how do you add bounding boxes to the segmented image?
3 Likes
Which parameters does the learning rate “control” for each epoch? Does it control the random movements in all dimensions of the loss function? I’m having hard time connecting the LR bouncing around to some tangible thing that is helping us get “closer” to our ideal loss function.
As we increase the dimensions, I believe new weights add up. If thats the case, what would be the weight of the added parameters. Will it be the copy of the weight something near, or its a random weight that gets assigned.
Find the place it is decreasing at an increasing rate after the minimum point. i.e one step backward after the minimum point(1e-01). would pick (1e-02)
Delete data sets you not currently using. from previous notebooks
1 Like
Yeah, on my machine, fp16 seems to fail lots of times 
https://forums.fast.ai/t/lesson-3-advanced-discussion/29750/5?u=devforfu
Probably need to update drivers to the most recent versions or something. (The card is 2080).
2 Likes
it is clear now that a gpu with a higher vram is a must. (bs =4, Isnt a good representation of the whole dataset). I would like to know your thoughts on this !
4 Likes
For a dataset very different than imageNet like the satellite images or genomic images mutation points shown in lesson 2, we should use our own stats.
Jeremy once said in the forum:
If you’re using a pretrained model you need to use the same stats it was trained with.
Why it is that? Isn’t it that, normalized dataset with its own stats will have roughly the same distribution like imageNet?
The only thing I can think of, which may differ is skewness:
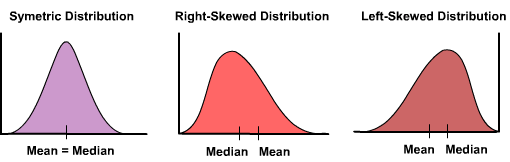
Is it the possibility of skewness or something else the reason of your statement?
And does that mean you don’t recommend using pretrained model with very different dataset like the one-point mutation that you showed us in lesson 2?
or it is okay to use pretrained model for Genomics images, but we should use imageNet stats? However if it is yes, then the dataset will not be normalized well!
14 Likes
In some cases, you may be able to find a closed-form solution to your model (aka, some sort of explicit function). However, when there is a lot of data, even closed-form solutions may involve too much memory - like if you have to invert a huge matrix or such.
In addition to stochastic gradient descent, there are many other descent methods used in unconstrained optimization. These include BFGS, DFP, and Broyden’s method among others. I’d have to refresh myself on how much memory they would use and if that would be suitable for deep learning, though.
1 Like
Thanks @cedric
1 Like
Could Jeremy talk a bit more about literature review and how he decides what new techniques to add to the Fastai library?
4 Likes
I think in deep learning it is usually a scalar that is applied uniformly on all dimensions or parameters. But it is possible to have a separate learning rate along each dimension, but it will be too many hyperparameters to determine so people usually don’t do it. For example, in single layer feed forward networks, this paper shows that using multiple learning factors (one per neuron) helps: http://www.uta.edu/faculty/manry/papers/MOLF_SPIE.pdf
1 Like
what to do with error data/biwi_head_pose/… not found?
How can we update our CUDA driver?
Are ImagePoints the same thing we would use to make bounding boxes?
1 Like
How can we determine which loss function is good for a problem ?
2 Likes
This head pose example definitely will be used sooner or later in military… Imagine a sentry gun with that… Sounds really scary to me.
Download the dataset? There are instructions at the beginning of the notebook.
1 Like
Where should we be monitoring for information about attending part 2, either in person or via livestream?
5 Likes
If we reduce the images to relatively small sizes, like smaller than 120x160, then doesn’t that substantially limit the accuracy of the point location that we infer?
Does this mean that a CNN is not suitable for highly accurately predicting the location of a point in a high resolution image? Or would there be a different approach suitable for higher resolution images?
3 Likes