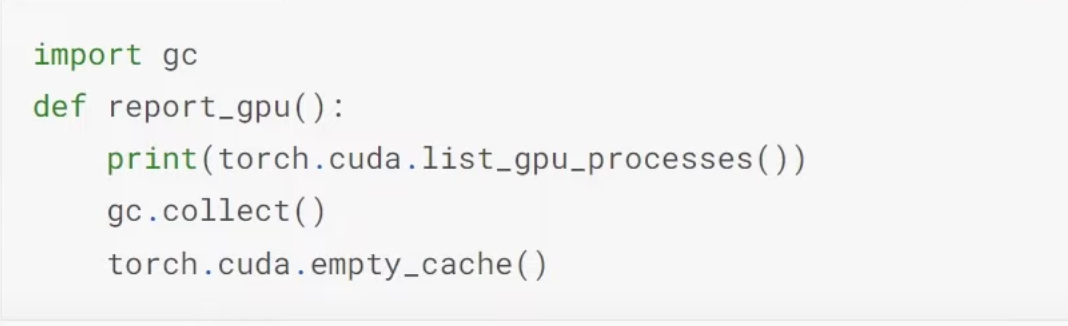
08:04 What if a model causes a crash problem of cuda out of memory? What is GradientAccumulation? What is integer divide? (
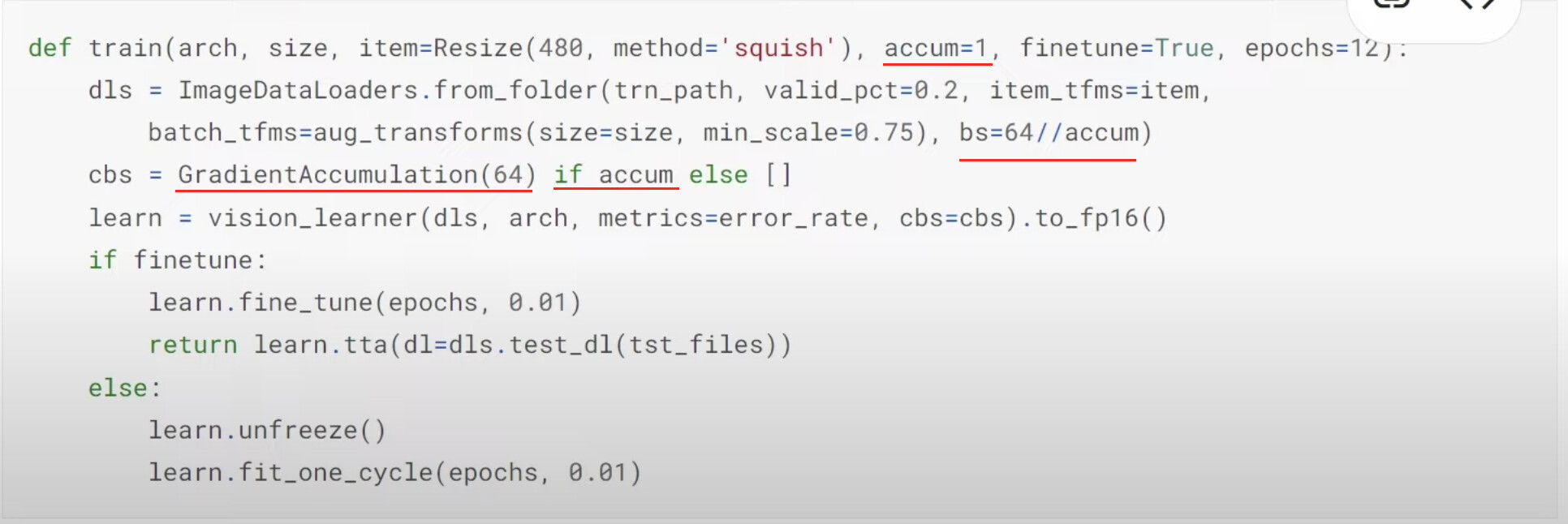


15:15 More questions: it should be
18:00 How did Jeremy use GradientAccumulation to find out how many



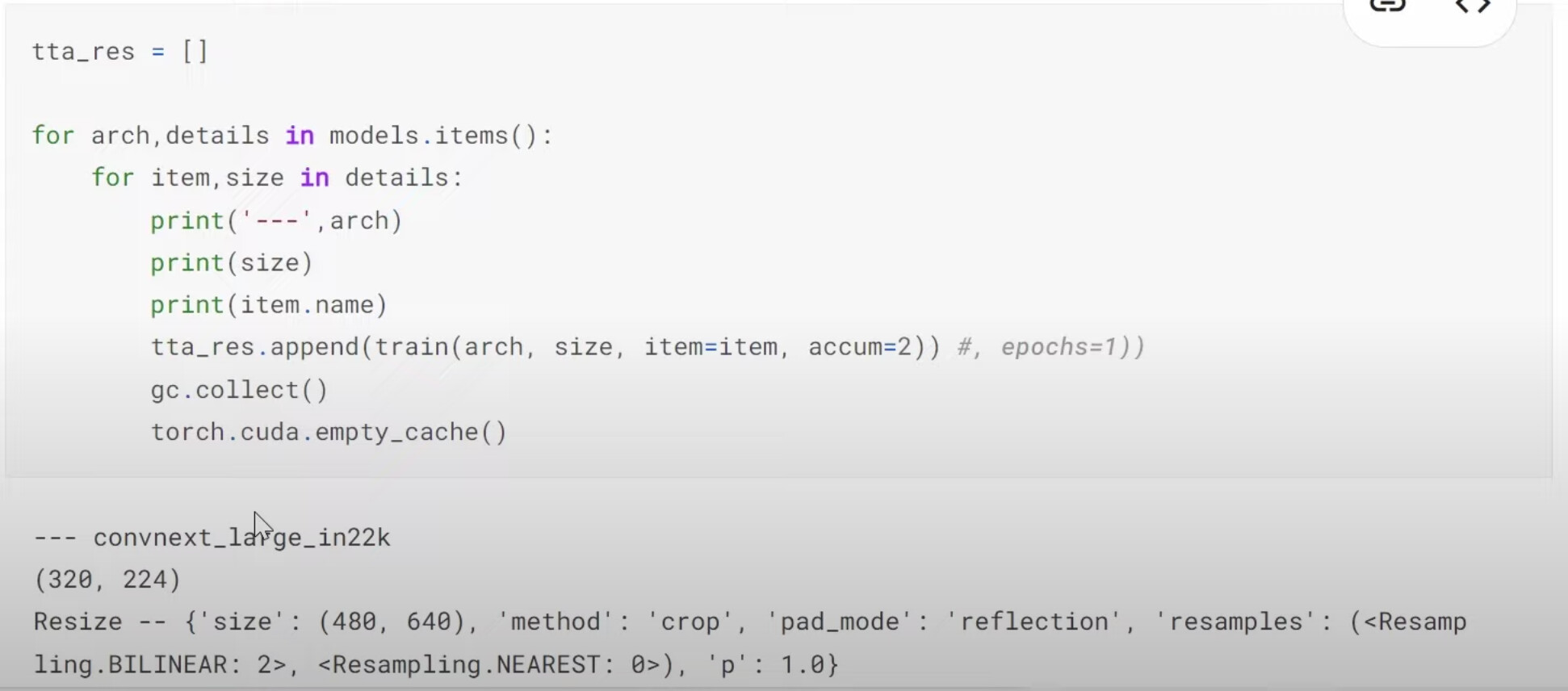
22:07 Why does Jeremy don’t use
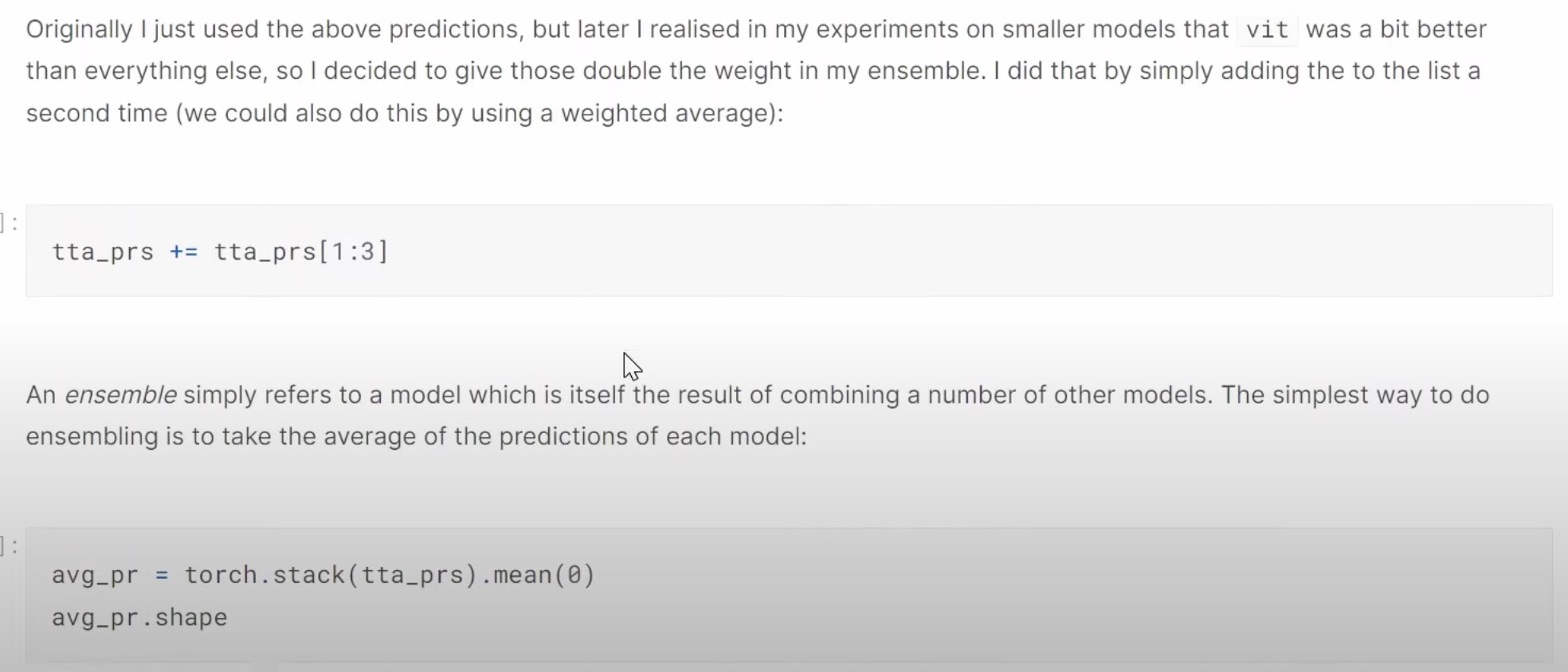
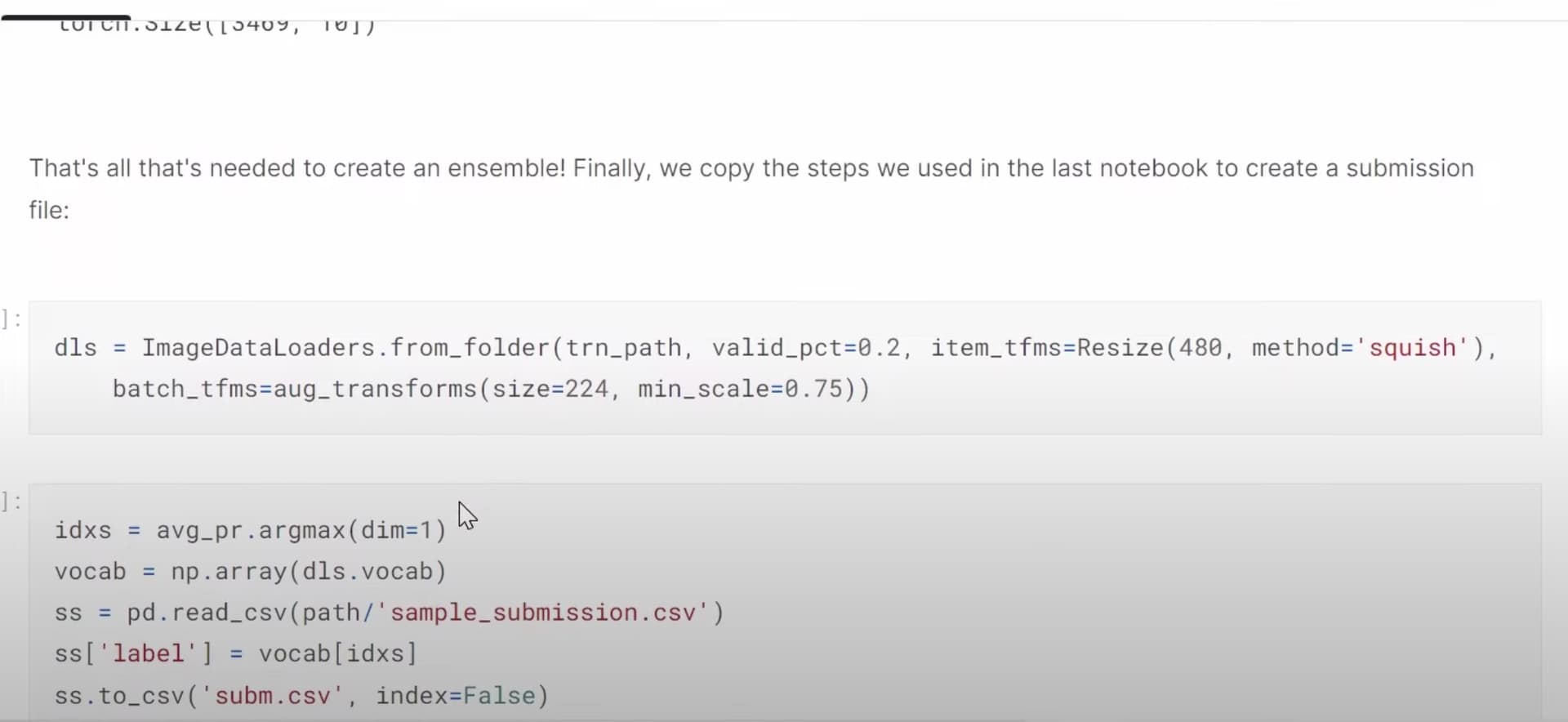
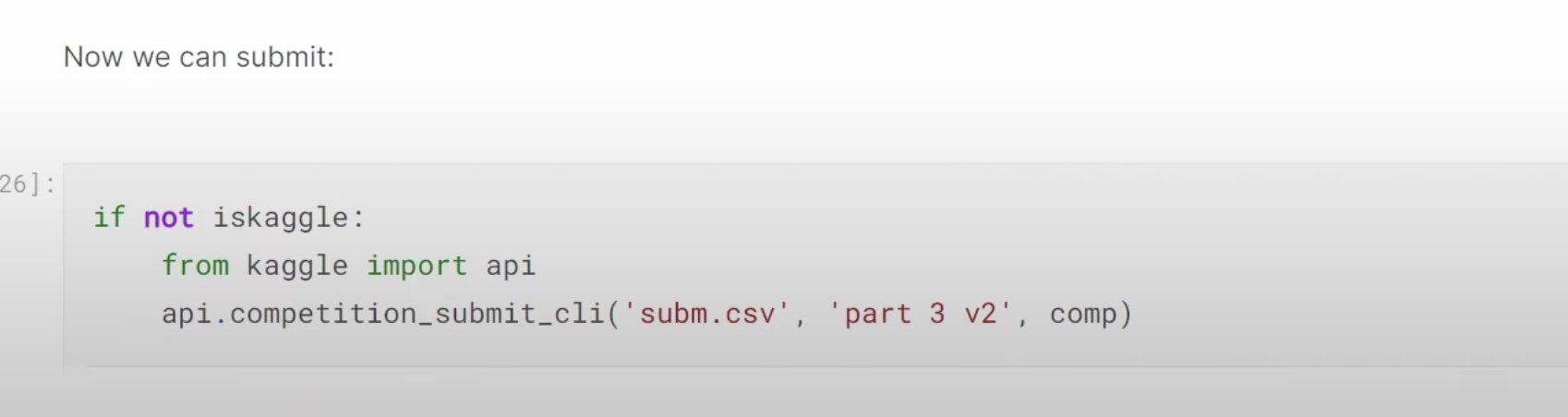
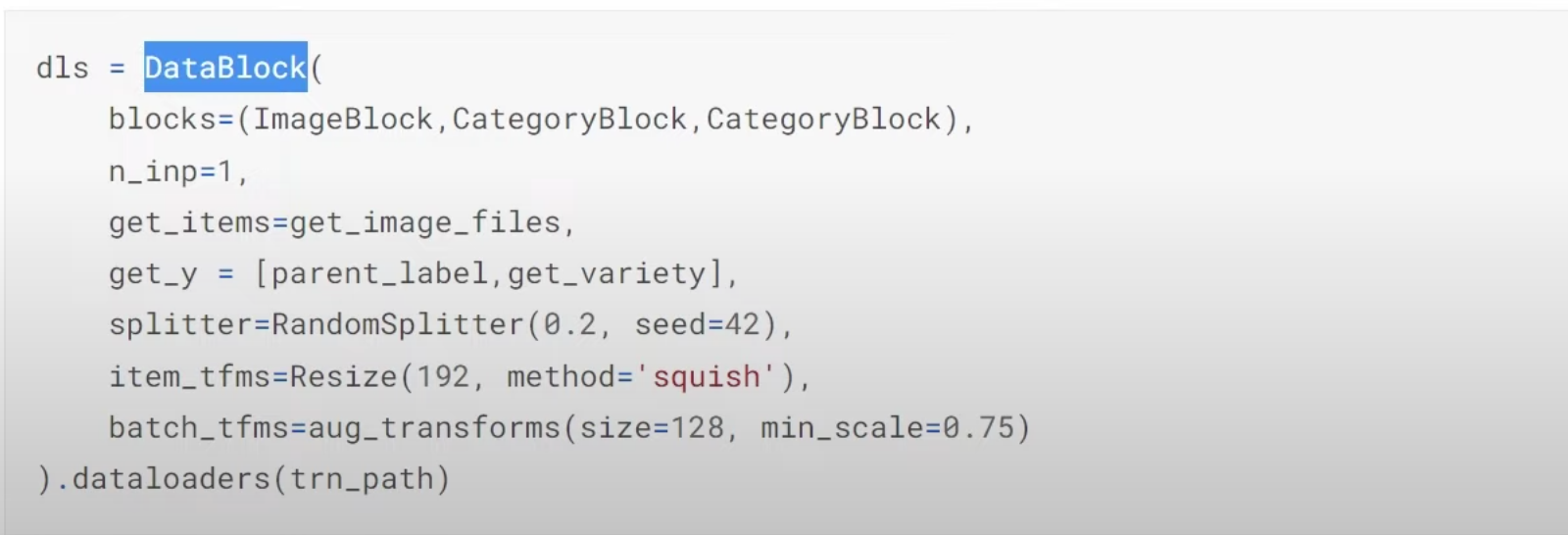
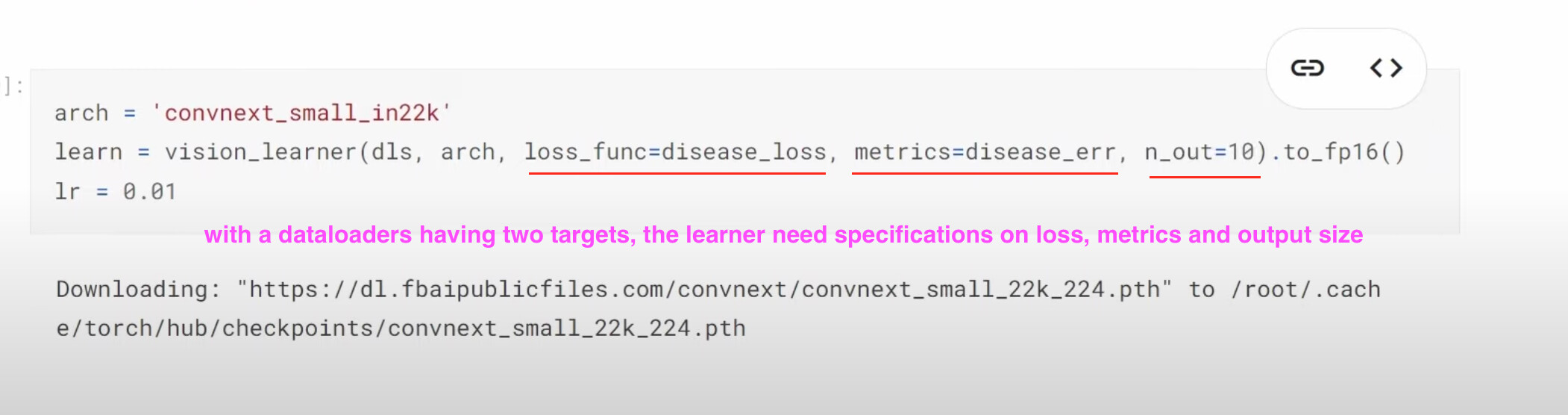
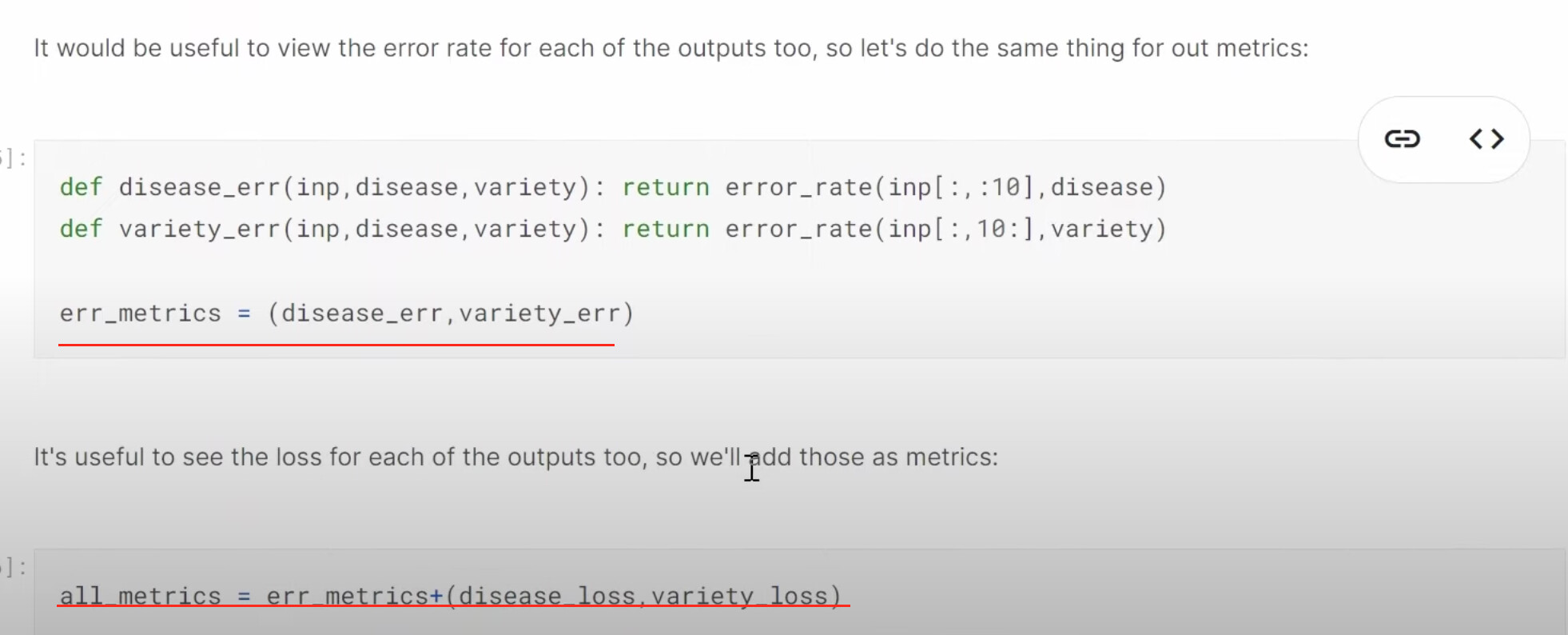
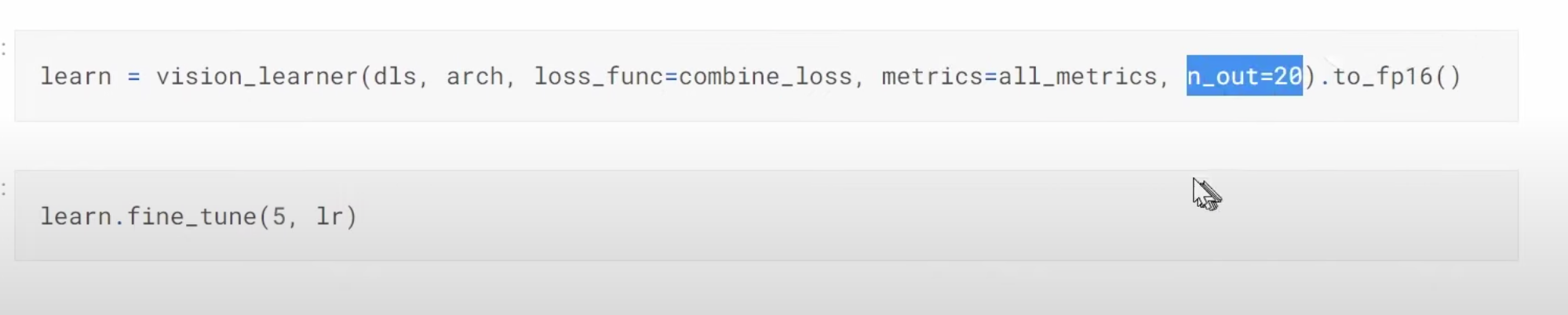
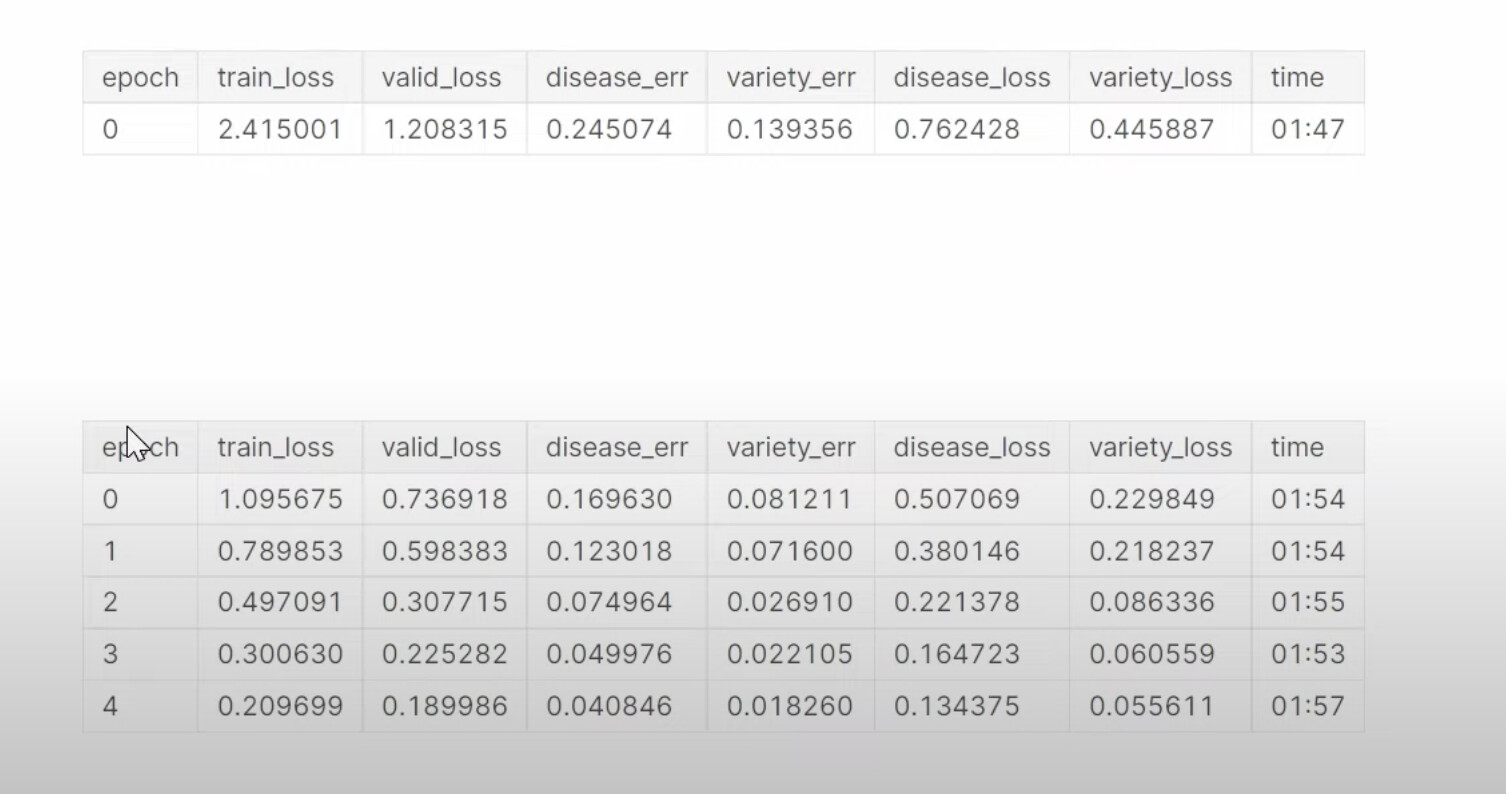
31:37 Multi-target model: How to build a dataloaders to have two labels, disease type and variety type? What does a dataloader look like in
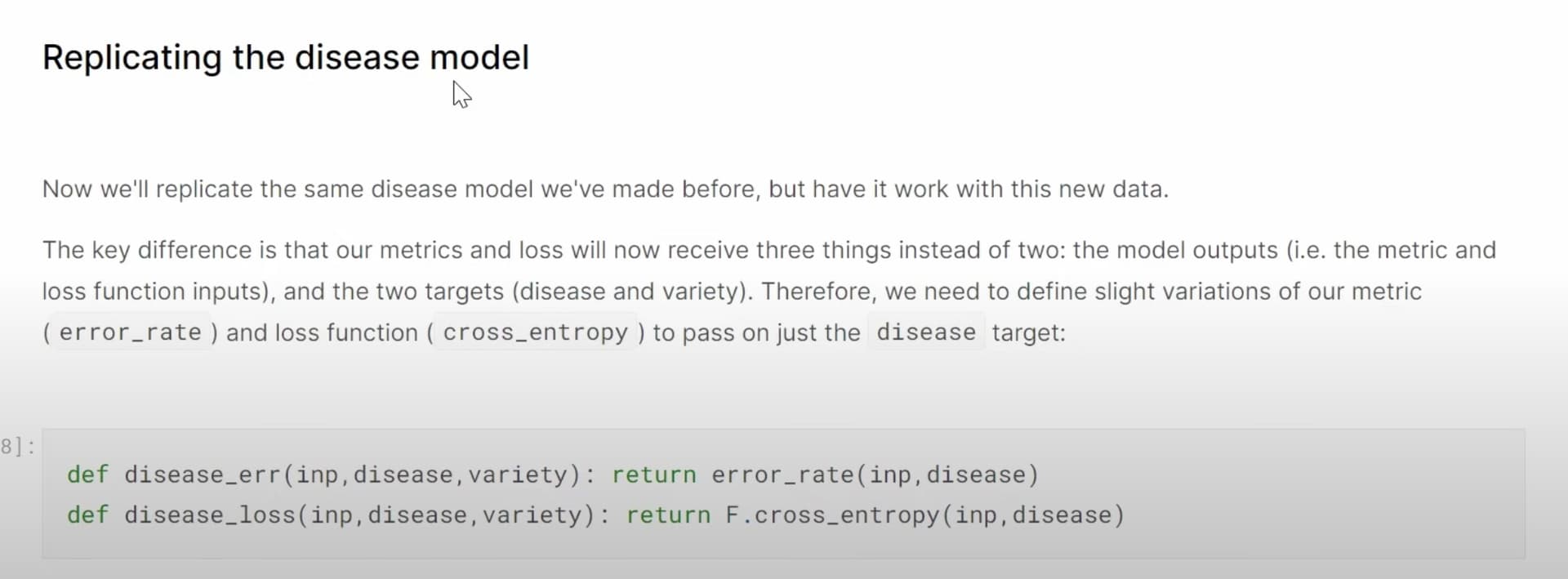
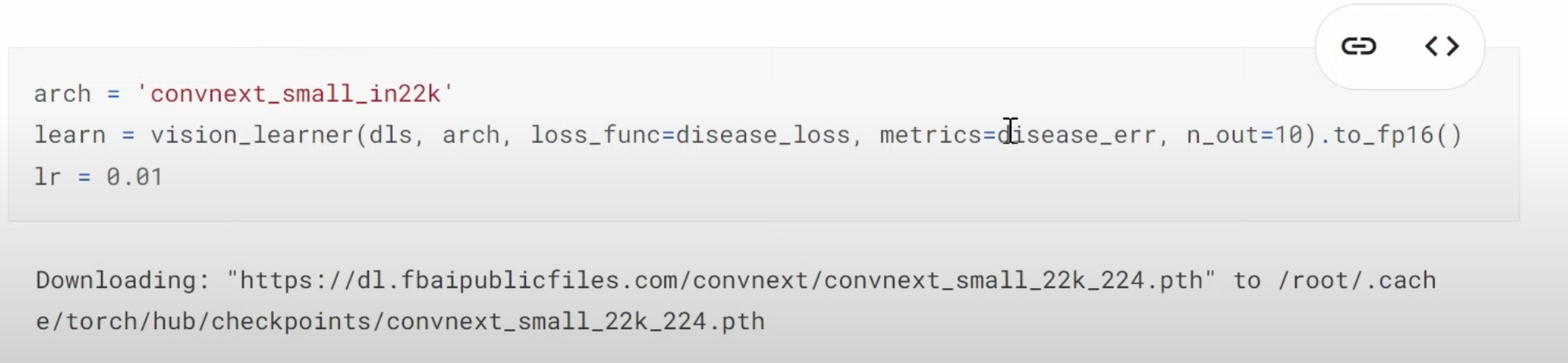
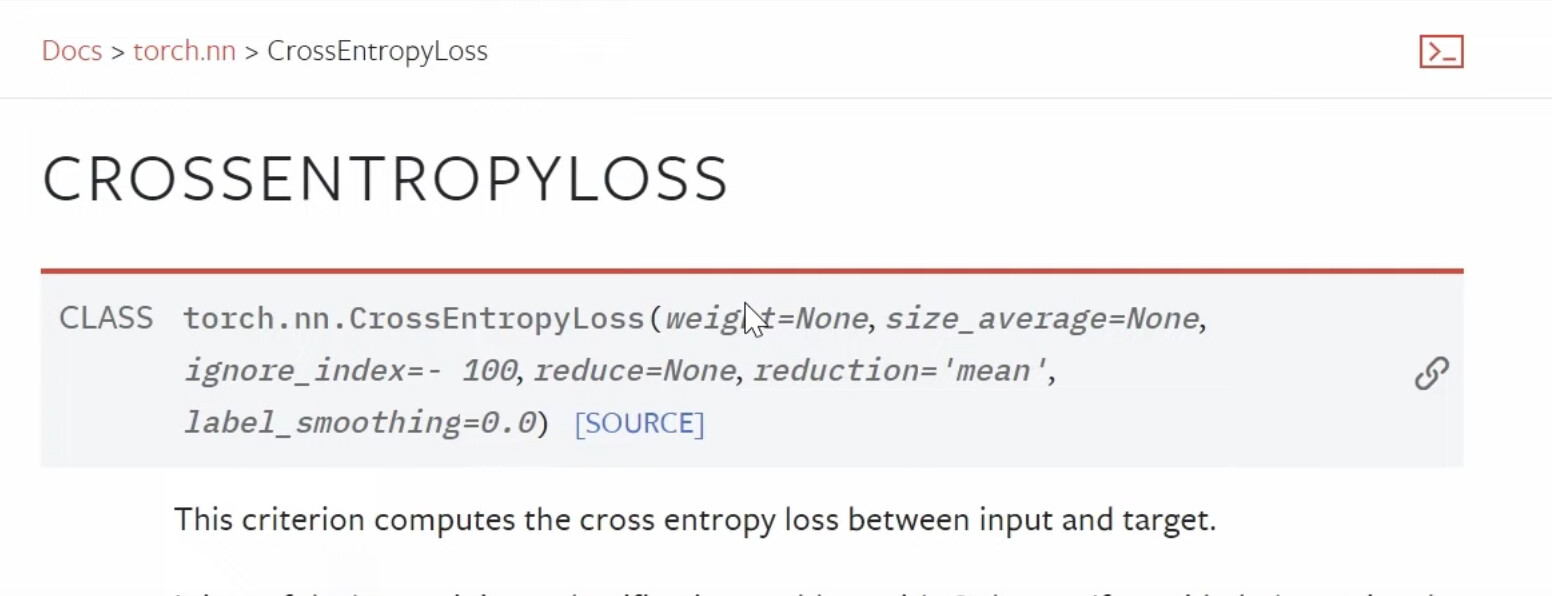
41:24 What does









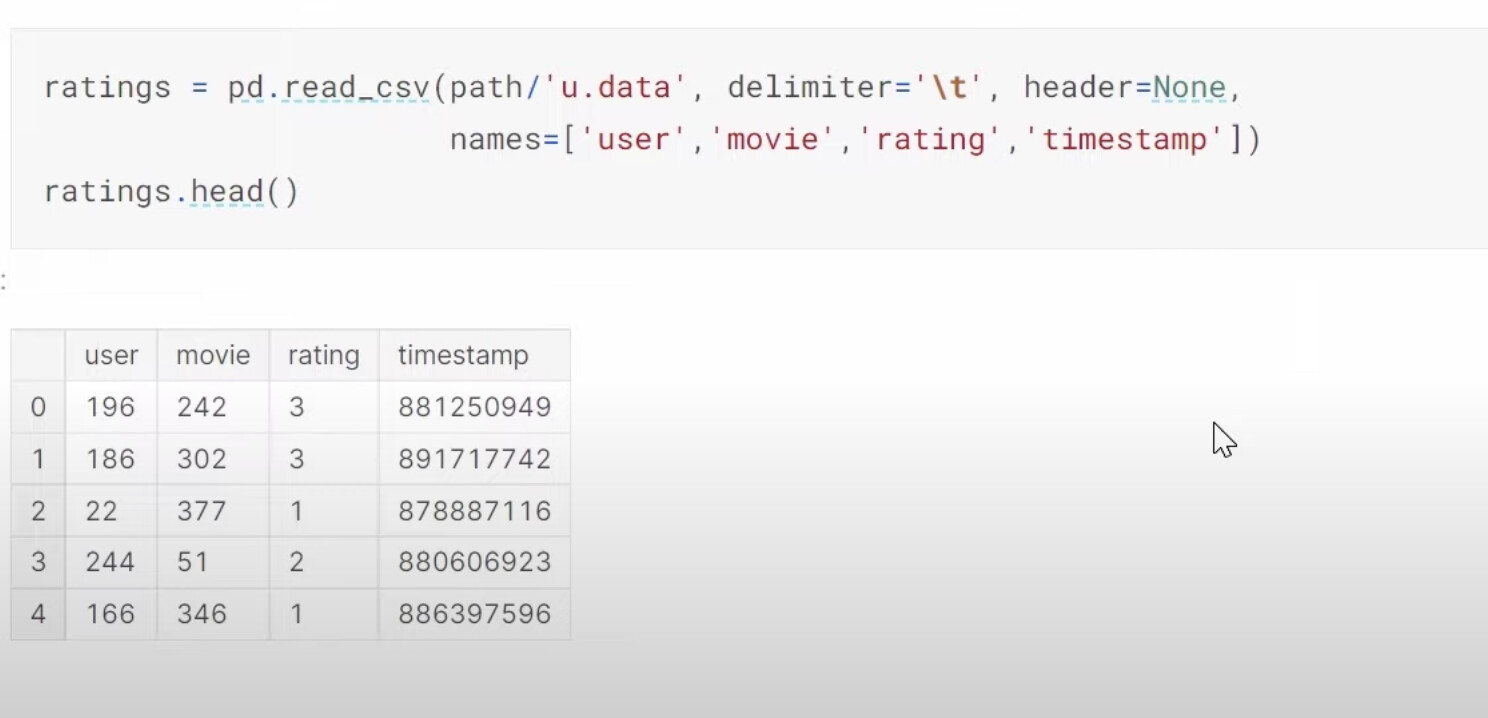
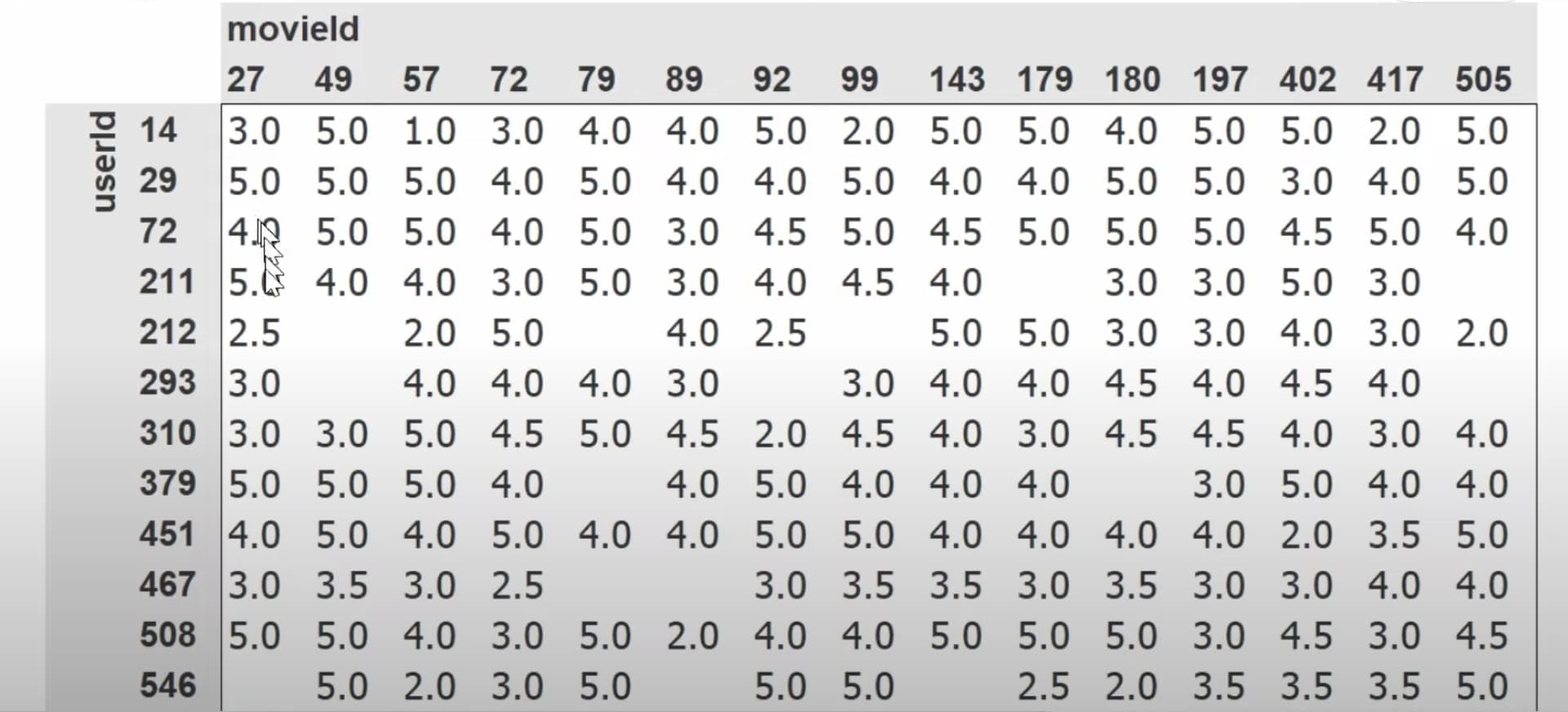

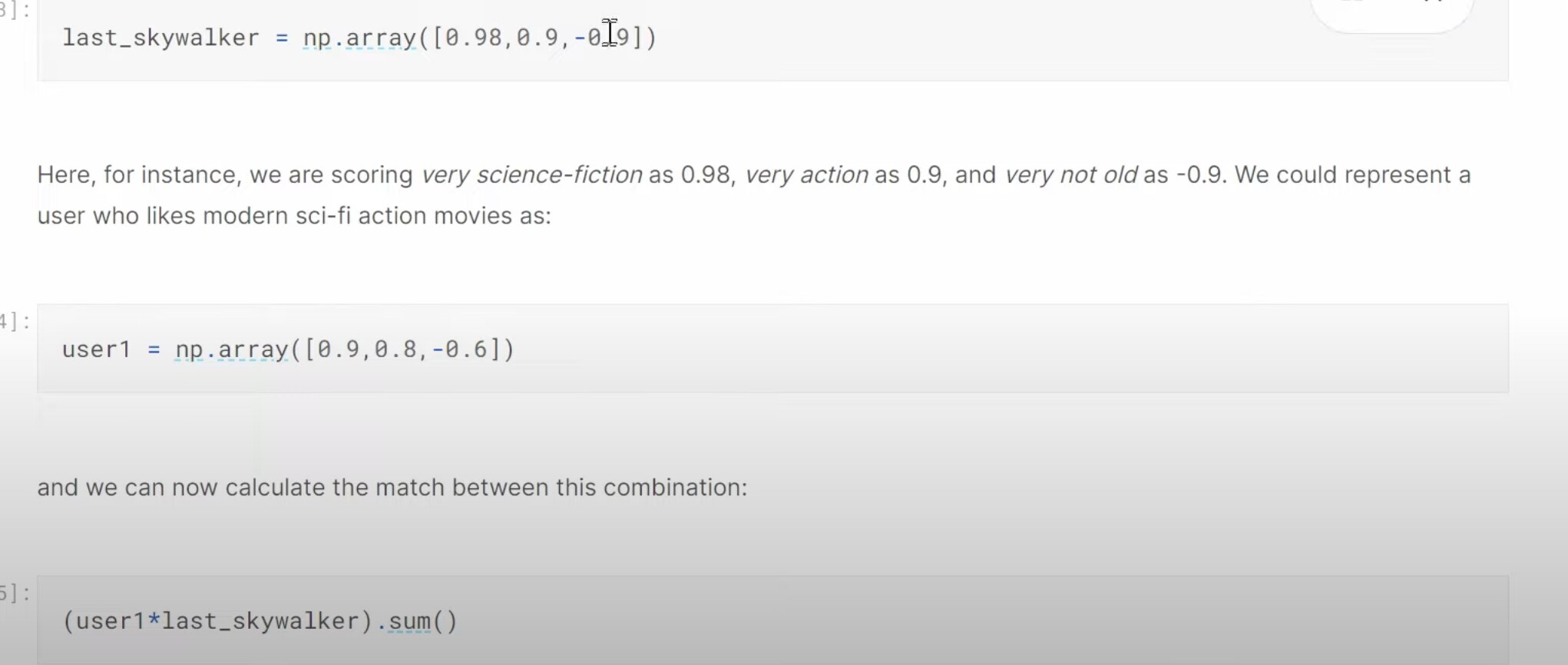


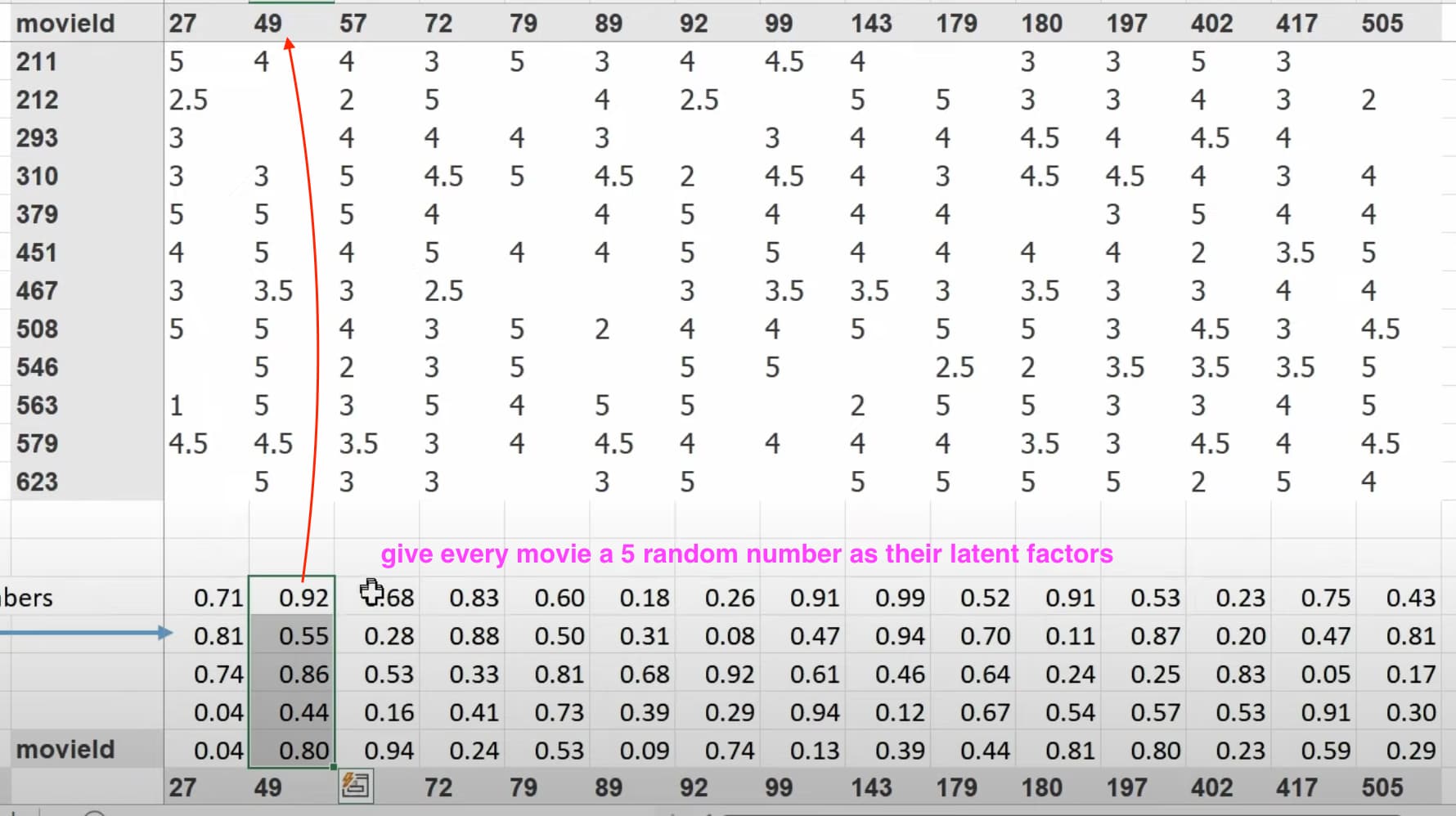
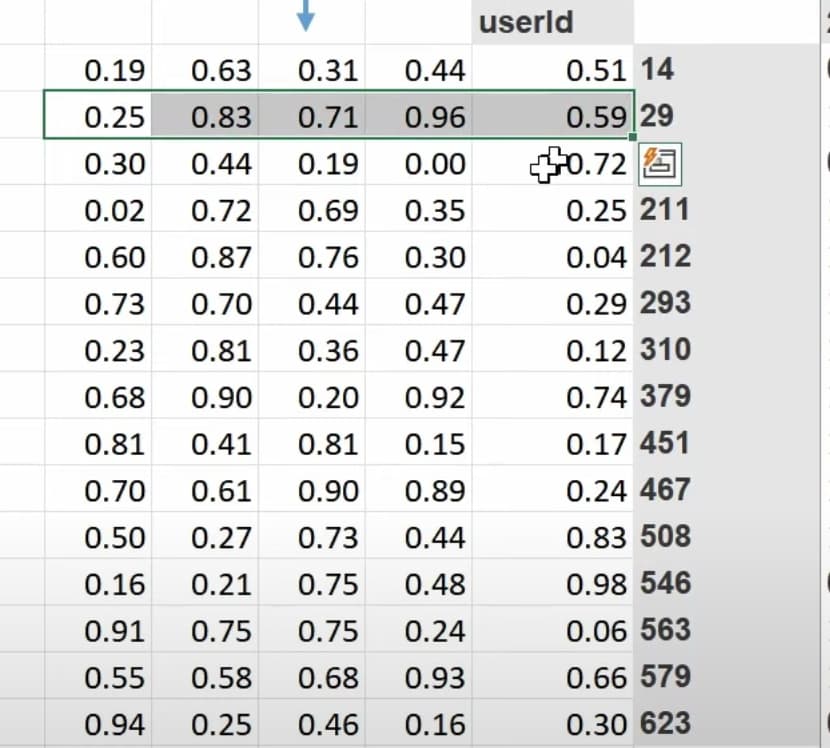

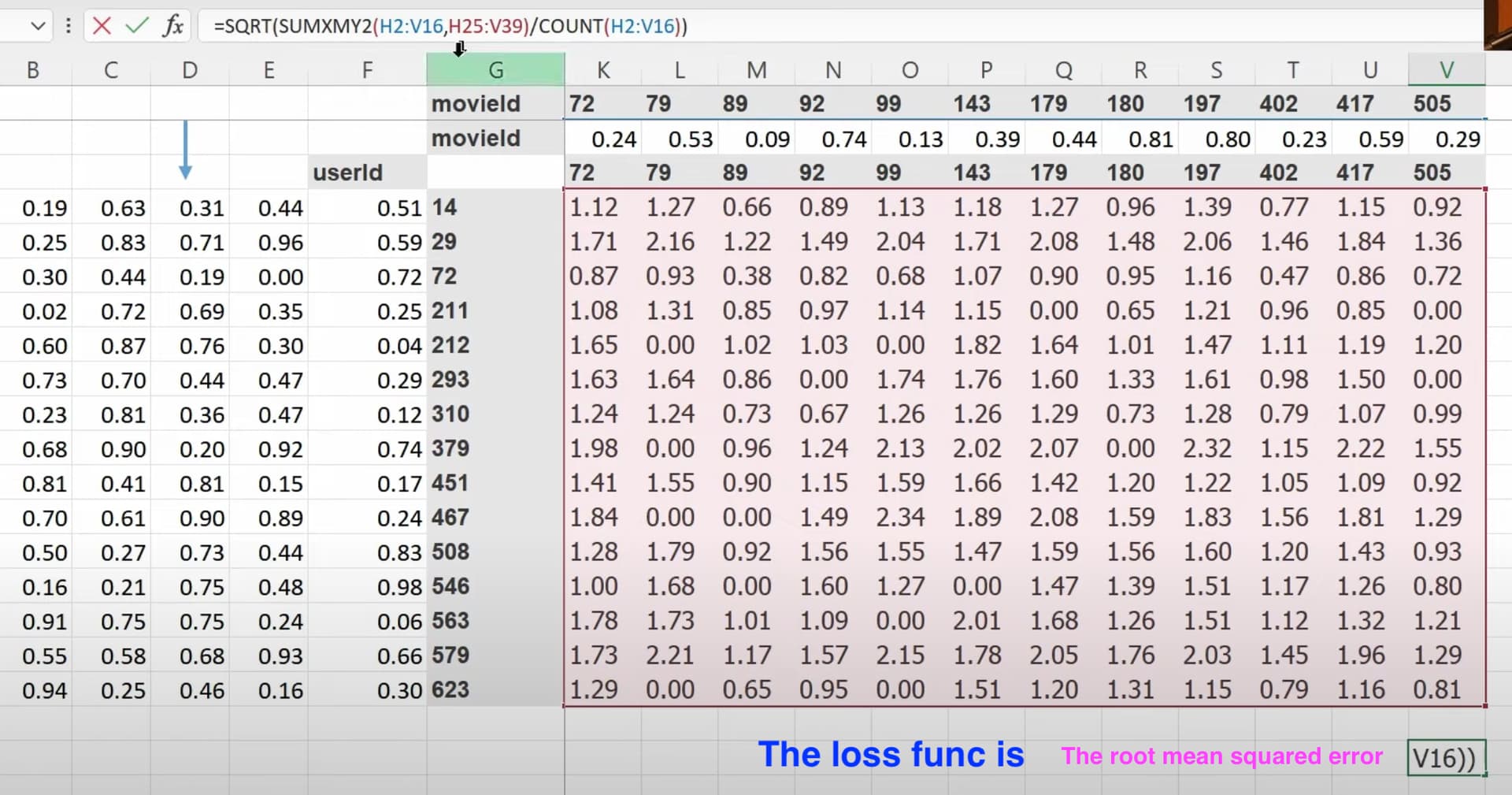
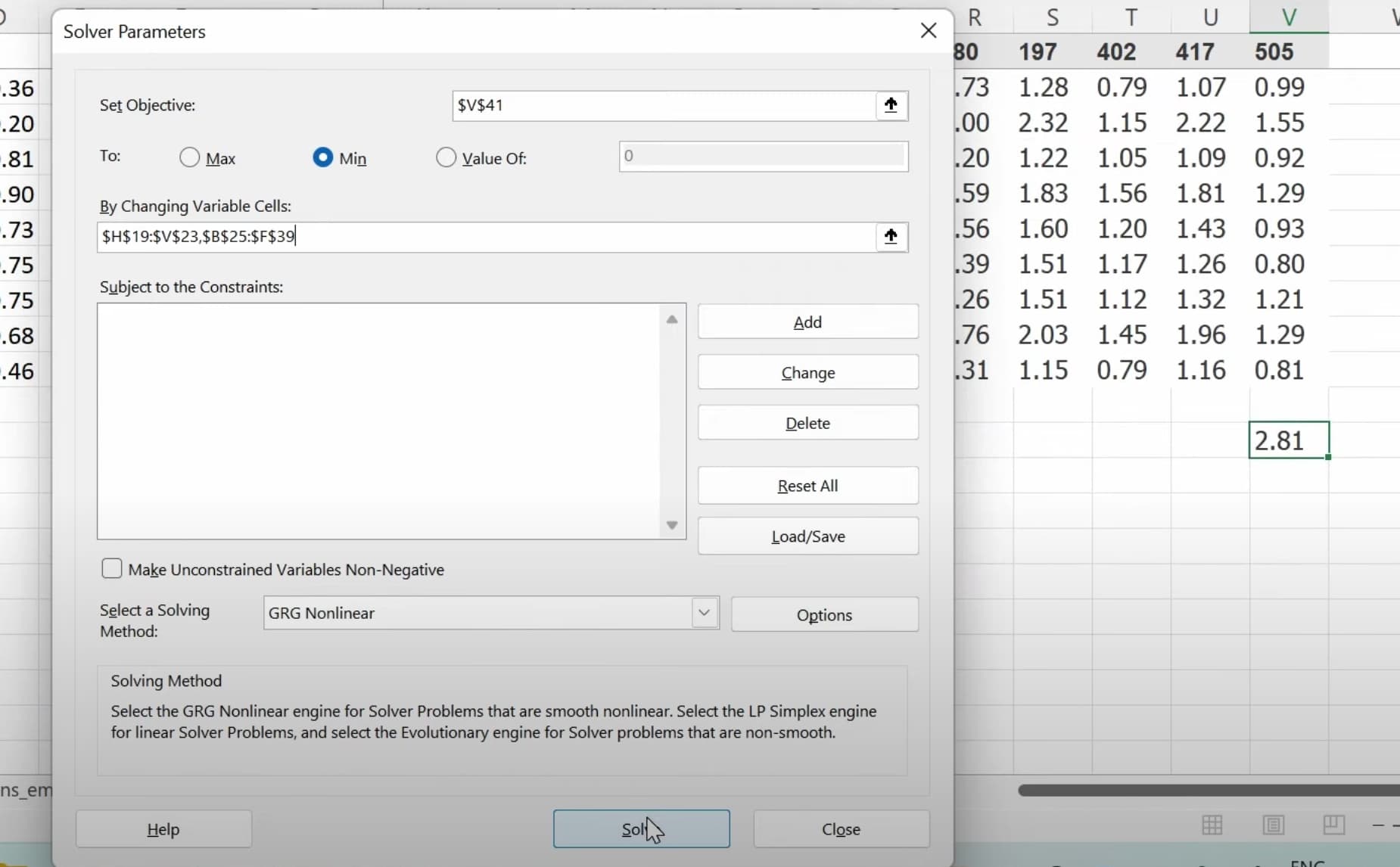


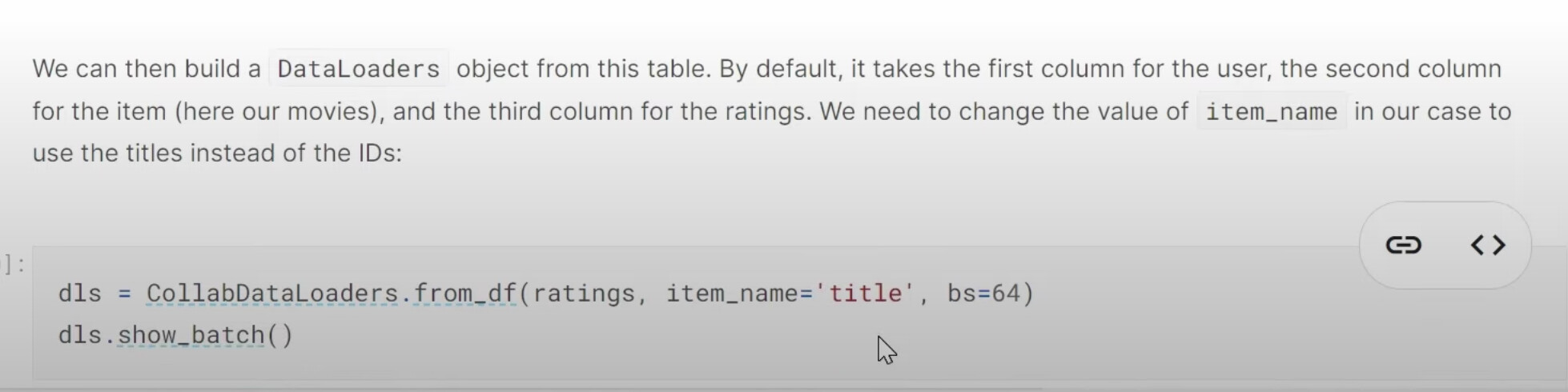
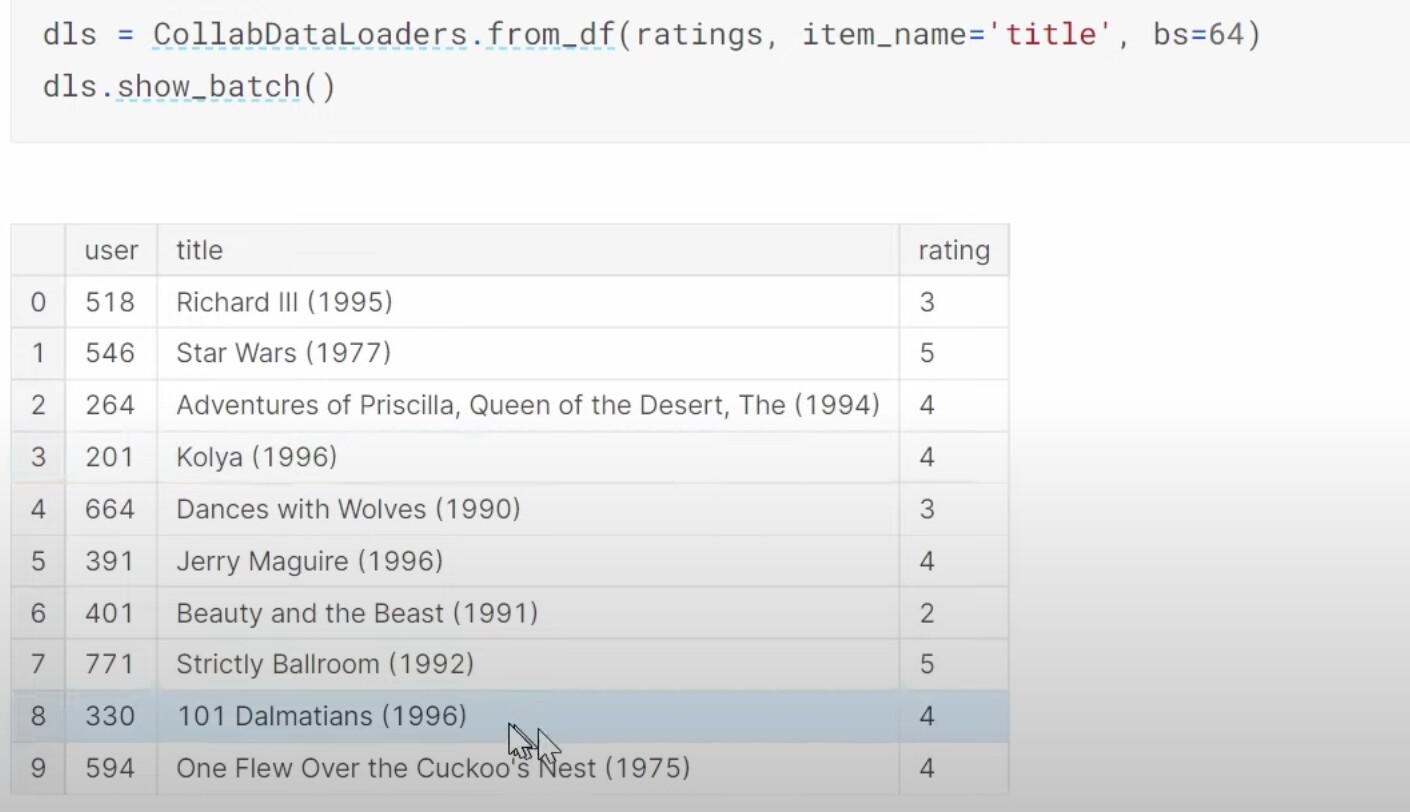
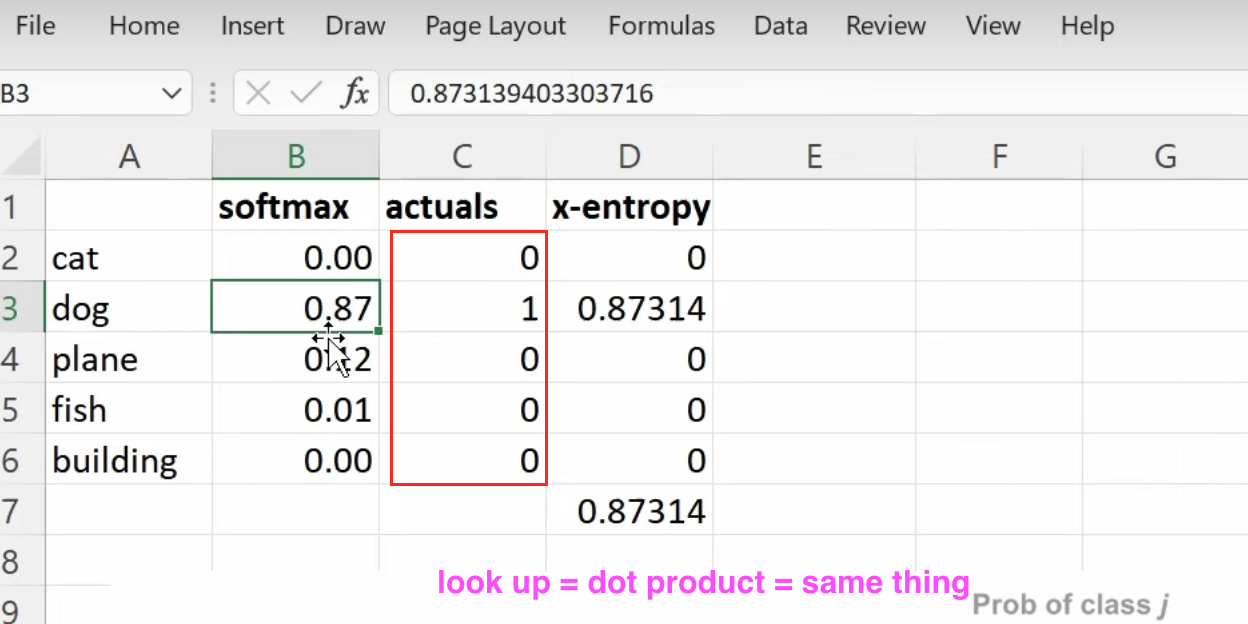
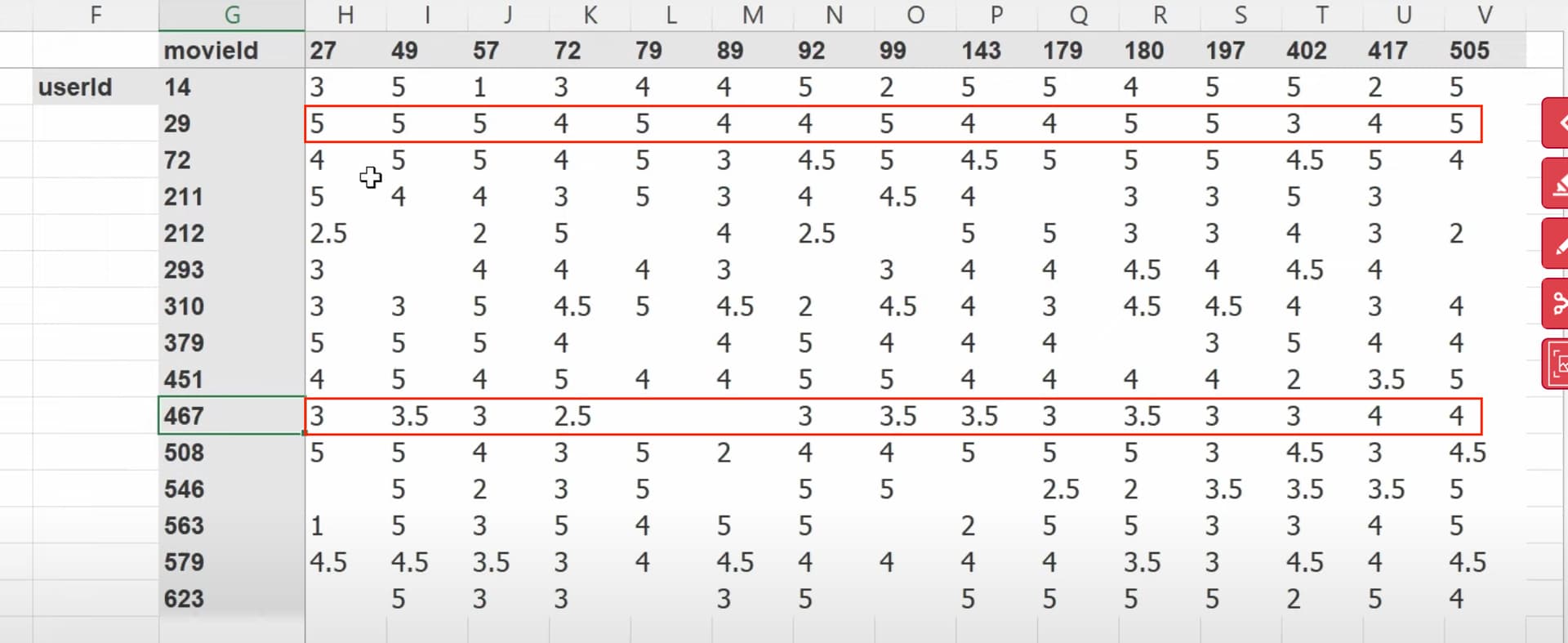
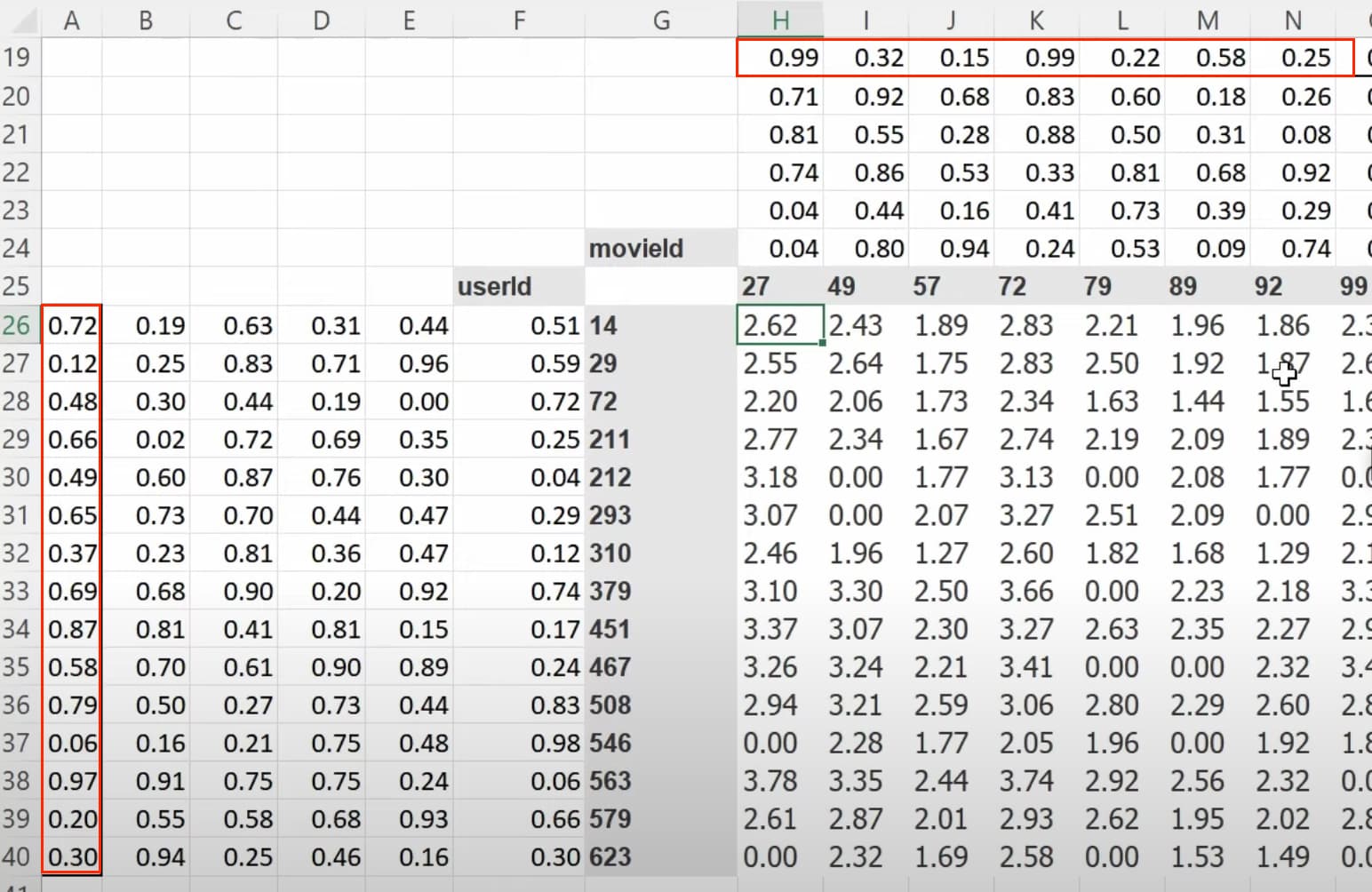
1:20:05 What does our dataset look like before building a dataloaders on it? How to create a dataloaders for collaborative filtering using


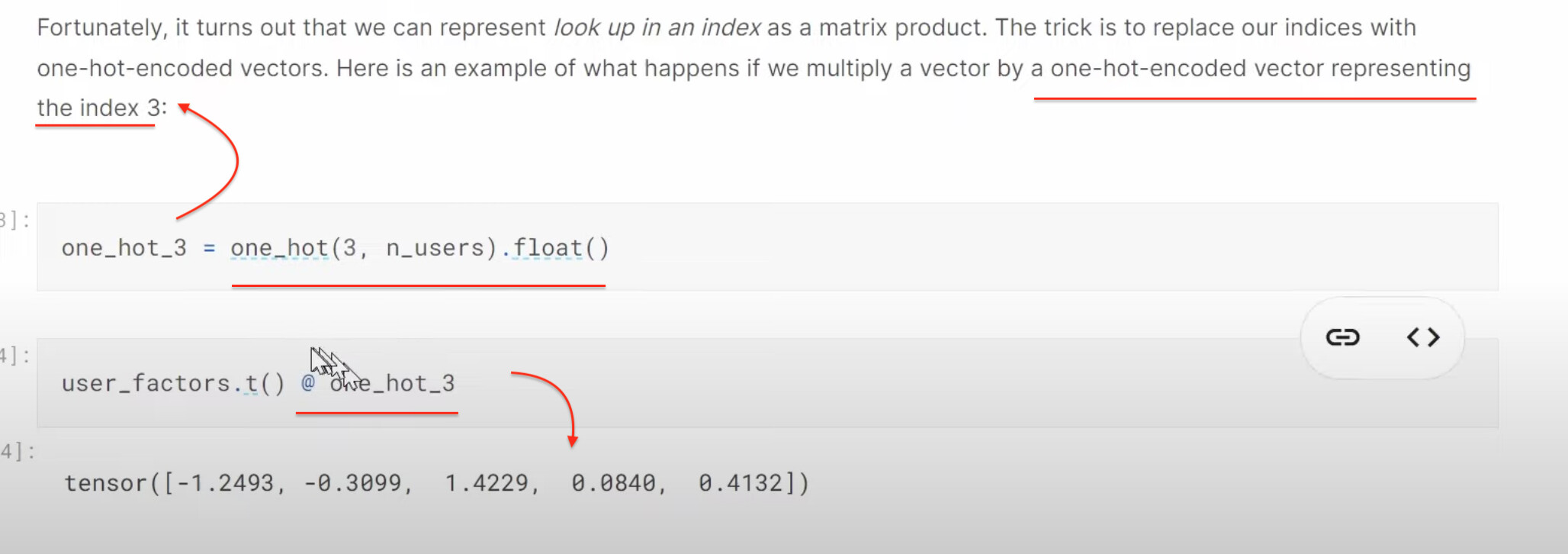
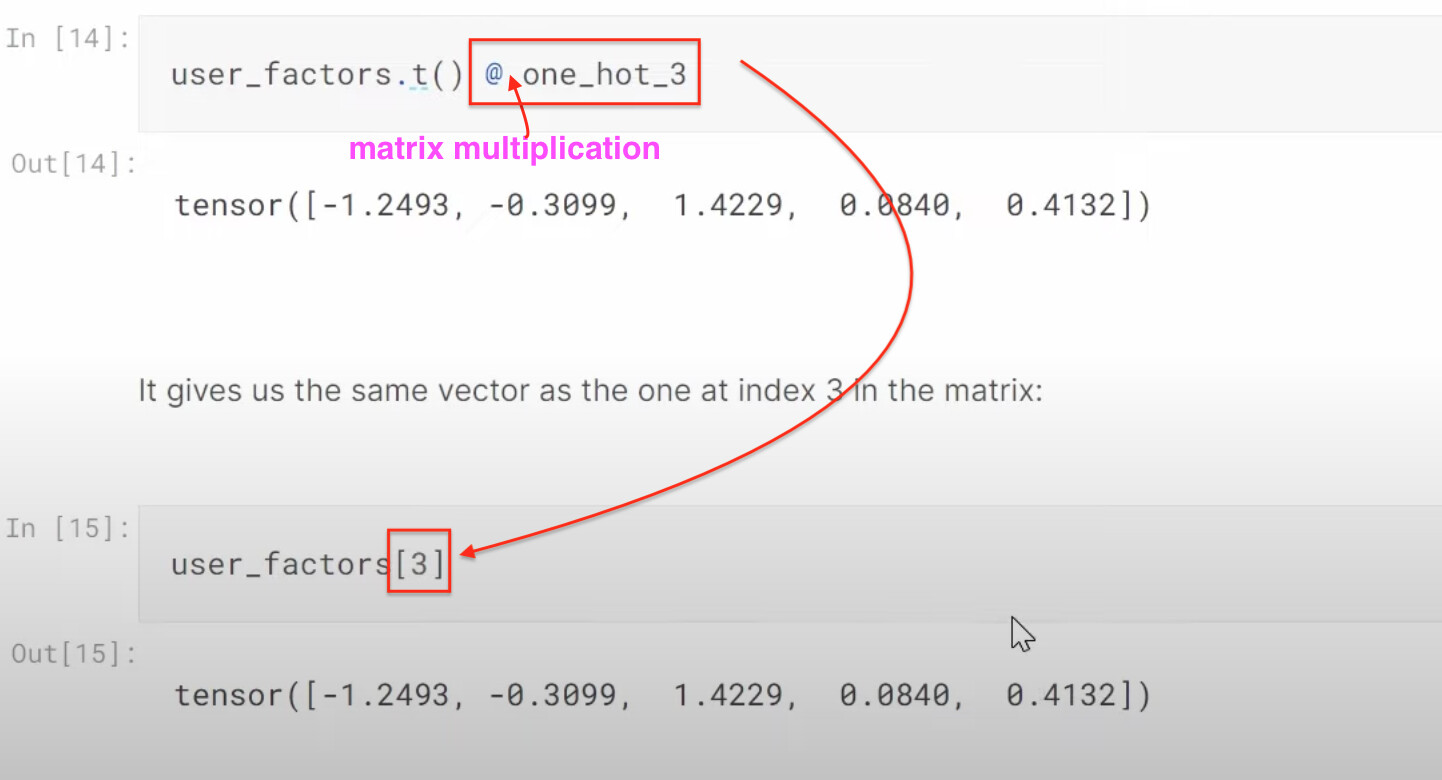
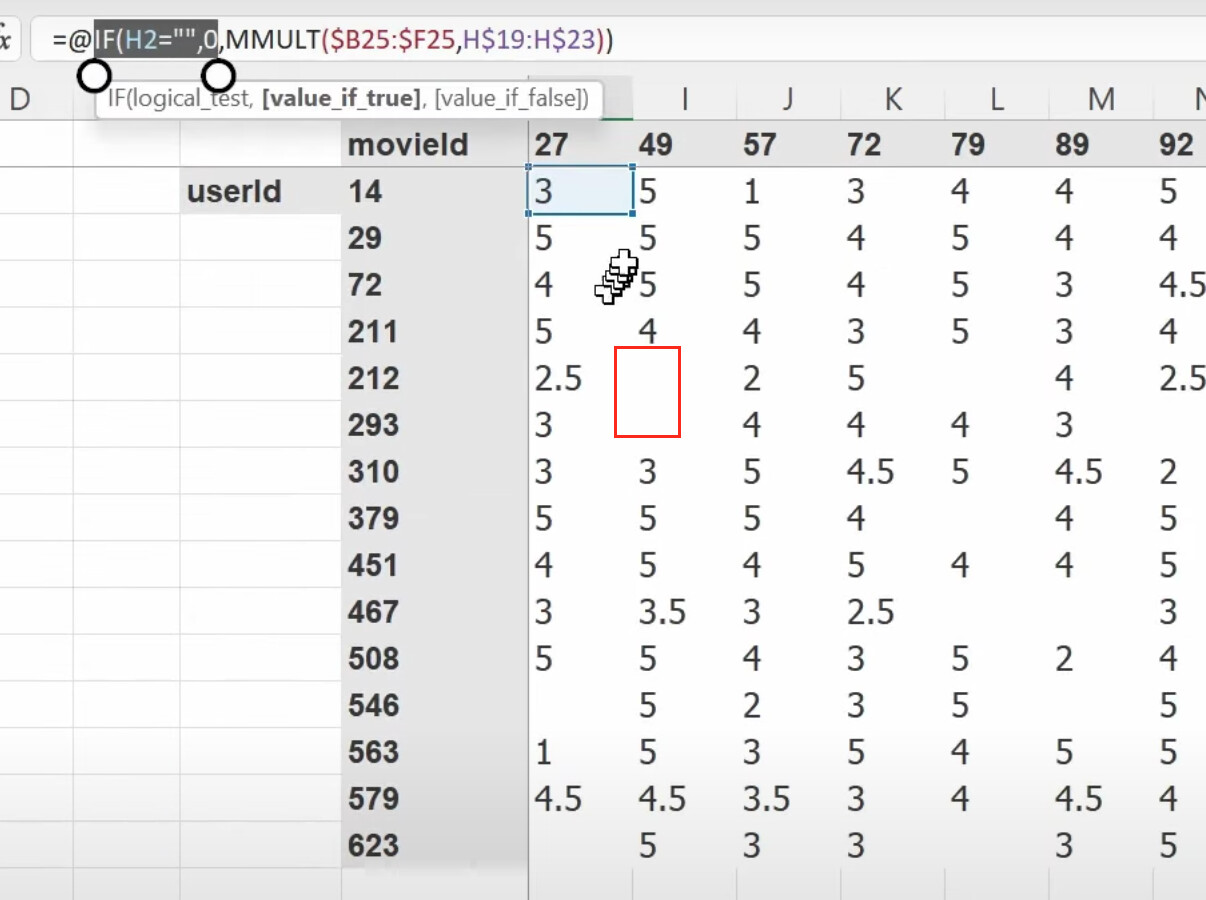
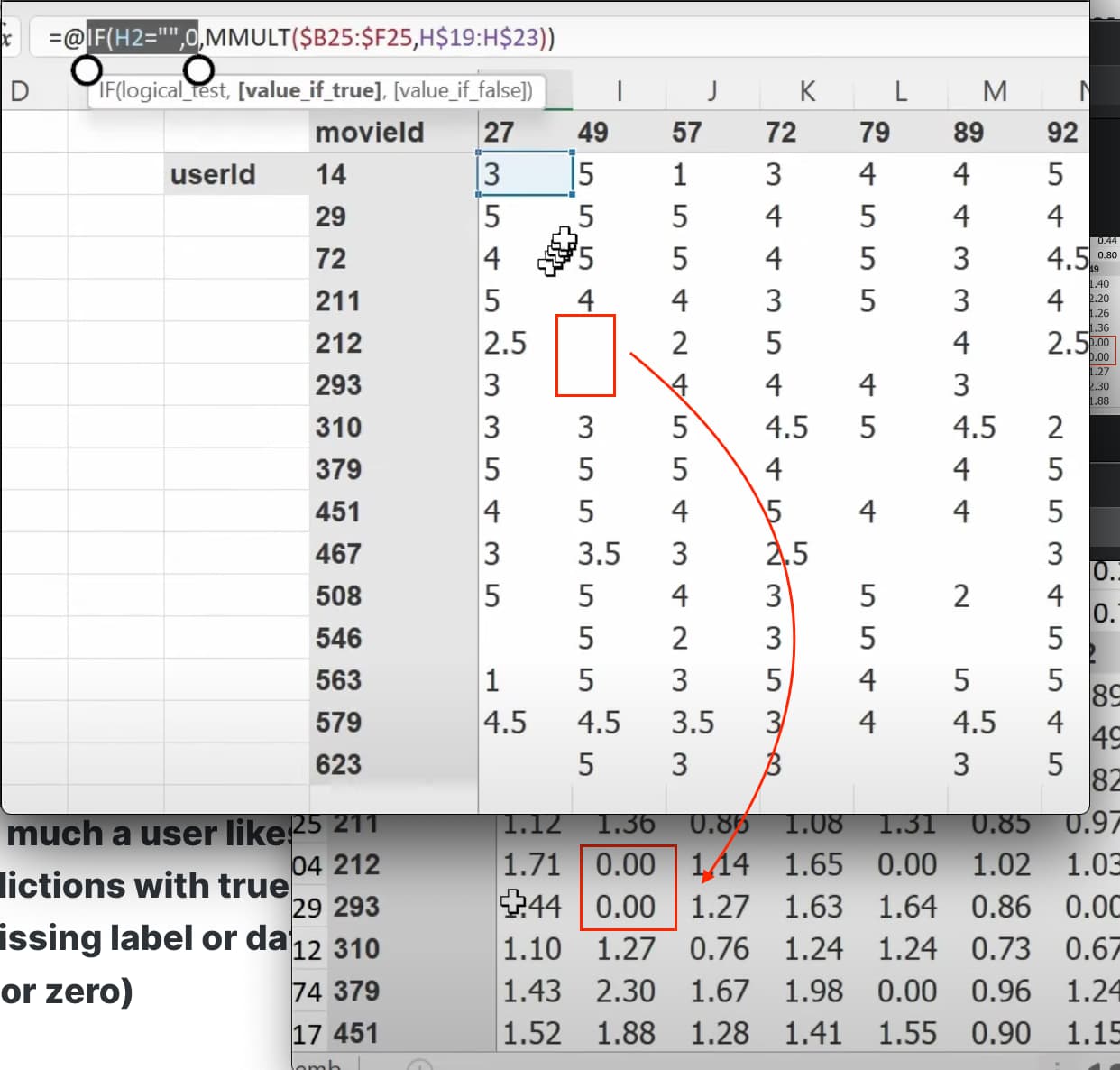
1:27:13 How to build a collaborative filtering model from scratch? How do we create a class? (as a model is a class). How do we initiate a class object by
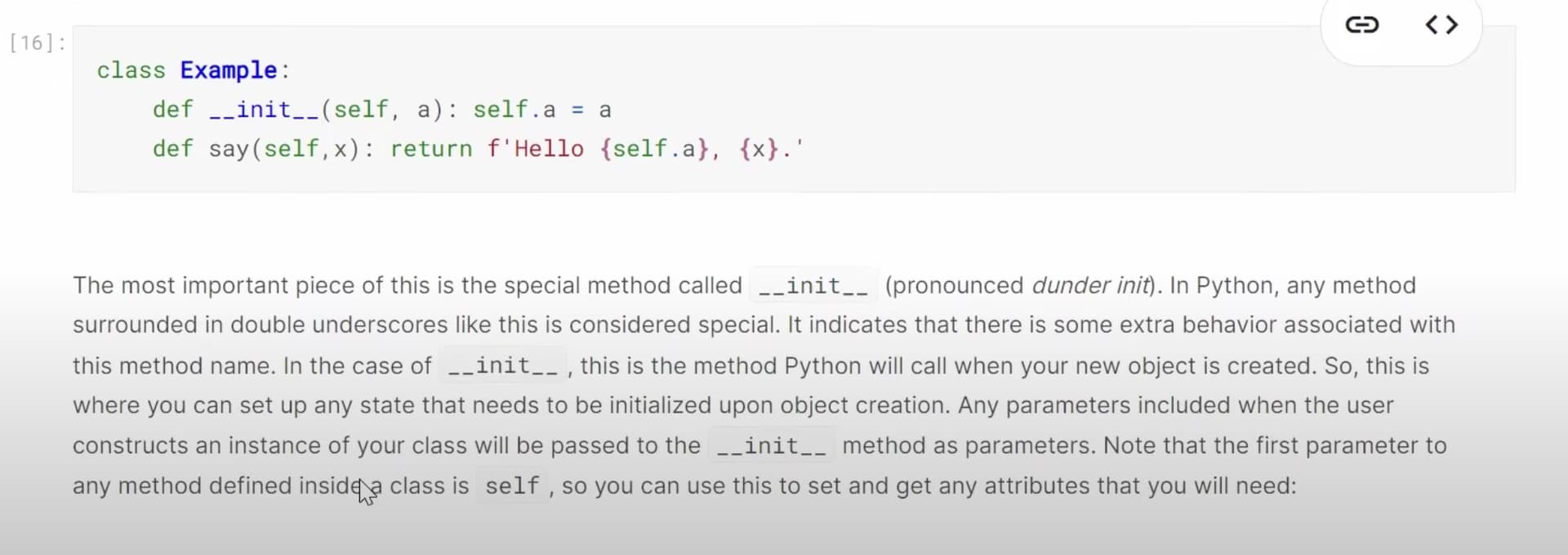
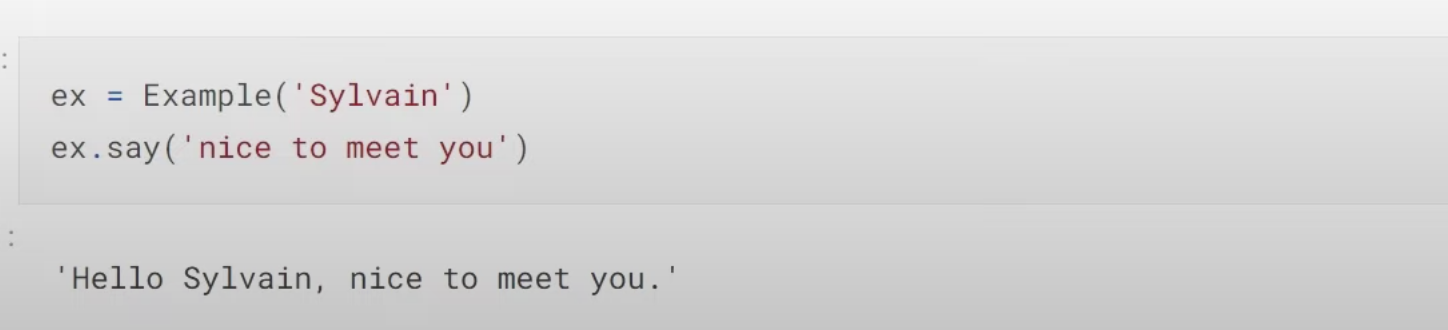

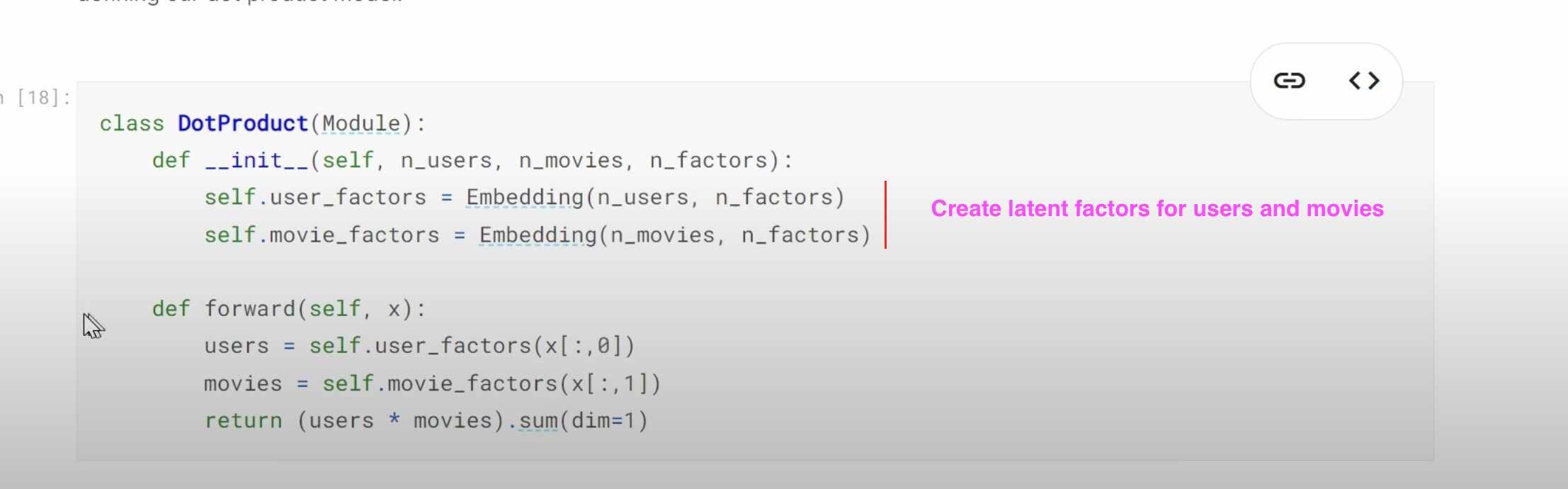
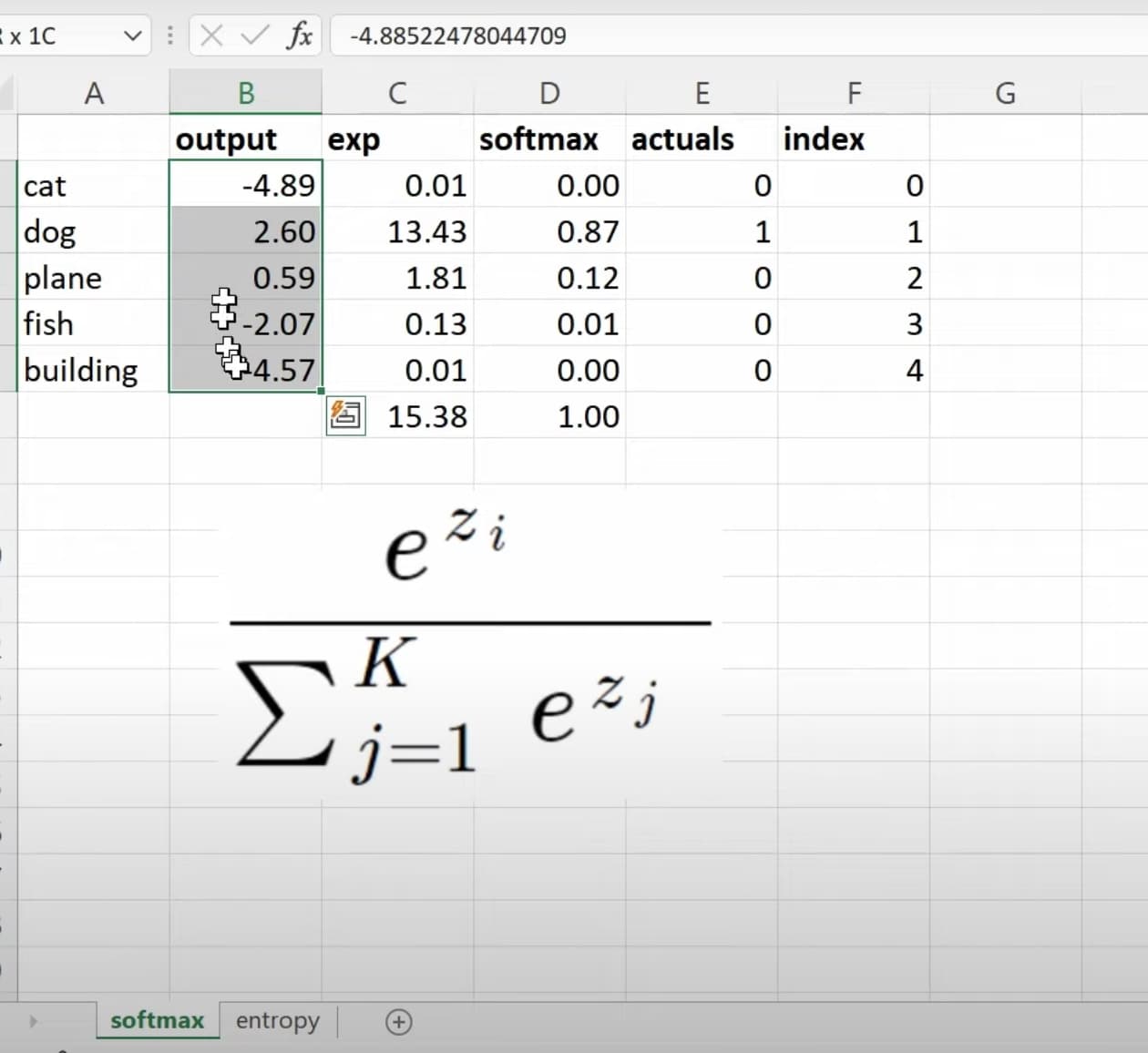
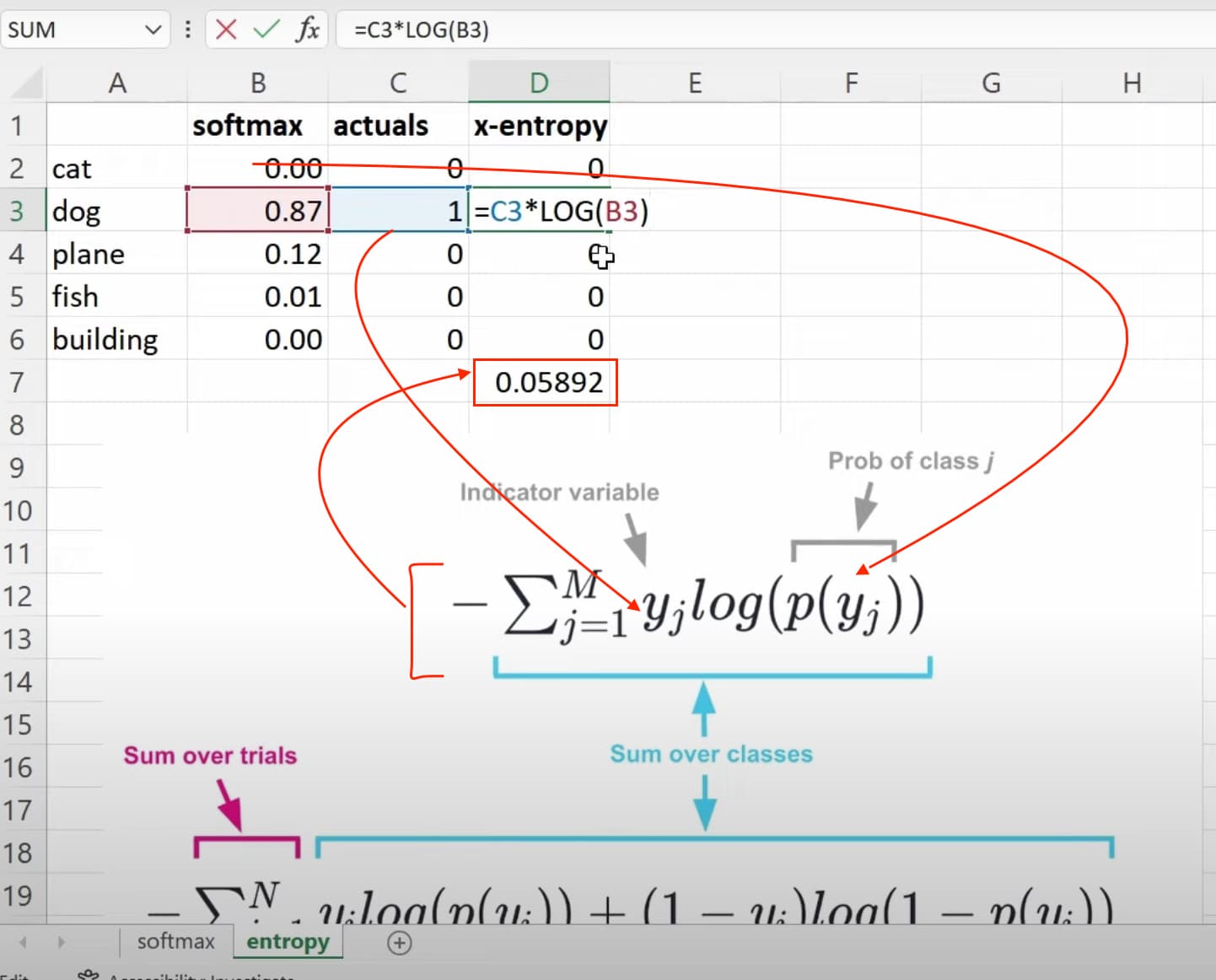
1:29:57 How to understand the

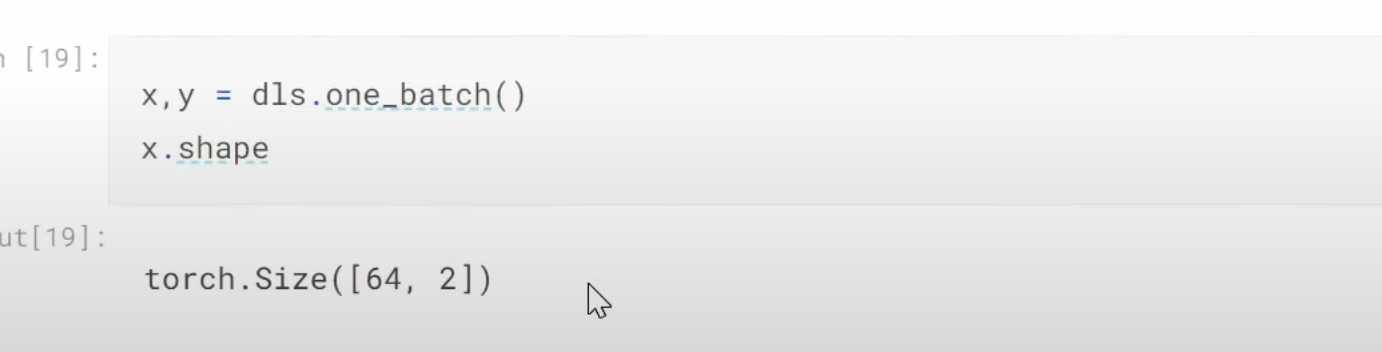

1:32:47 Why this collab model above is not great? (people who give ratings are people who love movies, they don’t rarely give 1, but many high ratings. Whereas the predictions have many occassions with ratings over 5). Review the sigmoid usage. How can we do sigmoid transformation to the predictions? How does this sigmoid work? Why do we use the up limit of the range


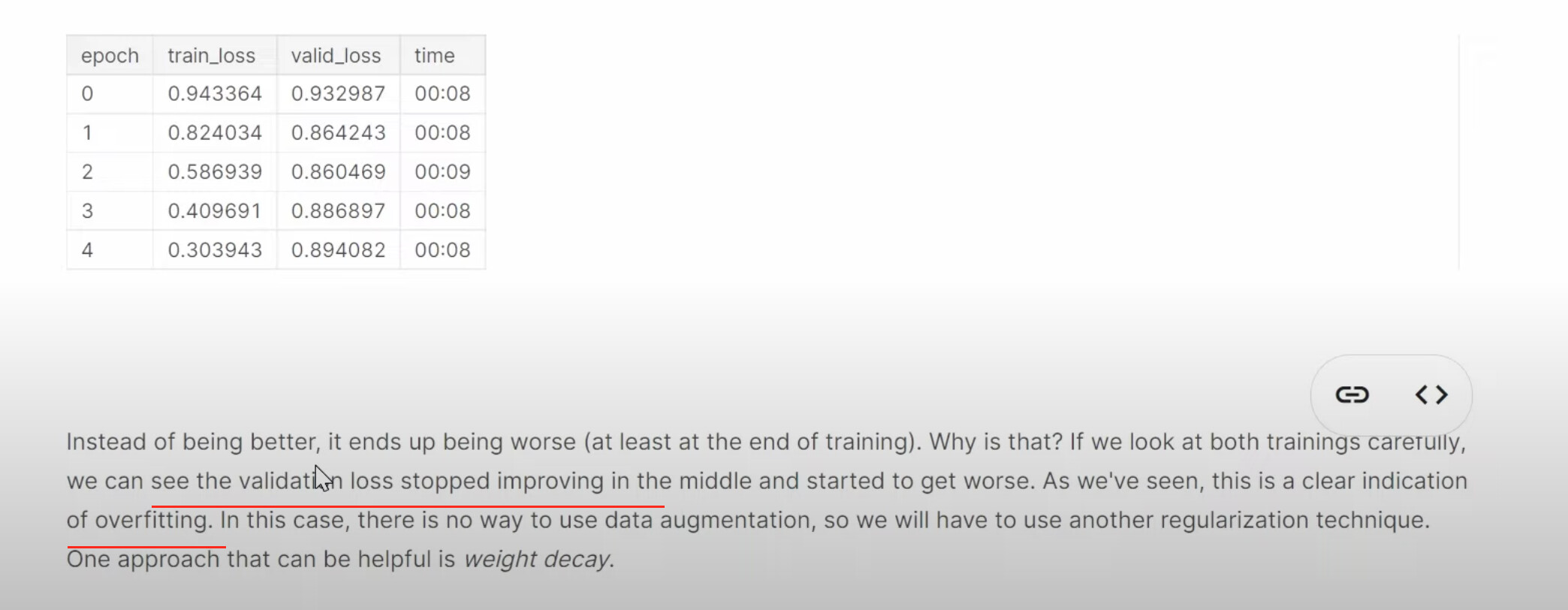
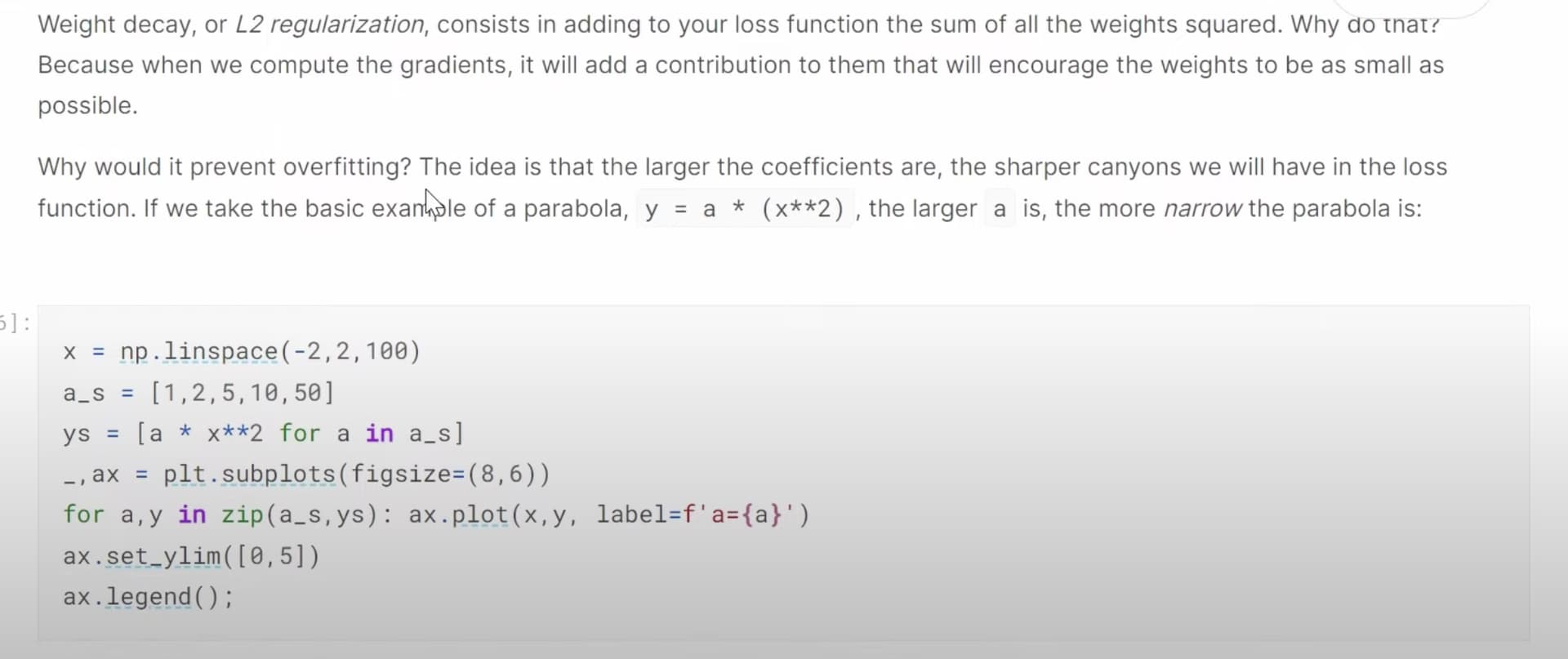
1:41:35 How to actually use weight decay in fastai code? Does fastai have a good default for collaborative filtering like CV? How does Jeremy suggest to find the appropriate


8 Likes