Please, remember, the first post of each lesson thread is always a Wiki, so if you see people asking resource questions please kindly consider editing the first post and add a link to the resource. Thank you.
The activation function needs both positive and negative values for y to shift the mean . Both options are given here. It is also the reason why ReLU is not a candidate for a self-normalizing activation function since it can not output negative values.
The gradients can be used to adjust the variance . The activation function needs a region with a gradient larger than one to increase it. … A gradient very close to zero can be used to decrease the variance
The reason I mention it is that we haven’t quite discussed how to fix the mean with ReLU (only positive values) and it appears SELU doesn’t have this issue.
Are we sticking to ReLU because it still proven to be superior to SeLU or is it more difficult to teach with?
My take on it is that while the ReLU output (say x) will have positive mean, when the next layer symmetric weights around 0 (so same probability (density) for +w and -w) the activations x*w (or some sum of them) will be zero mean again. As such, having a mean of 0 isn’t paramount as long as it isn’t so large that the variance of x*w explodes (because the variance of the next layer will have a term mean(x)**2 * var(w)).
So as long as you control the mean, having it zero might not be an end in itself.
I did not understand what the order of callbacks actually does and how it works. What do we actually order, the classes that inherit from the callback class or the methods?
And why we did not specify an order in “AvgStatsCallback”, I understand that it automatically gets a 0 (from the parent). What am I misunderstanding?
I briefly discussed the problems with stuff like SELU and Fixup in lesson 2 - they are extremely sensitive to tiny changes in architecture. I’ll be discussing this a bit more in the next lesson.
Stas, I have been following the guide, but the guide does not seem to apply only to fastai, course-v3, and fastprogress repos. I am trying to create a pull request aganst fasta_docs. Does it matter?
Since this week is talking about building the training loop from scratch and last week was talking about speed, I wanted to mention an observation I had about the DataLoader and some ways to speed it up.
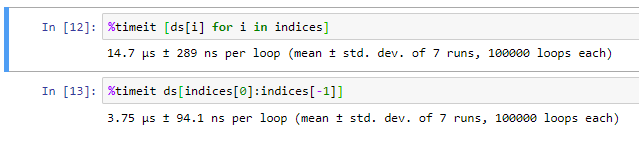
I was motivated by a very large data set some time back to dig deeply into the detail of the Pytorch Dataloader and Dataset. For very big data sets (millions or samples) small timing differences can really speed up your training loop. I believe the difference comes from how you index into the array. Since both RandomSampler and SequentialSampler return a list of indices you end up with something that looks like this when you generate a batch:
batch = self.collate_fn([self.dataset[i] for i in indices])
But this method of indexing is very slow compared to using the : notation from numpy.
If you couple this with adding a single Randomization at the start of each epoch, you can have a huge speed improvement in just iterating through your dataset.
It’s exactly the same as all other fastai repos. I just didn’t put it in the guide since it wasn’t meant to be used by anybody but maintainers, until a week ago. I will tweak it now to include that repo as well. But the easiest is to use the helper tool - it does all the work for you.
update: docs updated, if you encounter any specific obstacles or something is unclear or confusing, hard to follow, please ask at Documentation improvements. Thank you.
@champs.jaideep For the first two, CSVLogger can be used which writes the metrics in a csv file to learner.path…Nd using the excellent fastai callbacks read the csv file and change behaviour of model/lrs accordingly(based on those metrics) at required step(batch/epoch begin/end etc)
Thanks for this advice. Right now, I am feeling overwhelmed by this course but then I remind myself that these courses are ‘ML for adults’. We are not constrained by the course imposing deadlines, tests or awards for completion. Everybody has other commitments but here we have the material, further reading and an active forum to resolve doubts. How much we progress each week is up to us. The important thing is to do just that; progress.
For the Lesson 9 assignment I summarized the All you need is a good init paper. I have written this Medium post summarizing the paper going through it section by section.
Must say that the paper is pretty clear and concise. The algorithm they provide is really straightforward too.
As always, if you see something that is not clear or wrong, just reach out.
I understand why you would want to normalize your input, for example making it to have mean of zero and std of 1. My question is: why specifically mean 0 and std 1? What would be the difference if I normalize to mean=1 std=1? or mean=1 std=2? Intuitively I can see an argument for std=1: if you think it like a “signal”, if std is less than 1, the signal would reduce until it disappears, and with std > 1 it would magnify and get out of control. But what about the mean? What difference would it make if it was 1, or 3 or 7? The shape of the distribution would be the same in this case, only centered around a different number.
I am planning to continue annotations as the course progresses. I will be creating pull requests a day or two after each lecture. Since pull process now works, I do not need to maintain separate PR for the notebooks. I only created my private repository because I could not create a pull request. But it would be nice if these requests would be available through the official course repository so people taking the course now could benefit from the annotations.