I tried your code. same error
I am on fastai rel 1.0.22.
It could be a defect in 1.0.22
Remember
Thus the label id has to be from the train.csv file. label_from_func is not right
Label.csv contains something like this:
| ImageId | LabelName |
|---|---|
| 00022e1a.jpg | w_e15442c |
| 000466c4.jpg | w_1287fbc |
| 00087b01.jpg | w_da2efe0 |
| 001296d5.jpg | w_19e5482 |
execute code above the untar_data:
from fastai import *
from fastai.vision import *
1 Like
Hi all, For classification problems we can use the library to create interp = ClassificationInterpretation & quickly check confusion matrix, top losses etc.It would be great to be able to see similar interpretations for regression problems (like planet) - for e,g, which labels were most often missed or confused…
- Is there a similar RegressionInterpretation approach? and/or
- anyone run quick checks for regression they would reccomend?
2 Likes
Re your question re the ImageMultiDataset @marcmuc - I also notice that in the 2nd run with larger images we do use the ImageMultiDataset per below… did you resolve this? would be really interested to understand if need to add the multidataset into the first data creation line
data = (src.datasets(ImageMultiDataset)
.transform(tfms, size=256)
.databunch().normalize(imagenet_stats))
thanks for the response @marcmuc, agreed - trying to avoid adding more clutter to thread so thanking you here 
I think it has to be added like in the second run. I submitted a PR for the lesson Notebook…
1 Like
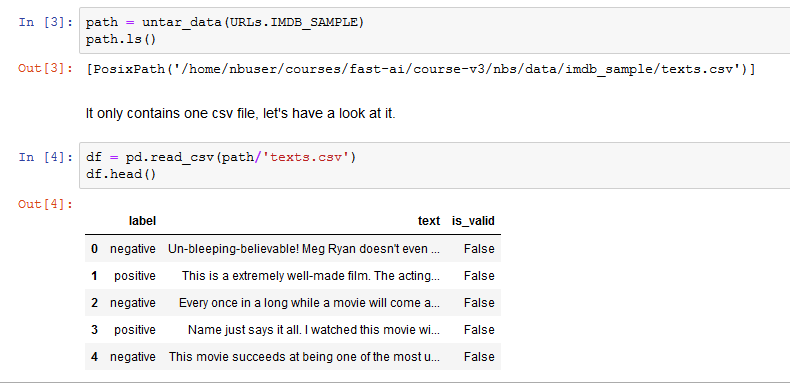
How could we download data text Imdb pls? when i run the code path = untar_data(URLs.IMDB), nothing happens. It didn’t download anything.
what is the output cell when you run the cells. if it looks like here below then everything is good ![]() it’s small dataset or you may have this already downloaded
it’s small dataset or you may have this already downloaded
I tried modifying the MSELossFlat function but still no luck…
class MSELossFlat2(nn.MSELoss):
"Same as `nn.MSELoss`, but flattens input and target."
def forward(self, input:Tensor, target:Tensor) -> Rank0Tensor:
return super().forward(input.view(-1).float(), target.view(-1).float() )
learn = create_cnn(data, models.resnet34)
learn.loss_func = MSELossFlat2()
learn.fit_one_cycle(4)
I now get an input, target mismatch error:
RuntimeError: input and target shapes do not match: input [7040], target [64] at /opt/conda/conda-bld/pytorch-nightly_1540036376816/work/aten/src/THCUNN/generic/MSECriterion.cu:12
The entire unet would output the same size as the input so that the masks can align with the input image. If you are refering to the encoder part of the network, it would be whatever base/backbone network you had passed
Please read the etiquette section of the FAQ.
2 Likes
Hi,
I was trying to train a regression model to determine a person’s age based on image and I’m a bit stuck.
I realize that the create_cnn function has an assertion that regression is not yet implemented but based on the head position example in class, I thought it would be possible to make this work by substituting the loss function with MSELossFlat().
I have trained a model, but I don’t understand what the predictions mean. Am I totally off base? Notebook here.
Thanks for any help!
@ricknta I am also curious about this.
I noticed a relevant stackoverflow item that looks relevant
In the best answer (in my opinion) from user pietz, (s)he writes that training loss > validation loss can happen “when your training loss is calculated as a moving average over 1 epoch, whereas the validation loss is calculated after the learning phase of the same epoch.”
I suspect that is what is happening here.
I hope my answer does not remove this from Jeremy/Rachel’s radar to answer authoritatively, because I could of course be completely wrong.
I tried to look at the code but it’s all in callback.py and their approach is quite foreign to me.
1 Like
Are there any slack study channels or alike going on?
1 Like
Can someone highlight the difference between data.train_ds and data.train_dl functions
for URLs.IMDB_SAMPLE, everything is fine. But in the cell full dataset below URLs.IMDB, nothing happens.
Running path= untar_data(URLs.IMDB) will automatically download full dataset for us, right?
Edit: After looking at the source code, it turns out that the folder imdb in my project is already created. So nothing happens. I have to remove the folder and run it again. It’s fine now.
_ds, return a Dataset, the entire set of data that you can access by index. _dl, returns the DataLoader, a generator that each time returns a batch (chunk of size ‘bs’) of the data. Since datasets are usually very large, dataloaders provide a very efficient way to iterate the data.
5 Likes
Is there any way to do the top n predictions based on probability for a particular image ?
Once you have the predictions, you can try something like output.topk(n, dim=1).
1 Like
In the head-pose notebook I tried to track the MSE manually with this metric:
def mse(pred:Tensor, targ:Tensor)->Rank0Tensor:
return ((targ - pred)**2).mean()
learn = create_cnn(data, models.resnet34, metrics=mse)
learn.loss_func = MSELossFlat()
I would expect the validation loss to be the same as the error rate, but it’s much smaller.
epoch train_loss valid_loss mse
1 0.036152 0.008999 0.011818 (00:53)
2 0.012023 0.010004 0.015681 (00:52)
3 0.004507 0.007254 0.014140 (00:52)
4 0.002694 0.001148 0.007541 (00:51)
5 0.001897 0.001305 0.008124 (00:52)
Why is the validation loss so much smaller?