The basic idea is that if it is steepest, that’s the learning rate where it will learn the fastest.
2 Likes
even with a small learning rate, with enough epochs, shouldn’t it eventually find the minimum?
in lr_find so for every learning rate we use different mini batches at different step
– right ? So the mini-batch data set is not constant. Wont that affect the loss in addition to the lr ? How do we know lr is actually affecting the loss ?
Would it make sense to run one learning rate over a bunch of mini-batches (instead of just one) and measure average and variance to have an uncertainty estimate? This would probably reduce noise, as there are easier and harder mini batches I guess
The implementation of PyTorch lighting is heavily inspired by the one in fastai FYI 
6 Likes
Is it good to keep the same learning rate for the entire training or should we change it during the training?
It will find a minimum. The problem is it could be a local minimum and not the best one.
1 Like
Yep I am aware. I was just pointing out how fastai has set a precedent for other libraries 
1 Like
If the learning rate is too small, then the optimizer will get stuck in poor local minima and won’t be able to get out. There are exponentially increasing bad local minima as networks get more complex.
6 Likes
#TeamSylvain (min/10)
3 Likes
You should run it each time you change something major: if you apply more data augmentation, if you change the size of your images, if you unfreeze part of your models (stay tuned for that part).
4 Likes
Should we do lr_find every time we unfreeze a layer?
1 Like
It’s not just one, it’s a different one at each batch.
With too small of a learning rate there is a good chance that your model might get stuck at a local minimum instead of generalizing well. Also it would be pretty time consuming and computationally wasteful to pick a very small learning rate.
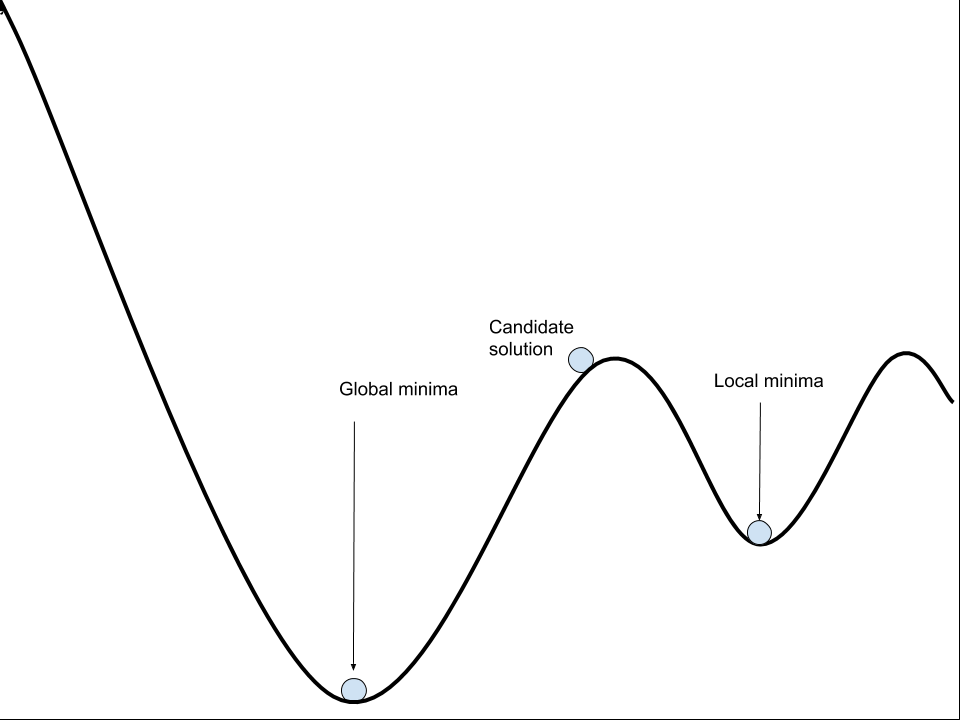
Image From: https://machinelearningmastery.com/why-training-a-neural-network-is-hard/
3 Likes
Top thing that “Jeremy says to do”: Trying the easiest things first-it applies very well to Kaggle competitions too among all things ML. 
6 Likes
Also gives you a good baseline to practically compare your model to.
2 Likes
We definitely should change it after training for a couple of epochs, or at least check it has not changed dramatically from our first guess.
I think Jeremy is getting there, e.g. after freezing/unfreezing top layers.
1 Like
Why would an “ideal” learning rate found with a single mini-batch at the start of training keep being a good learning rate even after several epochs and further loss reductions?
I think Jeremy is going to come back to this (since we haven’t talked about going several epochs yet), although ask again if he doesn’t
1 Like
yeah, I meant, within each lr. So:
a) set lr
b) fit next mini batch
c) reset
d) fit another mini batch
e) repeat b-d a certain number of times (10?)
f) measure average and std
g) change lr and restart from a
Just a little bootstrapping for each step so we get an uncertainty estimate for every step, and the plot would look like a shaded region and not a line.
2 Likes
Maybe I’ll try it out and see what happens, sorry I’m not explaining myself very well