mini-projects where I had to work directly with tensors and deal with their dimensionality. This often led to me googling and ending up on pytorch forums.
The pinnacle of such projects was working through the object detection notebook from part 2 v2. There were at least a couple of spots where some mind boggling APL inspired operations were happening. I don’t think I would be able to reproduce them without working through the notebook again, but at least it got me to start looking at operations on tensors in a new light (and start seeing data in tensors as useful input to indexing operations). I vaguely recall at some point max values across some dimension of one tensor were used to index into another tensor (to solve the matching problem) or something along these lines, so the advanced indexing here is just a simpler form of the idea.
Anyhow, not sure if this is the ‘indexing thing’ being discussed here, but if it is, I also was not born with it and probably got it from somewhere else. Might be I stole it from Jeremy though it might have been in a slightly different shape and form at the time the appropriation took place!
5 Likes
I note your implementation of exceptions, however I believe your are looking for a more elegant solution.
An alternative to your suggestion maybe a python pattern The Prebound Method Pattern
so i guess this is a global singleton.
looks like one have to use a global variable in order to avoid create a singleton pr import ?
Yes it is a singleton with global aliases to its methods. I don’t see how that can implement batch/epoch/train cancellation - @RogerS49 perhaps you could implement Runner to show us how it works in practice?
@jeremy Good job refactoring the callbacks with exceptions in lesson 10. It doesn’t feel like a code smell anymore.
1 Like
Yah I figured.
Btw, I’ve been doing fastai for awhile and lesson 9 was perhaps the best (it ranks right up there with lesson 6 and 7 of 2017 in my book). Don’t ask why I keep track of such things, I have some OCDs for sure 
2 Likes
I’m glad you thought so! What did you like about it? Knowing that will help me do more good stuff…
It made certain core things click … things that I can apply to just about everything I’m doing in this space.
With lesson 6/7 from 2017 it was RNNs. I was like, “Holy shit, I get it now.”
With lesson 9 it was the fastai framework … understanding how the bits fit together and how callbacks/hooks are used to implement SOTA training techniques. Things like one cycle seemed magical before lesson 9. Now, well it’s still magical but I’m like, “Oh, it’s just callbacks … I get it.” It gave me a better sense of what is happening during training, how to control it, and how to troubleshoot it. Its the kind of material that gives a software developer like myself confidence to know I can read a paper and know where/how to implement what I’m reading.
Btw, with only four more lessons remaining, I have no idea how you are going to finish all this foundational material, discuss particular modeling tasks (e.g., seq2seq, object detection, etc…), all while reserving the last two lessons for Swift. I almost feel like this stuff were going through deserves its own “Part”.
Btw, btw … let me know when your in San Diego next time 
5 Likes
We’re not. So I’m trying to figure out what to do about that now…
August
1 Like
Part 3 v3: swift
3 Likes
yes lesson 9/10 was awesome. i have watch all lessons 2017/2018 and part 1 2019 and now 2019. Lesson 9/10 were by far the best. So liberating/empowering to get under the skin of fastai/pytorch.
I have been going over callback and refactoring to make the design patterns stand out more clearly as using the publish/subscribe and model/view patterns here: https://github.com/kasparlund/fastai_core/blob/master/source/nbs/09b_learner.ipynb
While doing this i found that it will be difficult to communicate the use of the property _order and that we can avoid this by using a message pattern of being_xxx and after_xxx. Maybe this pattern could be adapted @jeremy
Callbacks that act on data such af calling model(xb), learn.loss_func(e.learn.preds, e.learn.yb) should be located under begin_xxx. More passive callback such as recorder would typically subscribe to after_xxx messages. Here are the messages:
class Stages(Enum):
begin_fit = auto()
after_fit = auto()
begin_epoch = auto()
after_epoch = auto()
begin_batch = auto()
after_batch = auto()
begin_prediction = auto()
after_prediction = auto()
begin_loss = auto()
after_loss = auto()
begin_backwards = auto()
after_backwards = auto()
begin_step = auto()
after_step = auto()
begin_train = auto()
after_train = auto()
begin_validate = auto()
after_validate = auto()I see the publish/subscribe. Where is model/view there?
Are you seeing any benefits to publish/subscribe? One issue with them is having to include the event param in every signature.
I don’t think that’s enough. Order needs to be more fine-grained - e.g. when considering MixedPrecisionCallback and GANCallback.
publish/subscribe
I think there are or could be a couple of advantages:
- easy to understand, because its a standard pattern.People can read about the pattern elsewhere fx the Gof book: https://en.wikipedia.org/wiki/Design_Patterns" . The current course version is also a publish/subscribe pattern but its just less visible
- there are publish-subscribe libraries out there that supports asynchronous and remote communication. This could become usefull in a larger setup
- easy to support custom update frequencies. It can be handle in the messenger class. Could be usefull for heavy monitoring (the hooks callbacks you showed)
There i nothing above that could not be done in the current course version. it will just be easier by centralizing the messaging part.
The model/view. I hesitated .
- The Learner / Callback* s would be the model/view in a model/view pattern It would an easier to make the claim if one of the callback was a gui view (like an online tensor board).
- I send the the learner in the event, because if we used a distributed setup then one would probably use a proxy for the learn in order to be in control the traffic/ serialisation when calling learner.
Anyway its interesting to stress a design by extrapolating to different scenario.
I was brushing up on functional programming, therefore, whenever i see for loops I’m trying to rewrite them using the aforesaid paradigm and I tried using code @sgugger wrote in the notebook 02b_initializing.ipynb and notice I could rewrite this line like this
for i in range(100): x = a @ x #original
element_wise_mult = map(a @ x, range(100)) #myversion
The problem with the second one is that the output will be a generator and to get your results i use list(). I’m getting a couple of errors as you see here:
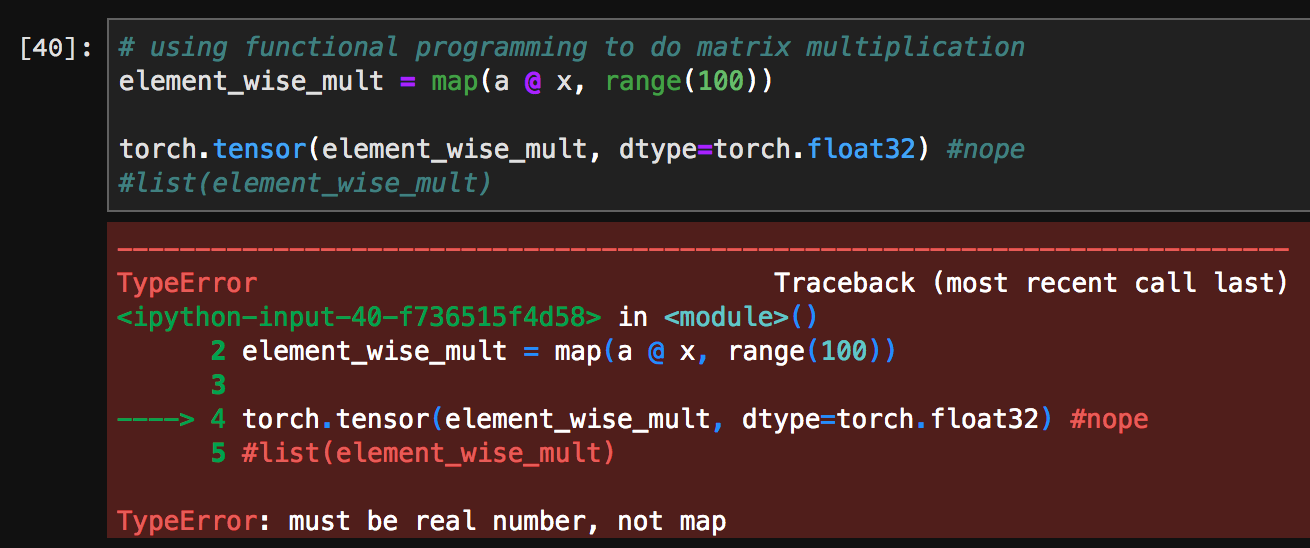
and
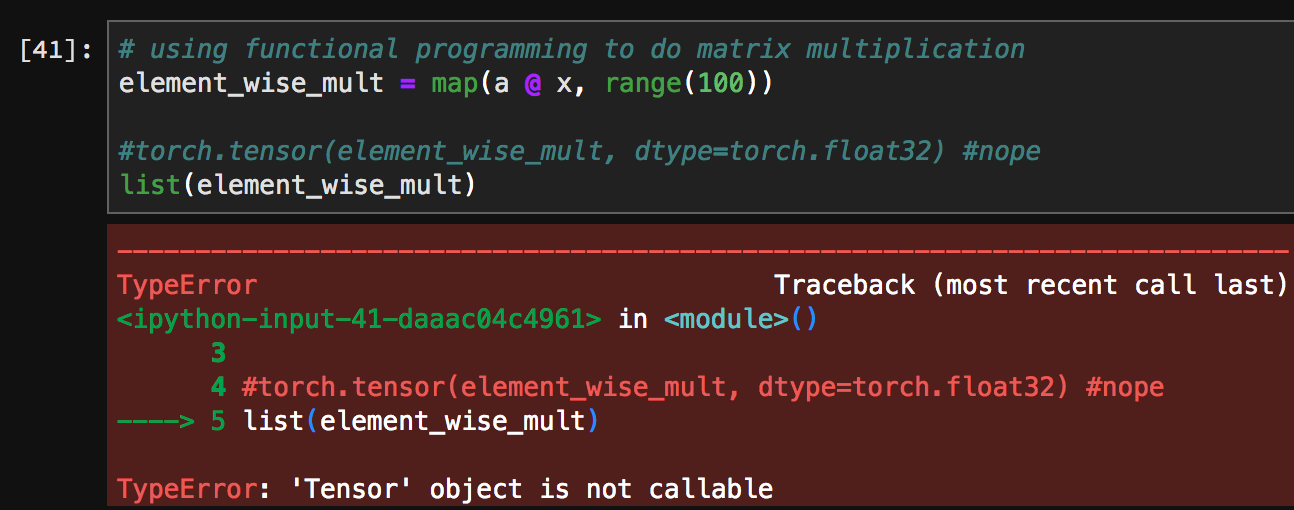
Currently looking into the TypeError. Would anyone know what’s going on here?
correction: Matrix dot-product instead matrix multiplication
Part 2B?
2 Likes
One issue is that the first argument to map is meant to be a function, whereas you currently have an expression (a @ x). I think the way to achieve what you want to do would be to use reduce because you’re accumulating the result on x: reduce(lambda x, _: a @ x, range(100), x)
1 Like