When we use our model to predict the class of a new image, are the item and batch transforms applied to that image first?
@PDiTO When we call .predict() the same image augmentation that was done to the validation set is done here.
1 Like
There is some kind of invalid input that crashed the python code… Looking into it now. I restarted the server. Thank you for reporting that !
2 Likes
Does the image augmentation change between calls ? For training the augmentation presents a different image for each epoch. Is that the case when doing multiple predicts on one image ?
Hi Sylvain,
I think the augmentation you are talking about is only applied to the training data (ie. contrast changes, rotations, etc), not on the validation set. I believe that’s why Zach specifically calls out .predict() only performing validation set augmentation.
The doc states:
get_transformsreturns a tuple of two lists of transforms: one for the training set and one for the validation set (we don’t want to modify the pictures in the validation set, so the second list of transforms is limited to resizing the pictures). This can be passed directly to define aDataBunchobject (see below) which is then associated with a model to begin training.
1 Like
Thanks, that makes sense. Just resizing. I thought he was saying all augmentation was performed on the validation set.
Interesting question. Any examples you know of of comparable features that posed security issues?
If there is no clear winner (among categories), couldn’t the classifier decide that it is none of them?
Edit: in other words, what karthikramesh said.
And saw your response too…
More specifically, where do you apply your threshold? I assume you are looking at the probabilities for each category.
Also, rather than a threshold (and if there are many categories), one could instead look for a “clear winner”. On the other hand, rugby, football/soccer and (american) football are together more similar than golf and croquet. So if a picture is one of rugby, say, there might not be a clear winner between rugby, football and football, but the model might decide that it is pretty certain that it is one of them, and not one of golf or croquet. If the picture is of none of the categories, then the distribution of probabilities should appear unusual. But again, how to detect that…
yes that’s it! thanks a lot!
I took a quick and dirty approach based on some limited testing - if the prediction was less than 98% then I offered also the 2nd place guess. I did also categorize some random pictures as ‘not a sport’ which was ok - but I agree some ensemble approach for the similar sports would have been another way. I also made some decisions on the type of pictures to train on - and excluded team shots (they were more prevalent for some sports and not others - so introduced a bias) and also long view stadium pictures for a similar reason. The model was ok for action shots with a few players.
I think I got it. I added a check to validate URLs.
1 Like
FYI in your deployed application when feeding images from URLs to your model, the python library you are using will set the request header ‘User-Agent’ to something like: ‘Python/3.7 aiohttp/3.5.4’
A lot of servers will block content if they detect a User-Agent that is not a recognized browser. This is to discourage web scraping.
For example a valid User-Agent string for Firefox on OSX would be:
‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9’
So if you put a URL in a browser and the image displays properly but you get an error when that URL is used in your Python code to get the image, you are most likely being blocked because of the User-Agent header.
To mascarade your web scraping activity as a browser you can change that User-Agent string.
For example with the aiohttp library:
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'
headers = {'User-Agent': user_agent}
async def get_bytes(url):
async with aiohttp.ClientSession(headers=headers) as session:
async with session.get(url) as response:
return await response.read()
3 Likes
Ah interesting, I’m using Brave browser so maybe thats why it didn’t work
1 Like
The browser you are using does not matter, you send a URL to my app. My app makes the actual GET request to get the image. The request would be blocked at the app level if the targeted server was monitoring User-Agent headers. I fixed my code already but here is a URL that will work in a browser and be blocked if you fetch it through python code without changing the User-Agent header to a valid browser: https://audubonportland.org/wp-content/uploads/2019/01/American-Robin-5D3_8701_filtered-SC.jpg
1 Like
Thanks @sgugger , a follow up question.
When we represent image pixels as RGB array, each slice having value, 0/1, there would be only 8 combinations to represent each pixel.
That is R, G, B, RG, GB, BR, RGB, or None
Would we not be losing information when doing so? Any idea on how it would affect on the learning process?
When you take a picture with a camera this is what happens: source
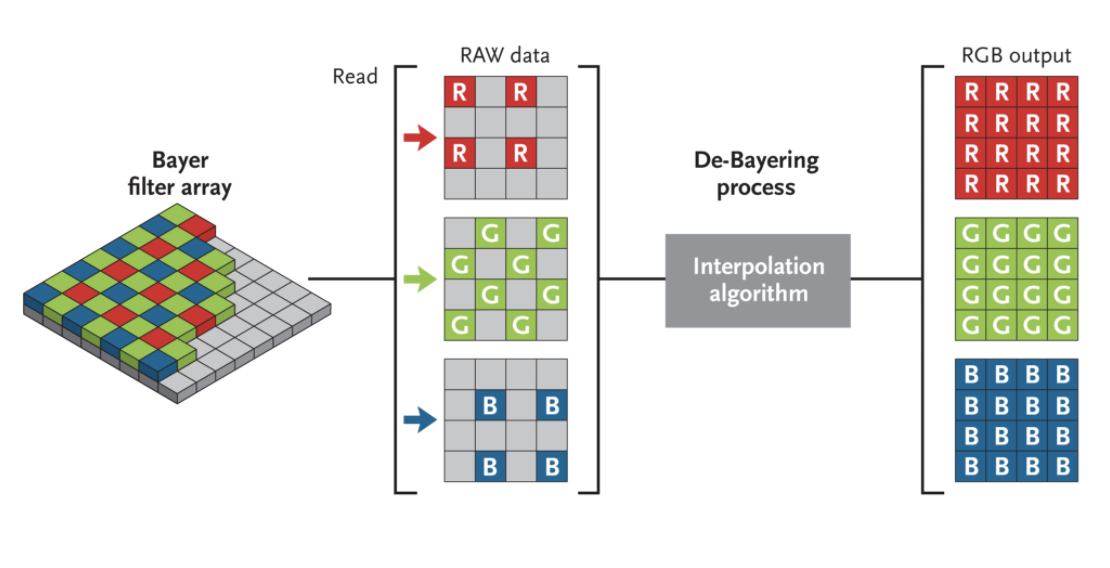
{kind=link}
When we talk about images we are talking about the right hand side of this figure “RGB Output”. These three channels (Red, Green Blue) are stacked one over the other. So in this figure each channel has 16 pixels, 4x4 matrix. So if we stack them up we get three 4x4 matrices => 4x4x3. Now each of the pixels in this 4x4x3 can range from 0 to 255.
Now if we are looking at a black and white image we have only one channel and each pixel in it can vary from 0 to 255 (0-black , 255 white this is just a convention and can be reversed. so pixel with value 128 is gray).
So if a image looks reddish it means the Red channel has high values (following the convention 0-blk, 255-white).
All this happens in an ISP (Image Signal Processing Pipeline) we never have to bother controlling it. So when you get an image it has 3 channels stacked, one for Red,one for green, one for blue and each pixel can vary from 0 to 255 values.
 hope that helps
hope that helps
4 Likes
Anyone else having Paperspace issues? I’ve reopened a notebook I was working in, suddenly the images folder that was referenced by the fastbook repo is gone, and my utils import is missing search_images_bing now. It frankly looks like a bug with the virtual environment creation from Paperspace when it relaunches images.
having the same issue. it was working fine earlier
I ended up having to create a whole new notebook. Not happy, considering I’m paying for the service. I’m now having issues and errors i didn’t have before, around WEBP issues when trying to run the verify_images function. Pretty irritated. I’m suspecting issues with virtual environment creation or something like that. Another gripe is that the notebooks shut down, even if you are in the middle of using them. I thought the 6 hour limit was for an inactive notebook, but no, they just kill the instance.