Regarding interpretation: except for the compute time, is there any other concern with calculating variable importance for a neural net?
2 Likes
As I am thinking yes, When we build ML models using ML interpretation we try to say which features are actually driving the result and in business scenarios we need to deal with those feature more closely than others.
At my place of work we have the following approach to a cold-start problem:
For context, I am at a financial institution and we have trained a collaborative filtering model on data purchased from a third party which consists of ~40k businesses detailing their cash management needs. Specifically, it might look like business Y has reported it uses lock-box, fraud-management, equity-management, etc. (from a list of about 40 products).
How we use this to build a recommender for our own customers (who were not part of the model training process): the model works by embedding each unique user and product into a space of some fixed dimension and modeling the probability as a dot product or perhaps shallow neural network. So given a new user, if we knew where they stood in the embedding dimension we would be able to apply our model and say how likely does it think this user is to want product X.
We build a second model (as Jeremy has suggested) using auxiliary data, things like sales volume, number of employees, SIC codes (what ‘kind’ of business it is) and train this model with the following 40k datapoints: we know these features about the businesses in our purchased dataset, and we build a regressor that maps from these “identifying features” to its position in embedding dimension with RMSE error. Once we are satisfied we can situate a new client reasonably well based on these identifying features, we can take a new user, apply model 2 to situate them in embedding space, and then apply the original collaborative filtering model.
Happy to discuss if someone is curious!
26 Likes
CNN for text classification … quite useful
1 Like
2 Likes
A friend sent me a dataset of NBA team offensive and defensive rating, consisting of the rating for the previous year, and rating for current year to date after each game. The goal is to predict what the rating will be at the end of the current year. I was going to try to use a RNN, but based on what Jeremy just said, it might work better to extract columns? Am I understanding that right? What does extracting columns mean, exactly?
@alenas
I assume you are discussing time-series data such as sales over time; my understanding is the fast.ai tabular api separates temporal information into date-parts like day of week, time of day, etc. and treats it as categorical and feeds into a linear network. For attentional models it requires an RNN framework. My experience has been treating time-series data from an RNN point-of-view can be very successful but only in situations where there is sufficient data which varies from problem to problem. Definitely worth experimenting with, it has brought me success in the past! See this thread https://forums.fast.ai/t/time-series-sequential-data-study-group/29686/19 for more discussion on DL approaches to time-series classification/forecasting!
2 Likes
This would be pretty common e.g. for a listing site like Amazon or eBay.
If I understand correctly we add fully connected layers on top of separate models for the text (RNN), image (CNN) and columnar (dense NN), and train the whole thing end to end.
What I’m not sure of is how we would deal with a variable number of images (e.g. there are 0-30 photos of products in a carousel), and relations between columns (e.g. this item has had views from user 1, … n at times 1, … n; can we use this data without manually engineering a bunch of features?)
Can you use Conv layers and embeddings to encode hierarchies in graphical models?
This thought came up, because I’m working with a tabular dataset that actually represents a graph model with some nodes serving as central hubs for others… but the CSV representation doesn’t capture that: everything is ‘equal’.
I’m sure the neural net can learn importances for different layers… but…
Could you have linear or embedding layers output a tensor that’s essentially like an image — which is then ‘scanned’ by a convolution. So just as with vision, you can have ‘layers’ of abstraction in the architecture of your model.
The other idea is could you use weights of a graph model as initial weights for an embedding layer — and use that to either start or encode the relationship among different nodes in a network. The thought being that the weights, representing graph/network connections could change, and a model can figure out a graph much better than any person can.
4 Likes
1D-CNN has been studied to do better classification on texts than just LSTM. 1D-CNN stacked with Bidirectional LSTM said to improve the accuracy further. Paper: https://www.aclweb.org/anthology/C/C16/C16-1329.pdf
2 Likes
Regarding the logistic sigmoid type of function Jeremy very briefly drew to help constrain the values to “0 to 5” at the output of the movie recommender: Lecun et al. once recommended zero-mean & tanh instead of logistic sigmoid. Specifically, 1.7159 tanh(2/3*x). This was in “Efficient Backprop,” pp.10-12.
In section 4.5 on p.12 ("“Choosing Target Values”), they say…
“Common wisdom might seem to suggest that the target values be set at the value of the sigmoid’s asymptotes. However, this has several drawbacks…a solution to these problems is to set the target values to be within the range of the sigmoid, rather than at the asymptotic values”.
I don’t often (actually, ever) see people teaching this. Is it no longer relevant? (Seems like going beyond the target value would screw up a cross-entropy loss that relies on log functions – which can’t take negative arguments!) …Or perhaps Jeremy will get to this next week!
6 Likes
Thanks for the reply. Yes I agree with you on the concept of how we would go about solving this. I guess my main question would how do we go about doing this with the FastAI library.
The library does not have inherent support for training something like this (in terms of creation of data bunches for such heterogeneous data). So, at what level do we take advantage of what the library has to offer? Do we (the user) create our own data bunches by processing the data and then use the training loop (and supported training structure) offered by FastAI? This is where things get complicated.
Is there an easy way to use a multidimensional tensor as an input to the fastai text learner RNN?
Instead of using a text tokenizer I want encode my values in a multidimensional tensor.
I guess this will be tricky as the NLP architecture is used to a stream of 1D tokens and I would need a custom network architecture for n-D?
Maybe there is also an easy way to add a custom input stage to transform raw data for the RNN, which would enable to learn the (pre-)encoding end-to-end?
I would be happy about suggestions in this direction. 
1 Like
Maybe wait till Part 2 of this new course, when jeremy opens the kimono?
Not quite, but I’ve tried to translate what I think the idea is. Jeremy was referring to a different kind of data set.
its unlikely that a basketballers playing ability is affected by the day of the week, whether there’s a holiday, month of the year etc. But they are likely to be affected by things like - how many games they played recently and how much they had to travel. these would be types of data you could “extract to columns”
if you were looking at tabular data for shopping sales, things like days of the week, holidays (or day until/since a holiday), time of year etc would be columns to pick up (compare to RNN time gaps). I think Jeremy said this theme is coming up next time
1 Like
I have a question about the sigmoid used to make sure that our rating predictions remains between the 0 and 5 bounds. Could the use of such a sigmoid cause problems for very small ratings (i.e 0 or 0.5) and very large values (i.e. 4.5 and 5) as the sigmoid saturates and requires very big values to output such extrema. From my understanding, using the sigmoid will make the predictions to go favorably to intermediate values (say between 2 and 4).
In this case could it be relevant to use a function linear between the min and max values, some kind of ReLU5 (don’t know is such a thing exists  ) ?
) ?
1 Like
When we say language model, it predicts the next word based on previous words. I was curious how it is trained? Is cross entropy loss function used?
Since the vocab size is, say 60000, it has to predict the next word out of these 60000 tokens. Can we view this as a classification problem where the model predicts one class (here word) out of 60000 classes (here vocab size)
I assume moms is momentum (in vectors). I think of momentum as, if you are going in right direction take larger step.
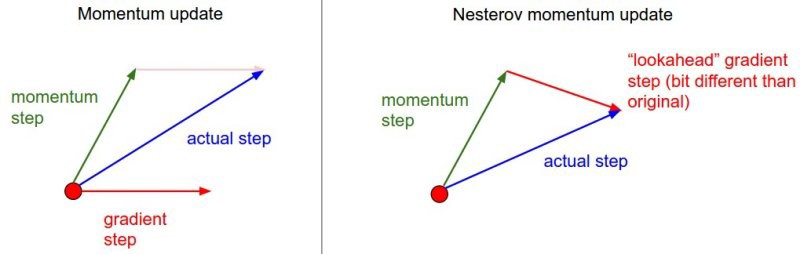
See more at, https://towardsdatascience.com/stochastic-gradient-descent-with-momentum-a84097641a5d
1 Like
Hi @mb4310, will you discuss identifying features,
we build a regressor that maps from these “identifying features” to its position in embedding dimension with RMSE error.
can you please also explain the following.
During transfer learning in Image classification. We are freezing all the initial layers and chopping off the existing last few layers and replacing them with new layers based on our number of classes and then training only those newly added layers.
what is the role of freezing the layers in the language model in case of transfer learning? what are the last few layers which we are chopping and then replacing them with new layers which we are initially training?bcoz for the encoder part`we are only doing unsupervised learning i.e. there are no labels?So what layers are we initially training?
Can you also recommend an article which shows how to use pretrained_model=URLs.WT103 directly in pytorch?