thank you @bencoman, I’m trying with bs=16, it is taking much longer but hopefully will avoid the OOM ![]()
1 Like
thanks @acal, I’m using text_classifier_learner which has the following signature:
text_classifier_learner(
dls,
arch,
seq_len=72,
config=None,
backwards=False,
pretrained=True,
drop_mult=0.5,
n_out=None,
lin_ftrs=None,
ps=None,
max_len=1440,
y_range=None,
*,
loss_func: 'callable | None' = None,
opt_func=<function Adam at 0x7f27f2582af0>,
lr=0.001,
splitter: 'callable' = <function trainable_params at 0x7f27f4ddb670>,
cbs=None,
metrics=None,
path=None,
model_dir='models',
wd=None,
wd_bn_bias=False,
train_bn=True,
moms=(0.95, 0.85, 0.95),
default_cbs: 'bool' = True,
)
learn = text_classifier_learner(dls, AWD_LSTM, drop_mult=0.5, metrics=accuracy)
did you just replace AWD_LSTM with ‘microsoft/deberta-base’ ?
Hello guys,
When repeating from what Jeremy taught in NLP for disaster tweets, I came across error like this:
KeyError: 'loss'
I made my notebook open for viewing, what I am doing wrong?
Hey @murodbek ,
huggingface transformers expect that the column it should predict is named ‘labels’. I think you are missing that in your notebook.
The error happens since the trainer can’t find that column, so it doesn’t know what to predicts, so it can’t calculate a loss, so it breaks.
If you fix that you will run into the next error immediately, I put the sollution for it into spoilers if you want to have a go at it yourself first ![]()
Spoiler
The default loss function is mse which expects floats. The target column in your dataframe contains ints, so if you change the dtype of the df to np.float64 in the beginning, the training should start ![]() .
.
Feel free to ask on if anything is unclear.
2 Likes
Thats awesome! After hunting around a bit I couldn’t find a Discourse tag for “spoiler”, but did find a “details” HTML tag. Is that what you used?
Lets try…
Peeka
Boo!Yes! Sorry for the naming confusion ![]()
Credit where credit’s due: I saw it in @qodrinzo’s post here. If you click on the pencil in an edited post you have the option to see the raw version and I “steal” usefull markup notation if I find some ![]()
If you want to get the raw version of an unedited post you can use the topic’s and post’s ids (shows when quoting something from that post) to navigate to:
https://forums.fast.ai/raw/toppic/post
So the raw version of your post is at https://forums.fast.ai/raw/96441/316 for example ![]()
Hope thats not too much off-topic ![]()
3 Likes
Dear @benkarr both of your teachings does work and thank you so much
1 Like
Hi all! Just watched Lecture 4 and read pieces of the textbook.
I have sensed a difference in approach to NPL in the lecture and the textbook., i.e., using Transformers VS RNNs.
I googled “transformers vs rnns” and a little digging got me to this paper Attention Is All You Need.
That is the first research paper I opened and tried to read with no success in understanding what it’s all about ![]() .
.
But what I got was Transformers sort of discards RNNs as it is much better.
I wanted to know, if I should focus on diving deep in RNNs or should I focus more on Transformers for NLP?. Should I use the “NLP for absolute beginners” NB as a base of approaching NLP or what is in the book?
Thanks!
As Jeremy said throughout the course, in the beginning it is not important whats happening in the middle (the network architecture). It’s much more important to understand what is happening at the start (your data going into the neural net) and on the last layer (softmax, sigmoid, loss functions etc.).
The fundamentals of NLP are the same, whether you use a transformer or a type of RNN (RNN, LSTM, GRU) as your neural network architecture. Tokenization, Embeddings etc. are all concepts that are the same for transformers or RNNs.
Thinking of transformers as a black box doesn’t hinder you of using them effectively.
3 Likes
How to re-train small NLP model to different language without using multi-language model. For example:
retrain microsoft/deberta-v3-small to work with turkish language.
I have trained a model similar to what this lesson created (fine tuned) and uploaded it to Huggingface.
The problem is that the predicted label using the Huggingface web interface is incorrect (ie, it does not match the prediction that I get locally in the notebook).
I think the problem is that in the notebook, we predict as shown below:
eval_ds = Dataset.from_pandas(eval_df).map(tok_func, batched=True)
preds = trainer.predict(eval_ds).predictions.astype(float)
I think it’s because Huggingface does not know about the tok_func and, therefore, feeds the input text from the web interface to the model.
Question: what is the correct way of dealing with this problem?
Thanks!
Hi Shai,
Did you manage to resolve this?
I have more or less exactly the same issue. I have been tearing my hair out the last few days ![]()
I put together this NoteBook which combines features from Getting started with NLP for absolute beginners and Iterate like a grandmaster!
but I am running into this error when I try to train the model:
ValueError: all the input array dimensions for the concatenation axis must match exactly, but along dimension 1, the array at index 0 has size 1 and the array at index 1 has size 9119
The only real change I made to Jeremy’s NoteBooks was to use a different model anferico/bert-for-patents - so I’m guessing I maybe need to tweak the arguments to fit? I can see that the 9,119 relates to the size of my validation set, but not exactly sure what the overall issue is.
Any suggestions would be most appreciated. I really want to make my first Kaggle Competition submission!
Thanks,
Stephen
3 Likes
Is this the integration of Transformers into fast.ai Jeremy mentioned in the lesson?
I think that’s the one?
There’s also this library which is built on top of fastai and is used for HF transformers.
1 Like
I’m in the same boat! I’m just trying to switch the training model and running into this ValueError. I will keep you posted if I make any progress!
1 Like
Thanks so much for this wonderful lesson. @jeremy I would like to point out something that might need correction, which is only indirectly referred to in the lesson: the “correction” I would point to is in this post about training/validation/test splits, which you show in the video:
At the end of the post, it says why it is dangerous to use scikit-learn’s cross-validation (and in particular K-fold cross-validation): because it uses random selection of samples. However, scikit-lean currently offers different K-fold cross-validation methods: GroupKFold allows to put all the samples from one group (e.g., the same driver, or the same boat) in one of the splits, avoiding leaking information. Likewise, there are other methods suitable for time series, for stratified data, and so on, and they are increasing the possibilities to cover real-life situations. Just a small detail, but I think it is important that people know that.
Thank you again for your wonderful course.
1 Like
Dear all. I have run the Lesson 4 notebook “Getting started with NLP for absolute beginners” on kaggle and on my computer.
When I look at the number ID of the word _of
- On kaggle - returns 265 as expected
- On my PC - returns KeyError as ‘_of’ is not found. Instead it has ‘of’ which is in posn 1580. What is strange is that the tok_func has correctly assigned _of with 265…
Could this be due to installation differences? FYI I have had issues with dill 0.3.6 and python 3.10 and so had to downgrade to 0.3.5…
Ok. So found the issue.
On my local pc the underscores are in bold. So
tokz.vocab[‘▁of’] returns 265 - you may not see it but this underscore is bold
tokz.vocab[‘_of’] returns KeyError - this underscore is not bold
UPDATE: FIXED - See last lines of the post.
Hello,
I’m encountering an error KeyError: loss when running the training code in my notebook located here:
model = AutoModelForSequenceClassification.from_pretrained(model_nm, num_labels=1)
trainer = Trainer(model, args, train_dataset=dds['train'], eval_dataset=dds['test'],
tokenizer=tokz, compute_metrics=corr_d)
trainer.train()
It is quite likely I’m doing something wrong that’s preventing how the model calculates loss.
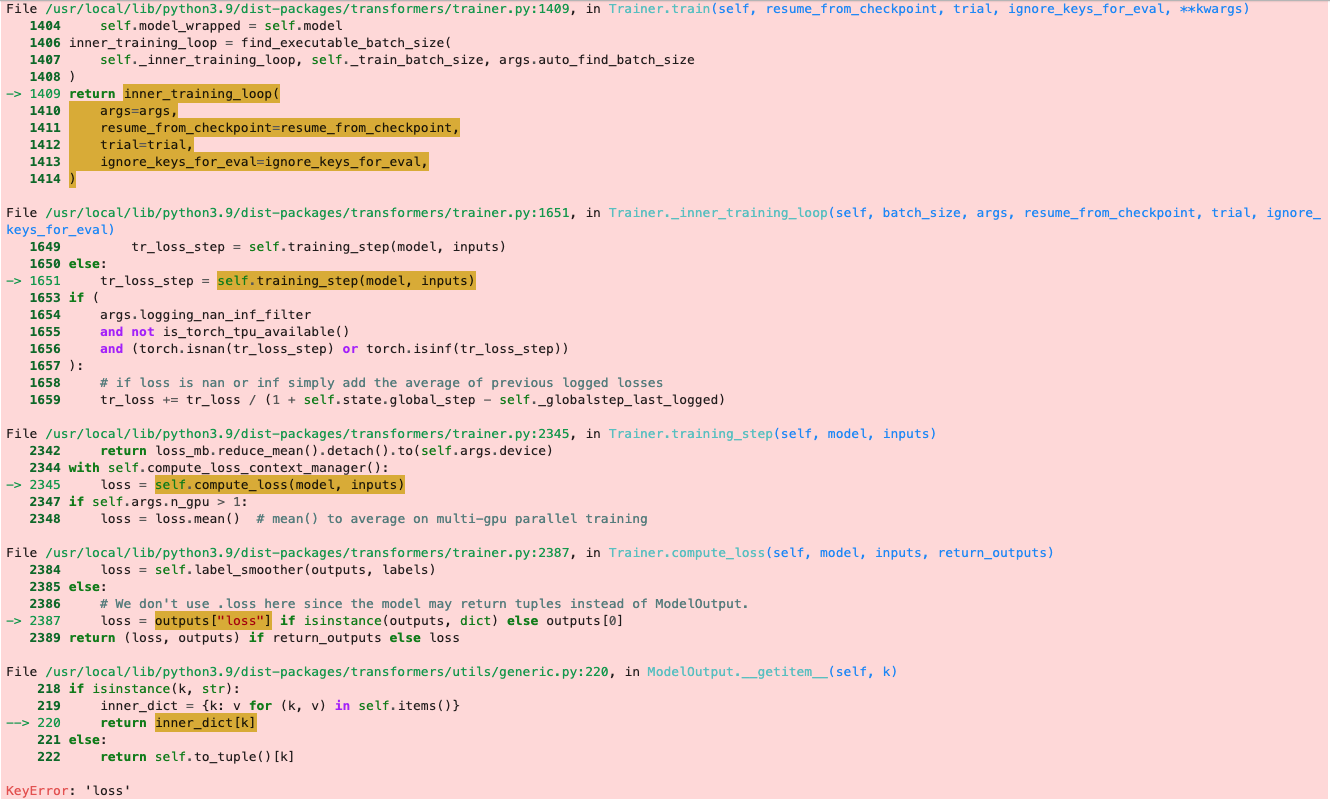
I would appreciate help to debug this error. Thank you!
EDIT:
I missed a column rename step in the notebook - my mistake.
tok_ds = tok_ds.rename_columns({'score':'labels'})
AJ
Aspiring Astro
2 Likes
As a follow-up to my original post, I was able to resolve the bug I introduced, not renaming the score column to labels
Jeremy always reminds us to look at both inputs and outputs produced by the model. I can look at the prediction scores and compute MSE for the scores produced against the validation dataset. But, I want to actually look at the text output, the predicted set that came from the model. My understanding may be wrong, please correct me.
For example, I extended this notebook to look at the validation set and run a final prediction to then generate the predicted_score and actual score, and compute MSE.
valid_df = dds['test'].rename_columns({'labels':'score'}).to_pandas()[['id','anchor','target','context','score']]
valid_df['input'] = 'TEXT1: ' + valid_df.context + '; TEXT2: ' + valid_df.target + '; ANC1: ' + valid_df.anchor
valid_ds = Dataset.from_pandas(valid_df).map(tok_func, batched=True)
valid_preds = trainer.predict(valid_ds)
valid_pf = valid_preds.predictions.astype(float)
valid_pf = np.clip(valid_pf, 0, 1)
from sklearn.metrics import mean_squared_error
from sklearn.metrics import explained_variance_score
MSE = mean_squared_error(y_true = valid_df['score'], y_pred = valid_df['predicted_score'])
MSE
MSE**(0.5)
0.14964146302443787
Is there a way to peel back one layer and look at predicted text from the NLP model?