can anyone explain to me in this code the meaning of setting the max_card equal to 1:
cont,cat = cont_cat_split(df, 1, dep_var=dep_var)
does that mean to see all variables as continuous??
can anyone explain to me in this code the meaning of setting the max_card equal to 1:
cont,cat = cont_cat_split(df, 1, dep_var=dep_var)
does that mean to see all variables as continuous??
Looking at the source code, it defines every column of type “float” as continuous. Integer columns depend on the cardinality, if max_card is set to 1, then every integer column is treated as continuous as well. Every other column is categorical.
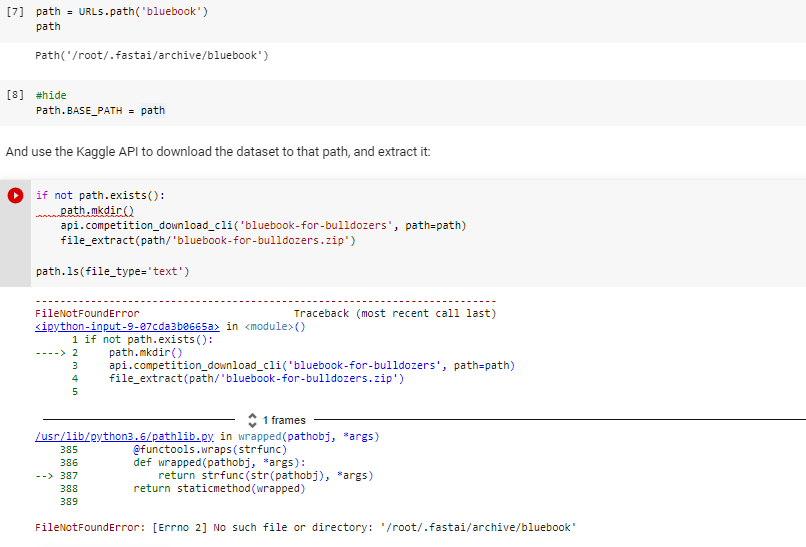
Im running into an error i can’t seem to fix. any help will be appreciated.
[Errno 2] No such file or directory: '/root/.fastai/archive/bluebook'
Even though I am following the exact steps as the notebook, I keep on getting this error when I run this code:
if not path.exists():
path.mkdir()
api.competition_download_cli('bluebook-for-bulldozers', path=path)
file_extract(path/'bluebook-for-bulldozers.zip')
path.ls(file_type='text')
Here is my notebook:
EDIT: I SOLVED THIS.
Anyone running into a similar problem change this line
to:
if not path.exists():
path.mkdir(parents=True)
The problem seems to be coming from the fact that one of the parent folders isn’t existing.
@Chikwado This might solve your problem too
Hi Chikwado and jimmiemunyi hope all is well!
I was looking at the code and noticed there is a logical error.
because if you create the path first, before you run the code, the three instructions below
if not path.exists():
will not run.
if not path.exists():
path.mkdir()
api.competition_download_cli('bluebook-for-bulldozers', path=path)
file_extract(path/'bluebook-for-bulldozers.zip')
The code should probably be as above.
hope this helps.
Cheers mrfabulous1 
Its a late reply but if you have not figured this out and for others -
If you go into the hierarchy.py file and change:
if labels and Z.shape[0] + 1 != len(labels):
to:
if (labels is not None) and (Z.shape[0] + 1 != len(labels)):
And restart kernel for this change to kick in.
Thanks, as you thought I have already done what you have mentioned.
Hello, in chapter 9 lesson 7, i have a question. What exactly does FillMissing do? I ask because i am given to understand that it fills missing values with median of the column, but in the picture i attached we still addressed missing value (despite using FillMissing earlier):
You’re right. For a few minutes, I was mind fucked. But then I realized that the authors have made a logical mistake.
I think you’re right. This appears to be a typo in the book. max_card=1 doesn’t make any sense to me.
cred_path.write_text(creds)
you need to change from write to write_text
path.mkdir(parents=True) you didnot add parents=True
Very helpful reply. Just trying the last two days different things. I understood there is a problem regarding labels because without labels it was plotting, Although labels are just numbers. However, never imagined one should change the actual scipy function. Thank you very much
I agree that max_card of 1 is weird, and it took me a while to figure out what was going on: setting max_card to 1 I got 51 categorical variables, setting it to 9000 I got 60 categorical variables. I then started investigating some of the 51 I got in the first case and I found out that they all had > 1 category.
If you look at the source code for the cont_cat_split(...) function (e.g. here), you see where the trick is: a variable is considered continuous if it has integer values and > max_card occurrences or if it has float values. In the case of the 51 categorical variables, they are all string-valued!
I’m having trouble understanding the answer to this question in the workbook 08 questionnaire:
Embedding if we could use one-hot encoded vectors for the same thing?
Embeddingis computationally more efficient. The multiplication with one-hot encoded vectors is equivalent to indexing into the embedding matrix, and theEmbeddinglayer does this. However, the gradient is calculated such that it is equivalent to the multiplication with the one-hot encoded vectors.
I understand the first 2 sentences, though I really don’t understand the “gradient is equivalent part.” Can someone share a concrete example of calculating the gradient of the multiplication of the one hot encoded vectors? How can multiplication have any sort of gradient?
Lastly, how does the Embedding class know about the gradient when all it’s doing is basically indexing in?
bump!
The embedding represents the latent factors per user/item. What we are trying to do is find these latent vectors based on the loss against the ratings.
We see the Embedding layer as containing parameters or a weight matrix w. The input to the model is x = [2, 3, ...]. The embedding layer forward pass finds the latent factors of these inputs by indexing into w. Now, since indexing is not a smooth function, we can’t really differentiate to get a gradient for gradient descent. Instead what the embedding layer does is it generates a gradient assuming that the indexing was done by a matrix multiplication operation between w and the one-hot vector as the two operations are doing the same thing.
Lets say the model inputs are x = [1, 3, 4] and there are 5 users in total. The one hot representation would be x_one_hot = [0, 1, 0, 1, 1].
The embedding layers thinks about the indexing as:
out = w.T * x_one_hot
# the embedding actually only does w[x]
# but it assumes it does a matrix multiplication as they are equivalent.
To show the gradient is calculated we need a loss function:
loss = (out - targ)**2 # (squared error loss)
# the gradient with respect to the loss for the weights dl/dw
grad_w = (2 * out) * x_one_hot # dl/dout * dout/dw


 !!
!!