6 frames
/usr/local/lib/python3.10/dist-packages/fastai/data/core.py in setup(self, train_setup)
395 x = f(x)
396 self.types.append(type(x))
→ 397 types = L(t if is_listy(t) else [t] for t in self.types).concat().unique()
398 self.pretty_types = ‘\n’.join([f’ - {t}’ for t in types])
399
To fix this problem make sure first to use search_images_ddg instead of search_images_bing
Then you must modify the following cells:
results = search_images_ddg('grizzly bear') # search_images_ddg does not need a key
ims = results # we don't need .attrgot('contentUrl') anymore maybe because search_images_ddg returns already an L object
len(ims)
Then you must modify the code that downloads the images
if not path.exists():
path.mkdir()
for o in bear_types:
dest = (path/o)
dest.mkdir(exist_ok=True)
results = search_images_ddg(f'{o} bear') # we change bing to ddg and remove the key
download_images(dest, urls=results) # we remove attrgot('contentUrl')
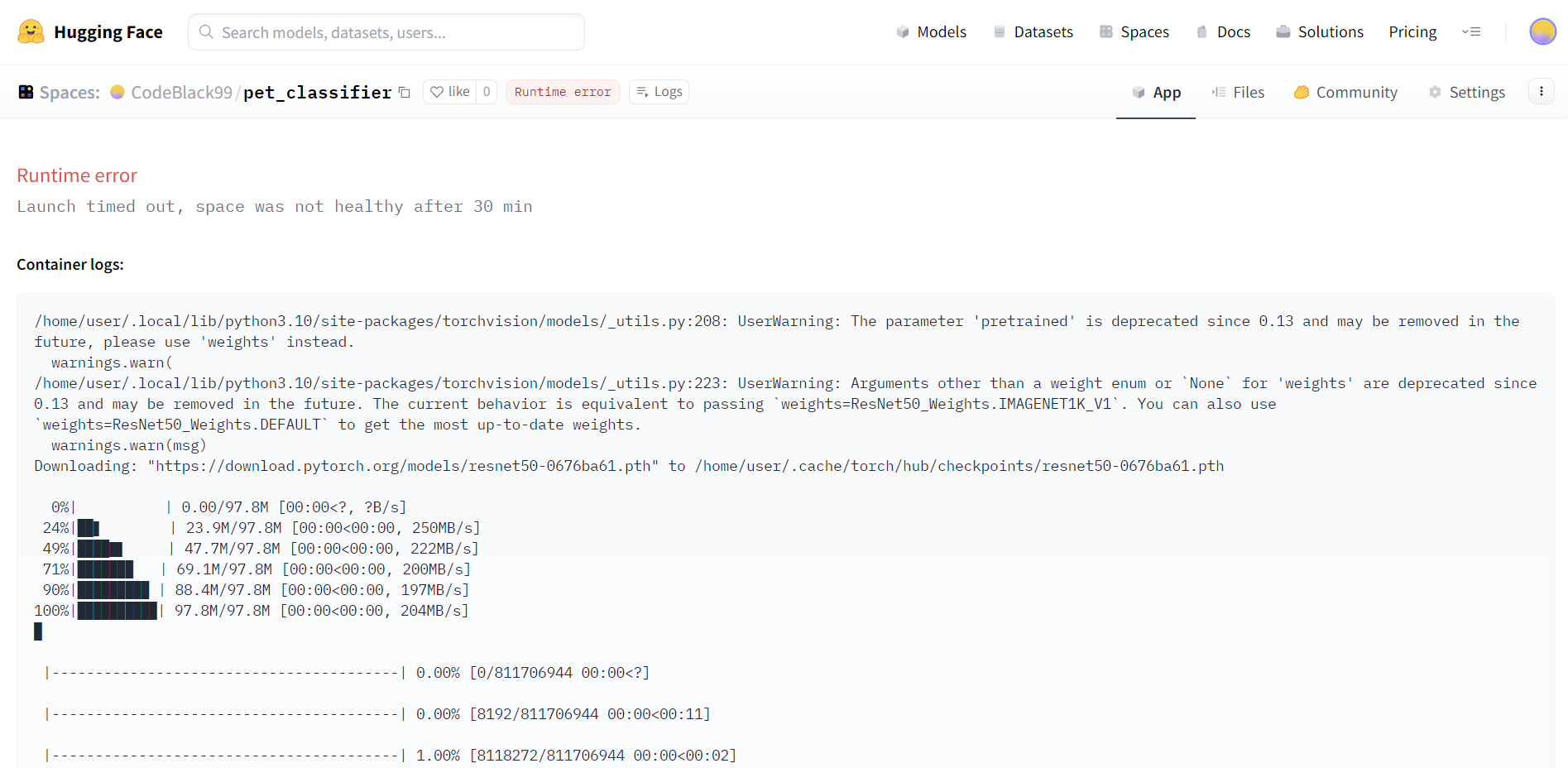
Hi there! Looking for some help with the actual deployment of the model.
In the colab from the book, we train the model, export it, and then import it again all in the same notebook. I’m trying to figure out how to export from one notebook and import it into another. So far, I have exported the model to my Google Drive, but I’m struggling to import it into a different notebook using the load_learner() function.
In simple terms: my goal is to create a notebook in which a user can just insert an image and have it classified. I imagine this can be done by importing the model from a remote place with load_learner() and then following from there. But where can it be stored, and how to correctly import it?
I have exported the model, created the other notebook, and tried to reference the model from the new notebook using load_learner(). It works when I use the Colab directory feature to copy the path that leads to the file, but I noticed this is specifically referencing my personal Drive, which is what the notebook is connected to.
So far, the code looks: bear_classifier = load_learner("/content/gdrive/MyDrive/Colab Notebooks/bears_model.pkl")
The problem is that, if someone else downloads this notebook and tries to run it to classify their own bear image, it won’t work, because load_learner() will try to connect to their Drive and follow the same path (but the model won’t be there).
So my question is: is there any way to make load_learner() load a model based on a URL, so that whenever a third party downloads the notebook to predict an image, it will work?
How about you deploy your model using gradio/huggingface you will have a url that a user can visit and uploads his/her image and get a prediction from your model.
If you still want to do that on colab maybe put your pickle file on your github and try reading from there?
Thank you very much, especially that you sharing your knowledge and time with complete stranger. I will test this and and let you know if worked. all the best.
FileNotFoundError: [Errno 2] No such file or directory: 'images/category1/de9ef62d-c534-4739-b925-fe984e50550b.jpg'
However I can manually find this image in the kaggle directory.
Sometimes also when trying to open the kaggle image directory it gives me this kaggle error. However if I persist and keep clicking it will eventually load
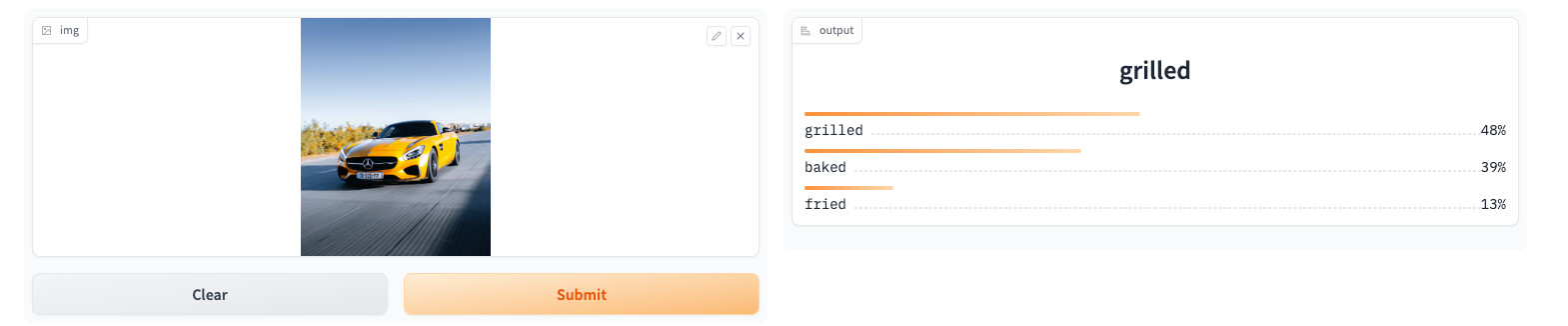
I attempted to make a chicken breast meat analyzer
During the data organization phase, I made the following label directories
chicken_types = 'grilled','baked','fried'
path = Path('chicken-breast')
if not path.exists():
path.mkdir()
for o in chicken_types:
dest = (path/o)
dest.mkdir(exist_ok=True)
results = search_images_bing(secret_value_0, f'{o} chicken breast')
download_images(dest, urls=results.attrgot('contentUrl'))
The filesystem hierarchy matched the array order of chicken_types
When creating the dataBlock, I assumed the get_image_files would load the directories in the order they were defined in the filesystem
I believe the files are read in an alphabetical order. Even when you created the folders in this order ‘grilled’,‘baked’,‘fried’. Once created they will be read [‘baked’, ‘fried’, ‘grilled’]
Files in a folder do not have an order on the disk. The order you typed them in chicken_types does not influence how they appear in storage on the disk.
As another user says, the order is alphabetial. Using dls.vocab is foolproof.
Regarding unrelated images: you have not provided a way for the model to “other”. The prediction probabilities always add to 100%.
Just to mix things up a bit, I made a very short (25 second) youtube video with a demo of the cloud classifier I made: CloudAtlas demo
Trained the model on ten cloud types. Realized how tricky it can be to clean data when 1. you don’t even know the correct labels in the first place (I had to learn my cloud types!) and 2. you are sourcing images from online searches (many incorrect initial labels).
End result does a great job. Does this mean I am a cloud computing expert now…?
I ran into the same issue and Vanessa’s note helps me out.
For whoever that is searching for an answer in this forum for this issue:
The initial error message I got in Kaggle is “Error displaying widget: model not found”. It appears right after I call cleaner().
After adding all the imports @Vanessa mentioned, I started getting “Loading widget”. and the notebook hung there.
After some experiments, I confirmed that it’s not my code’s fault but the kernel that stuck at loading widget. Stop the session and rerun everything solve the issue.
I had the same problem. I already had a directory called ‘bears’ and the first if statement was preventing the rest of the cell from running.
!rm -rf bears
Running that bash command and then rerunning the cell to fetch images worked.
I had an idea while thinking about your 2nd question.
What if we set a confidence threshold for the other labels beyond which it should show the prediction to be “Other” even if one the labels has a higher confidence than the other(s)?
For example, let’s say we are trying to classify two categories of images, say, A and B. If the model predicts the image to be A with 60% confidence, then we throw the “Other” label without any confidence score because we set the threshold to be 60% for any one label.