Interesting answer regarding AutoML. I thought those frameworks didn’t necessarily exhaustively search the optimisation space and it was possible to do something similar to what Jeremy is saying, i.e. just try to tweak a few parameters at a time on a few simple models to get results more quickly.
1 Like
when I use tta during my training process, do I need to do something special during inference? It seems to me this is something you use only during validation, right?
2 Likes
What is the reason behind models taking even images of models in 224x224 square and also rectangular shape ?
1 Like
Yes, TTA is to be done only during inference
3 Likes
gpu need all imaes in the same size to run them in parallel, they could be square, rectangle format as long as all of them are the same size.
4 Likes
In which channel in Discord would I find this discussion? I follow the forums but I think I feel a bit overwhelmed by the numerous channels and discussion on Discord ![]()
1 Like
discord search function works pretty well i think ![]() link to thread Discord
link to thread Discord
tta during training on validation set it’s interesting idea… would take more time that’s for sure…
I have been a fan of fast.ai since the first lecture I watched, but while this is true, it is also true that somehow Jeremy continues to make the material even better, from year to year. I have no clue how that is possible ![]()
Lecture 6 was epic! The amount of practical information that Jeremy shared with us there… unbelievable.
I think there is great value (and pleasure! ![]() ) in creating an environment where you can work effectively and quickly. That was maybe a side discussion in the lecture, but it resonated very strongly with me
) in creating an environment where you can work effectively and quickly. That was maybe a side discussion in the lecture, but it resonated very strongly with me ![]()
And of course, the main subject of the lecture was legendary as well ![]()
I decided to run a quick experiment, the one with adding noise to your dataset, and here are the results:
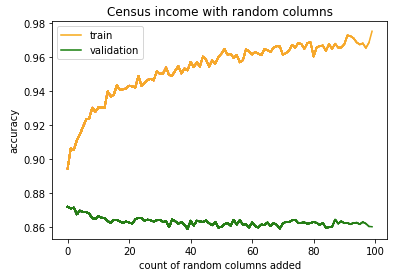
And this is not even using Random Forest but xgboost!
You can find the code here.
One other fun thing I am doing there (not sure if I am doing this right) is I am constructing the plot as training is under way. Wonder if there is a better way to do this? ![]()
Anyhow, this right here is of IMMENSE importance and there is so little information on this. The fact that tree models deal with noise so well has very important implications for what it makes sense to give your time to during preprocessing.
Sure, if your train set is not representative of your validation set, then that is a different scenario. But probably there is not a whole lot of reason to worry about having some columns that are mostly noise.
Maybe if you want to get the last 0.02 on some metric on Kaggle, but even then the effect of noise is probably not what we might imagine it to be. At least I have imagined the problem of noise to be much less subtle than it turns out to be ![]()
9 Likes
Thanks @miwojc but could you please tell me which channel it is within fastai discord? The link just takes me to the start page. Searching didn’t help.
the link to discord channel and thread i pasted is for:

try clicking on that link from my previous post, let me know if this doesn’t work for you. (btw i used search to find this, i searched for ‘part 2’)
4 Likes
I continue to find these lectures (and the walk-thrus) very inspiring ![]()
On the automation front, I can really see the value of it. I looked at all the repos under fastai and it seems Jeremy keeps on creating all these useful smaller or larger libraries to make his life easier ![]() For instance, checked out
For instance, checked out fastdownload just out of curiosity, very cool!
But I digress.
I don’t think doing such things is within my reach, but just doing simple things for myself can go a very long way. Since I wrote my little script for running docker, its hard to explain how much better my life has become ![]() I went from thinking about docker multiple times a day when switching between what I worked on to essentially not thinking about it at all
I went from thinking about docker multiple times a day when switching between what I worked on to essentially not thinking about it at all ![]() Or only giving it any mental space when I need to do something non-standard.
Or only giving it any mental space when I need to do something non-standard.
Anyhow, I laughed at the person who posted this xkcd some time ago, but maybe there is some merit to this kind of reasoning:
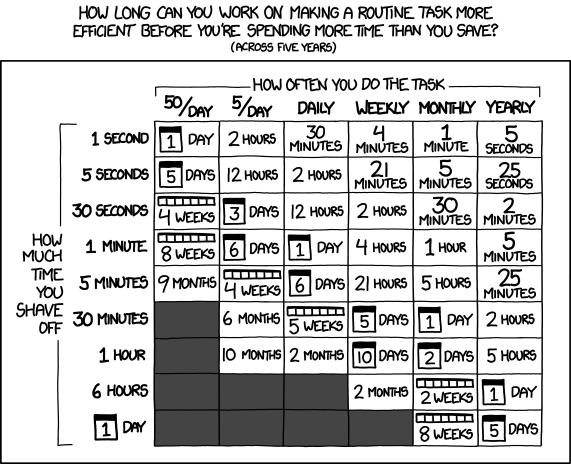
Still, I think for most of us there is just so much low hanging fruit, we don’t necessarily have to become hyper-efficient. Just removing small areas of friction/tediousness can go a long way.
Anyhow, I came across this rather cool course from Google on Coursera: Using Python to Interact with the Operating System. Not sure if I will watch it past the first couple of minutes that I have watched so far (I have a lot of things that I start and don’t finish, which is nice), but maybe someone will find this interesting. I could possibly just sit down and hack on stuff, and get something cool to work by just brute-forcing it, and while that is certainly a legit approach and something one has to do anyhow, there is a lot of value in understanding why something works the way it does or what are the tools people in a given area are using.
For instance, I have sort of known that shutil is used quite widely, but only while watching the couple of minutes of the lecture from that Google course did I see how people might be using it. Or on opening files using Python – I sort of knew what is happening in the background, but quite nice to hear someone tell you how all the pieces fit together (that when you call open the system checks your permissions to access a file and hands you over a file descriptor, there is a limited – though high – amount of file descriptors you can have open at any time, etc).
I can’t imagine one having too much bandwidth available while taking a fast.ai course, or for the next couple of months after a course finishes (probably investing your time in a fast.ai course is the highest ROI learning activity you can undertake and it doesn’t make sense to get distracted), and I still spent a considerable amount of effort to convince myself to not get derailed by stuff (and I often fail), but maybe someone will find themselves in circumstances where taking this Google course might be useful to them, so I thought I’d share the news about it with you ![]()
8 Likes
The problem with that cartoon is it ignores the learning you get from automating a task, which often is much more significant than the impact of the automation itself. If it makes you twice as fast automating the next thing, that’s huge! And the impact snowballs…
13 Likes
Not to mention if you’re like me and chronically will forget habits literally a day later randomly, it ensures you never have human error involved in your automation… ![]()
4 Likes
Sharing a thought that I’ll try to implement later on… Given that most images in the Paddy competition are oriented (480, 640) and a few are (640, 480), and the lecture says:
- “at some point, process them so that they’re all 480 by 640, or all the same size”
- “I guarantee at some point this is going to bite you” - regarding the difference orientation of tensors and python images.
I wonder if a useful pre-processing/augmentation step would convert a given image into two (480, 480) crops. In one case these will overlap vertically and in the other horizontally. At inference time, this will automatically do TTA-like averaging of outputs of the pair of sub-images. The advantage (maybe) being… the chance of mixing up tensor and python orientations is reduced.
1 Like
The RandomResizeCrop augmentation we do by default does something a bit like that.
2 Likes
Is Datablock API in fastai treated as mid level and using ImageDataLoader.xxx considered as high-level API? I see with DataBlocks there is more flexibility.
Also I was also curious what is then low-level in fastai then?
2 Likes
I’d assume the low-level in fastai is Pytorch itself.
Both of you are exactly correct
2 Likes
There is also a mid-level API that you build your custom transform pipeline yourself. You can take a look at the Siamese tutorial here: Tutorial - Using fastai on a custom new task | fastai
2 Likes