yes it does, it uses the settings from the DataBunch, (which is why if you change something with your databunch you should rerun it), one of the parameters there is the batch size. As the lr finder runs through a number of batches and adjusts the lr after each batch, the batch size also has a very direct influence on it!
1 Like
Here’s an interesting paper looking at the generalization gap caused by batch size differences and proposes a few tweaks to avoid the gap. This paper finds that running more epochs with a higher batch size can achieve similar generalization and argues that it’s not the batch size that matters but the number of gradient updates. The authors also suggest using learning rate scaling with batch size, although they use square root scaling rather than linear scaling.
Also some interesting points on overfitting. The authors find they can improve generalization by continuing to train the model after the validation loss plateaus.
6 Likes
Will @jeremy also cover how progressive resize works with the different architectures @sgugger For example resnet34 size of 224 was suggested as best for transfer learning as this was the trained size, and resnet50 - 299 - how is this reconciled with 64, 128, 256 type progressive sizing? Or is that best for from scratch CNNs and not transfer?
3 Likes
Sometimes it may be possible to transform a tabular data task into an image task. E.g. movie ratings data could be translated into an image where x coordinate are users, y coordinate are movies, while ratings could be translated into pixels colors. Since the actual position of pixels and their grouping (correlation) is what important for images (typically similar pixels are close to each other in an image), this would only make sense if there is additional Meta data on users and movies, so that both users and movies could be meaningfully ranked (grouped). Not sure if this has been tried before, but technically you could use a resnet model on that. Maybe this is worth a try 
I have used the tabular learner for a raw numbers only dataframe without cat vars and therefore without embeddings. So basically creating a plain neural net with a few layers using fastai.tabular. A few tweaks are necessary, but overall it works fine. Head over to our Time Series Learning Competition thread to check it out! (shameless advertising! ![]() )
)
1 Like
More specifically: embedding() creates a weight matrix. The params to the function are the dimensions of the matrix. We normally say row by columns when describing a matrix. So the above function creates a # users by 1 sized weight matrix.
4 Likes
That won’t generally help, since your OS will already cache for you.
1 Like
There isn’t one table showing it - you have to grep the code to find them, like so:
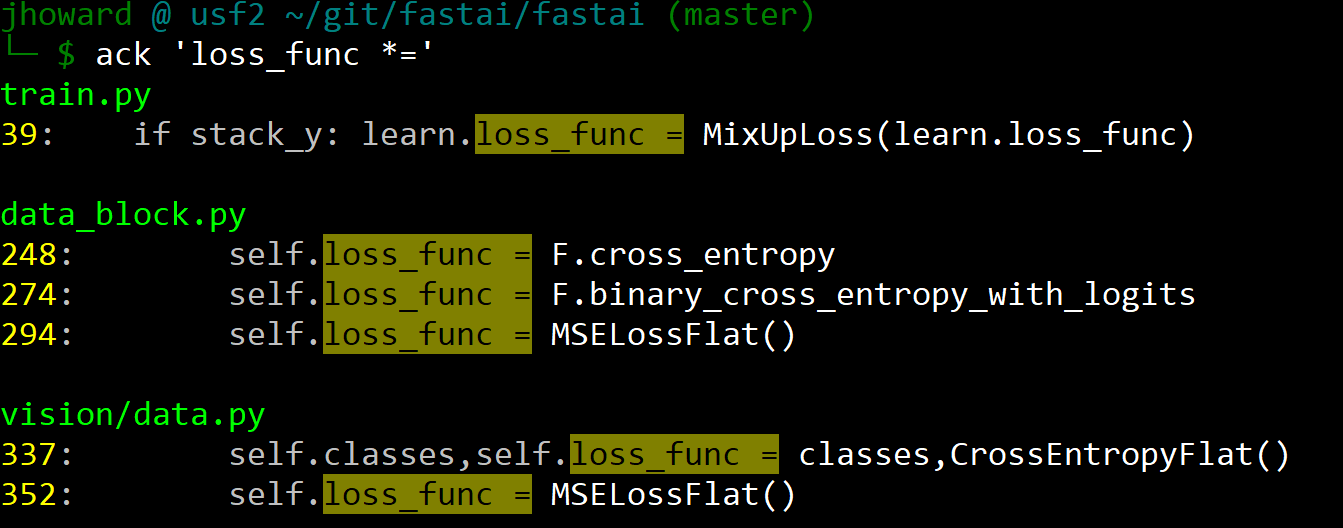
Easiest is just to create a learner, and then check learn.loss_func to see what was used.
2 Likes
I get an error while trying to print out a TabularList: ‘TabularList’ object has no attribute ‘codes’.
Digging into code source, I find this line: codes = [] if self.codes is None else self.codes[0].
But apparently, TabularList has no attribute ‘codes’. Can somebody look into this?
1 Like
Oh all this is great information helping me clear up the understanding of batch size.
@lesscomfortable also found a concise explanation on this matter reading through this notebook.
I believe this is what @jcatanza was essentially saying as well.
What does the loss tell us?
The loss is very noisy! While decreasing the batch size we increased the number of learning steps. Hence our model learns faster. But… with smaller batch size there are fewer samples to learn from, to compute gradients from ! The gradients we obtain may be very specific to the images and class labels that are covered by the batch of the current learning step. There was a tradeoff we made . We gained more learning speed but payed with a reduced gradient quality. Before increasing the batch size again and waiting too long for predictions we might improve by choosing another way:
- Weight regularization
- Gradient clipping
source link: Protein Atlas - Exploration and Baseline | Kaggle
2 Likes
I am a bit confused about math - lesson2 SGD correspondence.
SGD formula says w_t = w_{t-1} + dL/dw_{t-1} which is crystal clear.
However in update() function loop we have:
a.sub_(lr * a.grad). a are our weights tensor. why a.grad and where is the loss derivative here?
PyTorch does automatic differentiation, so a torch tensor stores the derivative of the computation done on it. So a.grad is the change in the weight, or parameter, and we’re multiplying it by the learning rate. Where the loss derivative is: I think that’s a.grad right? The gradients are calculated in the backward pass according to the loss value.
2 Likes
this makes sense! I didn’t know about automatic differentiation feature in pytorch. thanks!
1 Like
Jeremy says in lesson 4 that the sigmoid activation applied to the output of the model is the only non-linearity.
1 Like
FYI
I found this Coursera series on Hyperparameter tuning, Regularization and Optimization by Andrew Ng to be a great followup to Jeremy’s session (no registration required).
Topics covered:
- Mini-batch gradient descent 11:28
- Understanding mini-batch gradient descent 11:18
- Exponentially weighted averages 5:58
- Understanding exponentially weighted averages 9:41
- Bias correction in exponentially weighted averages 4:11
- Gradient descent with momentum 9:20
- RMSprop 7:41
- Adam optimization algorithm 7:07
- Learning rate decay 6:44
- The problem of local optima 5:23
7 Likes
can any one provide what structure I should follow to fine tune the language model?
any suggestions? @sgugger
Since it’s unclear and seemingly guesswork determining what features “actually” represent in the real-world, how can we determine whether or not our models are prioritizing features that might be ethically problematic?
Did you solve it? I am encountering the same problem.