I suggest to always use the df['xxx'] approach: otherwise sometimes name collision happens that would lead to very sneaky bugs…
3 Likes
Have you checked out the Kaggle API parts earlier in the notebook (the parts under section " Using Kaggle data on your own machine") - double-check that, as when you’re using your local machine, you’d need to download the dataset from Kaggle.
In general, you don’t need to add these signals into the text … you can just pass in your text.
What you are seeing here is a bit competition specific, where in addition to the text you also are given additional info that may be helpful in predicting the correct value. There are a variety of approaches folks take in these scenarios to include that additional signal like Jeremy is here, but generally, it’s not something you have to worry about.
6 Likes
fastcups is back online
1 Like
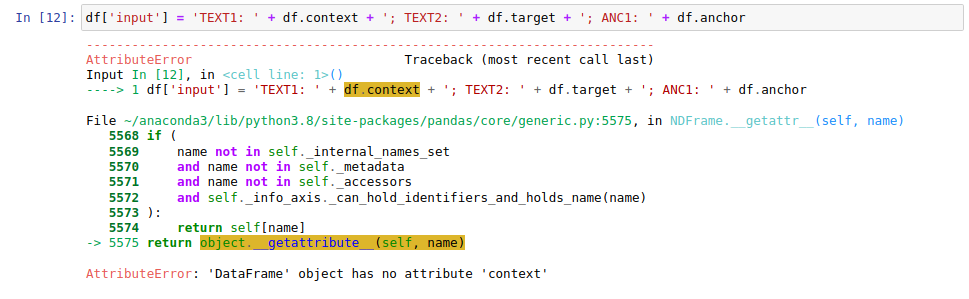
Also, if your column collides with some of the Pandas’ data frame attribute, you’ll get not what you may be expected. Like:
import pandas as pd
df = pd.DataFrame()
df["values"] = [1, 2, 3]
df.values # not what you would expected
3 Likes
Ah yes, thank you Zakia, that’s the issue I believe. I will fix now.
1 Like
Exactly, this kind of “collision” ![]()
3 Likes
What language models outside the huge generalised language models, Open AI’s GPT2 (soon to be GPT3) for example come close to being generalised enough to answer in a structured human-esque method? I’m more suggesting “If I make a nuanced data-centric model on a 1,000 to 1,000,000 rows using an open source hugging face model how can I explain to the stakeholders how it come to it’s prediction?”
1 Like
So, are there scientific journal papers for ALL 44,744 pre-trained models in Hugging Face models hub here:
https://huggingface.co/models
Amazing stuff!!!
1 Like
I think that any model can be uploaded there. So not only the original architectures, but also modified, fine-tuned, retrained on a different dataset, etc. You can create your own and upload there, for example. Like GitHub but for models.
6 Likes
No – most of these models will be specific fine-tuning by members of the HF community that will be based on larger / more well known models by major researchers. Those models will almost always have papers associated with them.
2 Likes
Question:
How does: tokz.vocab['▁of'] compare to tokz.vocab['of']
Note the underscore versus the no underscore at the beginning. I understand that the beginning of the field with underscore means its the start of a new word/ token - but just trying to understand, how does the tokenizer evaluate it then - if you add the underscore at the beginning, versus if you don’t, because if you check, the ID would be different for both (in the example I gave above).
Thanks in advance.
2 Likes
Is there a way to force or “keywords” to not be broken into pieces by tokenizer? IE: ensure that TEXT1 leads to a single token in the vocabulary.
BTW: pretty sure the language model will figure it out by itself.
2 Likes
Yup.
You can tell the tokenizer to add them as special tokens.
8 Likes
A strategy to get direct explanation of a particular output from a transformer, is to examine the parts of the input that the model paid the most attention to for creating the next token. Here are some of the approaches/tools: Interfaces for Explaining Transformer Language Models – Jay Alammar
2 Likes
Hi Jeremy,
Super excited about this chapter.
When you got to the PLATYPUS section of the Kaggle notebook, I was wondering about the following:
if we look at a token like ‘_an’, part of ornithorhynchus, which is then converted into a number, this will be (linguistically speaking) somewhat confusing later. How will we differentiate this ‘an’ as in ‘an hour’?
If we follow the logic of the dictionary currently being used, the number given from ‘an’ as in part of ornithorhynchus will be using the same reference number as ‘an’ as in 'an hour. Won’t that be confusing and potentially not helpful later?
Thanks for you help. John.
11 Likes
try df['context'] instead ![]()
3 Likes
Could you share the columns of df. I think that pandas series could be missing?
Try
df.columns
to confirm if that column exists.
2 Likes
Hi radikubwa,
This is what I get
